memcached源代码分析
目录
本文主要对memcached服务器代码进行分析,这里对各种客户端的实现不做阐述。
原生的memcached是一款基于内存的缓存软件,存储的方式基于k/v.
Memcached的服务器主要依赖libevent库+多线程模型来实现核心逻辑。
为了更好的了解memcached的实现,我们首先需要知道下什么是libevent,它是用来干什么的。
Libevent是一个轻量级的开源高性能网络库, Libevent 有几个显著的亮点:
事件驱动(event-driven),高性能;
轻量级,专注于网络,不如ACE那么臃肿庞大;
源代码相当精炼、易读;
跨平台,支持Windows、Linux、*BSD和Mac Os;
支持多种I/O多路复用技术, epoll、poll、dev/poll、select和kqueue等;
支持I/O,定时器和信号等事件;
注册事件优先级;
Libevent已经被广泛的应用,作为底层的网络库;比如memcached、Vomit、Nylon、Netchat等等。
说了那么多,我们来看一个实际的例子:
int main(int argc, char **argv)
{
...
/* Setup listening socket */
event_set(&ev_accept, listen_fd, EV_READ|EV_PERSIST, on_accept, NULL);
event_add(&ev_accept, NULL);
/* Start the event loop. */
}
以上的例子构建了一个简单服务器。
假如listen_fd有数据可读,那么就会调用on_accept方法。
ev_init用于初始化一个事件环境
event_set和event_add方法分别用于设置和添加事件,event_dispatch则启动当前线程事件监听的主循环。
了解了这个之后,我们再来看一下memcached的多线程服务器模型。

说明:
Mthread:程序启动的主线程
Cthread:用于处理连接请求的分线程
eb:libevent的event_base指针。
Cq:连接队列,每个分线程都拥有一个连接队列。
从图中可以看到,整个服务器处理流程分为以下几个步骤:
1. 主线程建立新的连接,并把连接句柄交给请求队列。
2. 分线程从队列中取出连接数据,并进行处理。
这个地方memcached做了一个优化,因为加入一直没有数据进来,那么cthread就会一直空跑耗费性能,所以这边由管道来实现。
代码如下:
创建管道:
int fds[2];
if (pipe(fds)) {
perror("Can't create notify pipe");
exit(1);
}
threads[i].notify_receive_fd = fds[0];
threads[i].notify_send_fd = fds[1];
线程事件中的逻辑:
if (read(fd, buf, 1) != 1)//假如没有数据则一直阻塞
if (settings.verbose > 0)
fprintf(stderr, "Can't read from libevent pipe\n");
Memcached目前支持2种协议类型,ascii和binary,假如指定协商方式的话,由请求的第一位决定。
if ((unsigned char)c->rbuf[0] == (unsigned char)PROTOCOL_BINARY_REQ) {
c->protocol = binary_prot;
} else {
c->protocol = ascii_prot;
}
1.4.5之前的版本仅对ascii协议完全支持,binary的目前还未完全实现。
下面对协议的处理流程,以及协议的格式做一下阐述。
命令格式:
<command name> <key> <flags> <exptime> <bytes>\r\n
| - <command name> 是 set, add, 或者 repalce |
|
| - <key> 是接下来的客户端所要求储存的数据的键值 |
| - <flags> 是在取回内容时,与数据和发送块一同保存服务器上的任意16位无符号整形(用十进制来书写)。客户端可以用它作为“位域”来存储一些特定的信息;它对服务器是不透明的。 |
| - <exptime> 是终止时间。如果为0,该项永不过期(虽然它可能被删除,以便为其他缓存项目腾出位置)。如果非0(Unix时间戳或当前时刻的秒偏移),到达终止时间后,客户端无法再获得这项内容。 |
| - <bytes> 是随后的数据区块的字节长度,不包括用于分野的“\r\n”。它可以是0(这时后面跟随一个空的数据区块)。 |
|
|
| 在这一行以后,客户端发送数据区块。 |
| - <data block> 是大段的8位数据,其长度由前面的命令行中的<bytes>指定。 |
| 发送命令行和数据区块以后,客户端等待回复,可能的回复如下: |
| 表明成功. |
| 表明数据没有被存储,但不是因为发生错误。这通常意味着add 或 replace命令的条件不成立,或者,项目已经位列删除队列(参考后文的“delete”命令)。 |
整个命令的解析过程是由对conn的状态转变来维护的,conn的状态有以下几种:
enum conn_states {
conn_listening, /**< the socket which listens for connections */
conn_new_cmd, /**< Prepare connection for next command */
conn_waiting, /**< waiting for a readable socket */
conn_read, /**< reading in a command line */
conn_parse_cmd, /**< try to parse a command from the input buffer */
conn_write, /**< writing out a simple response */
conn_nread, /**< reading in a fixed number of bytes */
conn_swallow, /**< swallowing unnecessary bytes w/o storing */
conn_closing, /**< closing this connection */
conn_mwrite, /**< writing out many items sequentially */
conn_max_state /**< Max state value (used for assertion) */
下图以插入数据为例来说明状态的变化:

整个处理过程又一个循环+switch逻辑组成:
while (!stop) {
switch(c->state) {
case conn_listening:
addrlen = sizeof(addr);
if ((sfd = accept(c->sfd, (struct sockaddr *)&addr, &addrlen)) == -1) {
if (errno == EAGAIN || errno == EWOULDBLOCK) {
/* these are transient, so don't log anything */
stop = true;
} else if (errno == EMFILE) {
if (settings.verbose > 0)
fprintf(stderr, "Too many open connections\n");
accept_new_conns(false);
stop = true;
} else {
perror("accept()");
stop = true;
}
break;
}
if ((flags = fcntl(sfd, F_GETFL, 0)) < 0 ||
fcntl(sfd, F_SETFL, flags | O_NONBLOCK) < 0) {
perror("setting O_NONBLOCK");
close(sfd);
break;
}
dispatch_conn_new(sfd, conn_new_cmd, EV_READ | EV_PERSIST,
DATA_BUFFER_SIZE, tcp_transport);
stop = true;
break;
case conn_waiting:
if (!update_event(c, EV_READ | EV_PERSIST)) {
if (settings.verbose > 0)
fprintf(stderr, "Couldn't update event\n");
conn_set_state(c, conn_closing);
break;
}
conn_set_state(c, conn_read);
stop = true;
break;
case conn_read:
res = IS_UDP(c->transport) ? try_read_udp(c) : try_read_network(c);
switch (res) {
case READ_NO_DATA_RECEIVED:
conn_set_state(c, conn_waiting);
break;
case READ_DATA_RECEIVED:
conn_set_state(c, conn_parse_cmd);
break;
case READ_ERROR:
conn_set_state(c, conn_closing);
break;
case READ_MEMORY_ERROR: /* Failed to allocate more memory */
/* State already set by try_read_network */
break;
}
break;
…
…
…
首先我们看图说话:
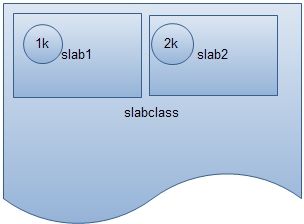
Memcached的内存由一块一块的slabclass组成的。
每个slabclass格式化为200个slab.
每个数据item按照大小匹配存放到slab中。Slab的大小按照factor发生递增。
我们可以看一下它的初始化方法:
if (prealloc) {
/* Allocate everything in a big chunk with malloc */
mem_base = malloc(mem_limit);
if (mem_base != NULL) {
mem_current = mem_base;
mem_avail = mem_limit;
} else {
fprintf(stderr, "Warning: Failed to allocate requested memory in"
" one large chunk.\nWill allocate in smaller chunks\n");
}
}
memset(slabclass, 0, sizeof(slabclass));
while (++i < POWER_LARGEST && size <= settings.item_size_max / factor) {
/* Make sure items are always n-byte aligned */
if (size % CHUNK_ALIGN_BYTES)
size += CHUNK_ALIGN_BYTES - (size % CHUNK_ALIGN_BYTES);
slabclass[i].size = size;
slabclass[i].perslab = settings.item_size_max / slabclass[i].size;
size *= factor;
if (settings.verbose > 1) {
fprintf(stderr, "slab class %3d: chunk size %9u perslab %7u\n",
i, slabclass[i].size, slabclass[i].perslab);
}
}
power_largest = i;
slabclass[power_largest].size = settings.item_size_max;
slabclass[power_largest].perslab = 1;
if (settings.verbose > 1) {
fprintf(stderr, "slab class %3d: chunk size %9u perslab %7u\n",
i, slabclass[i].size, slabclass[i].perslab);
}
五.参考文献
http://www.ibm.com/developerworks/cn/aix/library/au-libev/index.html?ca=drs-