Hadoop2.5.1集群安装
测试使用3台 reb hat linux 5.4
VM 中安装Linux 计算机名分别为LinuxMain LinuxNode1 LinuxNode2
Hadoop 2.5.1版本
第一步:配置三台linux的IP地址。不懂可以参照下面链接
http://blog.163.com/xiao_long/blog/static/2176511742014928111355143
第二步:修改计算机名
可能有人会问为什么要修改计算机名称,因为每一个登录的时候都是叫localhost这样不方便区分是那台机器
hal/ host.conf hosts hosts.allow hosts.deny [root@linuxmain ~]# vi /etc/hosts # Do not remove the following line, or various programs # that require network functionality will fail. 127.0.0.1 localhost.localdomain localhost ::1 localhost6.localdomain6 localhost6 192.168.1.216 LinuxMain 192.168.1.217 LinuxNode1 192.168.1.218 LinuxNode2 ~ Type :quit<Enter> to exit Vim
把你的集群的所有IP和计算机名称都写在这
完了之后使用
wq! 保存 reboot重新启动
第三步:安装jdk 不会可以参照http://blog.163.com/xiao_long/blog/static/2176511742014101152635471
第四步:解压hadoop 粗体的都是需要配置的
[root@linuxmain usr]# tar -zxvf hadoop-2.5.1.tar.gz [root@linuxmain usr]# cd hadoop/etc/hadoop/ [root@linuxmain hadoop]# [root@linuxmain hadoop]# ls capacity-scheduler.xml httpfs-site.xml configuration.xsl log4j.properties container-executor.cfg mapred-env.cmd core-site.xml mapred-env.sh hadoop-env.cmd mapred-queues.xml.template hadoop-env.sh mapred-site.xml hadoop-metrics2.properties mapred-site.xml.template hadoop-metrics.properties slaves hadoop-policy.xml ssl-client.xml.example hdfs-site.xml ssl-server.xml.example httpfs-env.sh yarn-env.cmd httpfs-log4j.properties yarn-env.sh httpfs-signature.secret yarn-site.xml [root@linuxmain hadoop]#
配置hadoop-env.sh
# set to the root of your Java installation
#你的jdk安装的路径 export JAVA_HOME=/usr/java/latest
# Assuming your installation directory is /usr/local/hadoop
#你的hadoop安装路径 export HADOOP_PREFIX=/usr/local/hadoop
配置yarn-env.sh
# set to the root of your Java installation
#你的jdk安装的路径 export JAVA_HOME=/usr/java/latest
使用source hadoop-env.sh 生效一下 source yarn-env.sh 生效一下
配置core-site.xml
<name>hadoop.tmp.dir</name> <value>/root/hadoop2.5</value> <description>A base for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://LinuxMain:9000</value> <description>hdfs://host:port/</description> </property> <property> <name>io.native.lib.available</name> <value>true</value> <description>Should native hadoop libraries, if present, be used.</description> </property> <property> <name>io.file.buffer.size</name> <value>4096</value> </property>
配置hdfs-site.xml
<property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name</value>
</property> <property> <name>dfs.datanode.data.dir</name> <value>file://${hadoop.tmp.dir}/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>LinuxMain:50090</value> <description> The secondary namenode http server address and port. </description> </property>
<property> <name>dfs.namenode.secondary.https-address</name> <value>LinuxMain:50091</value> <description> The secondary namenode HTTPS server address and port. </description> </property>
<property> <name>dfs.datanode.address</name> <value>LinuxMain:50010</value> <description> The datanode server address and port for data transfer. </description> </property>
<property> <name>dfs.datanode.http.address</name> <value>LinuxMain:50075</value> <description> The datanode http server address and port. </description> </property>
<property> <name>dfs.datanode.ipc.address</name> <value>LinuxMain:50020</value> <description> The datanode ipc server address and port. </description> </property>
配置mapred-site.xml 但是会发现没有这个文件使用命令 cp mapred-site.xml.template mapred-site.xml 重新复制命名一个文件就可以了<property> <name>mapreduce.framework.name</name> <value>yarn</value> <description>The runtime framework for executing MapReduce jobs. Can be one of local, classic or yarn. </description> </property> <!-- jobhistory properties -->
<property> <name>mapreduce.jobhistory.address</name> <value>LinuxMain:10020</value> <description>MapReduce JobHistory Server IPC host:port</description> </property>
<property> <name>mapreduce.jobhistory.webapp.address</name> <value>LinuxMain:19888</value> <description>MapReduce JobHistory Server Web UI host:port</description> </property> <property> <name>mapreduce.jobtracker.http.address</name> <value>LinuxMain:50030</value> <description> The job tracker http server address and port the server will listen on. If the port is 0 then the server will start on a free port. </description> </property>
配置yarn-site.xml<property> <description>the valid service name should only contain a-zA-Z0-9_ and can not start with numbers</description> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <description>The hostname of the RM.</description> <name>yarn.resourcemanager.hostname</name> <value>LinuxMain</value> </property> <property> <description>The address of the applications manager interface in the RM.</description> <name>yarn.resourcemanager.address</name> <value>${yarn.resourcemanager.hostname}:8032</value> </property> <property> <description>The address of the scheduler interface.</description> <name>yarn.resourcemanager.scheduler.address</name> <value>${yarn.resourcemanager.hostname}:8030</value> </property> <property> <description>The address of the RM admin interface.</description> <name>yarn.resourcemanager.admin.address</name> <value>${yarn.resourcemanager.hostname}:8033</value> </property> <property> <description>The http address of the RM web application.</description> <name>yarn.resourcemanager.webapp.address</name> <value>${yarn.resourcemanager.hostname}:8088</value> </property>
<property> <description>The https adddress of the RM web application.</description> <name>yarn.resourcemanager.webapp.https.address</name> <value>${yarn.resourcemanager.hostname}:8090</value> </property>
<property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>${yarn.resourcemanager.hostname}:8031</value> </property>
配置slavesLinuxMain LinuxNode1 LinuxNode2
配置完了之后格式化文件 命令 bin/hdfs namenode -format14/11/26 22:43:26 INFO blockmanagement.BlockManager: encryptDataTransfer = false 14/11/26 22:43:26 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000 14/11/26 22:43:26 INFO namenode.FSNamesystem: fsOwner = root (auth:SIMPLE) 14/11/26 22:43:26 INFO namenode.FSNamesystem: supergroup = supergroup 14/11/26 22:43:26 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0 14/11/26 22:43:26 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000 14/11/26 22:43:26 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 14/11/26 22:43:26 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 14/11/26 22:43:26 INFO util.GSet: Computing capacity for map NameNodeRetryCache 14/11/26 22:43:26 INFO util.GSet: VM type = 32-bit 14/11/26 22:43:26 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB 14/11/26 22:43:26 INFO util.GSet: capacity = 2^16 = 65536 entries 14/11/26 22:43:26 INFO namenode.NNConf: ACLs enabled? false 14/11/26 22:43:26 INFO namenode.NNConf: XAttrs enabled? true 14/11/26 22:43:26 INFO namenode.NNConf: Maximum size of an xattr: 16384 14/11/26 22:43:26 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1894983963-192.168.1.217-1417070606677 14/11/26 22:43:26 INFO common.Storage: Storage directory /root/hadoop2.5/dfs/name has been successfully formatted. 14/11/26 22:43:26 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 14/11/26 22:43:26 INFO util.ExitUtil: Exiting with status 0 14/11/26 22:43:26 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at linuxnode1/192.168.1.217 ************************************************************/
看到这句就成了
接下来复制文件,这是一个比较漫长的过程scp -r hadoop root@linuxnode1:/usr/scp -r hadoop root@linuxnode2:/usr/完了之后再两个节点上也格式化文件系统bin/hdfs namenode -format之后启动sbin/start-all.sh全部启动linuxMain
[root@linuxmain hadoop]# jps 5781 NodeManager 5679 ResourceManager 5506 SecondaryNameNode 5170 NameNode 6222 Jps 5294 DataNode [root@linuxmain hadoop]#
打开浏览器输入 http://192.168.1.216:50070 看看页面能不能出来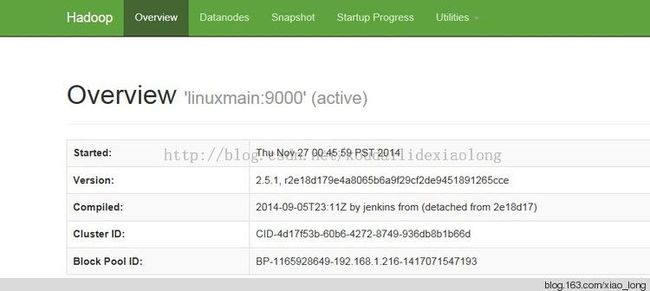 http://192.168.1.216:8088 看看集群节点
http://192.168.1.216:8088 看看集群节点

如果这两个画面都有 那就成了亲测可以运行
hadoop还带了一个单词统计的小例子呢
明天再写吧