Protocol Buffe高级应用话题
转自:百度空间
到这里为止,我们只给出了一个简单的没有任何用处的例子。在实际应用中,人们往往需要定义更加复杂的 Message。我们用“复杂”这个词,不仅仅是指从个数上说有更多的 fields 或者更多类型的 fields,而是指更加复杂的数据结构:
嵌套 Message
嵌套是一个神奇的概念,一旦拥有嵌套能力,消息的表达能力就会非常强大。
代码清单 4 给出一个嵌套 Message 的例子。
清单 4. 嵌套 Message 的例子
| message Person { required string name = 1; required int32 id = 2; // Unique ID number for this person. optional string email = 3; enum PhoneType { MOBILE = 0; HOME = 1; WORK = 2; } message PhoneNumber { required string number = 1; optional PhoneType type = 2 [default = HOME]; } repeated PhoneNumber phone = 4; } |
在 Message Person 中,定义了嵌套消息 PhoneNumber,并用来定义 Person 消息中的 phone 域。这使得人们可以定义更加复杂的数据结构。
4.1.2 Import Message
在一个 .proto 文件中,还可以用 Import 关键字引入在其他 .proto 文件中定义的消息,这可以称做 Import Message,或者 Dependency Message。
比如下例:
清单 5. 代码
| import common.header; message youMsg{ required common.info_header header = 1; required string youPrivateData = 2; } |
其中 ,common.info_header定义在common.header包内。
Import Message 的用处主要在于提供了方便的代码管理机制,类似 C 语言中的头文件。您可以将一些公用的 Message 定义在一个 package 中,然后在别的 .proto 文件中引入该 package,进而使用其中的消息定义。
Google Protocol Buffer 可以很好地支持嵌套 Message 和引入 Message,从而让定义复杂的数据结构的工作变得非常轻松愉快。
一般情况下,使用 Protobuf 的人们都会先写好 .proto 文件,再用 Protobuf 编译器生成目标语言所需要的源代码文件。将这些生成的代码和应用程序一起编译。
可是在某且情况下,人们无法预先知道 .proto 文件,他们需要动态处理一些未知的 .proto 文件。比如一个通用的消息转发中间件,它不可能预知需要处理怎样的消息。这需要动态编译 .proto 文件,并使用其中的 Message。
Protobuf 提供了 google::protobuf::compiler 包来完成动态编译的功能。主要的类叫做 importer,定义在 importer.h 中。使用 Importer 非常简单,下图展示了与 Import 和其它几个重要的类的关系。
图 2. Importer 类
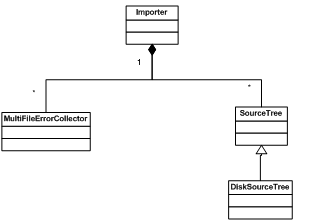
Import 类对象中包含三个主要的对象,分别为处理错误的 MultiFileErrorCollector 类,定义 .proto 文件源目录的 SourceTree 类。
下面还是通过实例说明这些类的关系和使用吧。
对于给定的 proto 文件,比如 lm.helloworld.proto,在程序中动态编译它只需要很少的一些代码。如代码清单 6 所示。
清单 6. 代码
| google::protobuf::compiler::MultiFileErrorCollector errorCollector; google::protobuf::compiler::DiskSourceTree sourceTree; google::protobuf::compiler::Importer importer(&sourceTree, &errorCollector); sourceTree.MapPath("", protosrc); importer.import(“lm.helloworld.proto”); |
首先构造一个 importer 对象。构造函数需要两个入口参数,一个是 source Tree 对象,该对象指定了存放 .proto 文件的源目录。第二个参数是一个 error collector 对象,该对象有一个 AddError 方法,用来处理解析 .proto 文件时遇到的语法错误。
之后,需要动态编译一个 .proto 文件时,只需调用 importer 对象的 import 方法。非常简单。
那么我们如何使用动态编译后的 Message 呢?我们需要首先了解几个其他的类
Package google::protobuf::compiler 中提供了以下几个类,用来表示一个 .proto 文件中定义的 message,以及 Message 中的 field,如图所示。
图 3. 各个 Compiler 类之间的关系
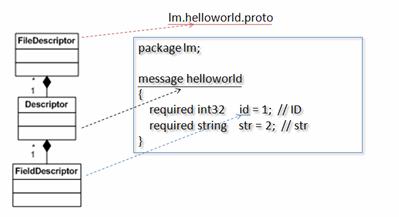
类 FileDescriptor 表示一个编译后的 .proto 文件;类 Descriptor 对应该文件中的一个 Message;类 FieldDescriptor 描述一个 Message 中的一个具体 Field。
比如编译完 lm.helloworld.proto 之后,可以通过如下代码得到 lm.helloworld.id 的定义:
清单 7. 得到 lm.helloworld.id 的定义的代码
| const protobuf::Descriptor *desc = importer_.pool()->FindMessageTypeByName(“lm.helloworld”); const protobuf::FieldDescriptor* field = desc->pool()->FindFileByName (“id”); |
通过 Descriptor,FieldDescriptor 的各种方法和属性,应用程序可以获得各种关于 Message 定义的信息。比如通过 field->name() 得到 field 的名字。这样,您就可以使用一个动态定义的消息了。
随 Google Protocol Buffer 源代码一起发布的编译器 protoc 支持 3 种编程语言:C++,java 和 Python。但使用 Google Protocol Buffer 的 Compiler 包,您可以开发出支持其他语言的新的编译器。
类 CommandLineInterface 封装了 protoc 编译器的前端,包括命令行参数的解析,proto 文件的编译等功能。您所需要做的是实现类 CodeGenerator 的派生类,实现诸如代码生成等后端工作:
程序的大体框架如图所示:
图 4. XML 编译器框图
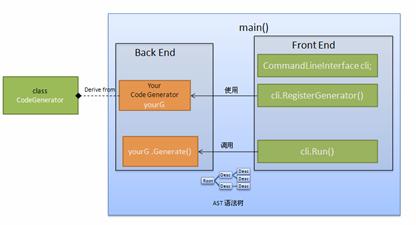
在 main() 函数内,生成 CommandLineInterface 的对象 cli,调用其 RegisterGenerator() 方法将新语言的后端代码生成器 yourG 对象注册给 cli 对象。然后调用 cli 的 Run() 方法即可。
这样生成的编译器和 protoc 的使用方法相同,接受同样的命令行参数,cli 将对用户输入的 .proto 进行词法语法等分析工作,最终生成一个语法树。该树的结构如图所示。
图 5. 语法树
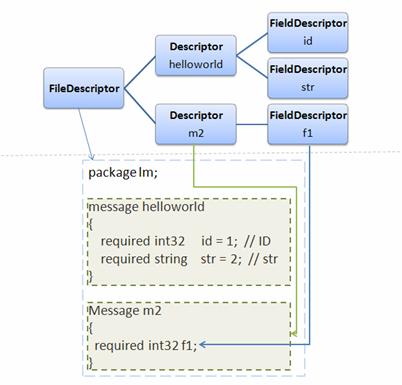
其根节点为一个 FileDescriptor 对象(请参考“动态编译”一节),并作为输入参数被传入 yourG 的 Generator() 方法。在这个方法内,您可以遍历语法树,然后生成对应的您所需要的代码。简单说来,要想实现一个新的 compiler,您只需要写一个 main 函数,和一个实现了方法 Generator() 的派生类即可。
在本文的下载附件中,有一个参考例子,将 .proto 文件编译生成 XML 的 compiler,可以作为参考。
人们一直在强调,同 XML 相比, Protobuf 的主要优点在于性能高。它以高效的二进制方式存储,比 XML 小 3 到 10 倍,快 20 到 100 倍。
对于这些 “小 3 到 10 倍”,“快 20 到 100 倍”的说法,严肃的程序员需要一个解释。因此在本文的最后,让我们稍微深入 Protobuf 的内部实现吧。
有两项技术保证了采用 Protobuf 的程序能获得相对于 XML 极大的性能提高。
第一点,我们可以考察 Protobuf 序列化后的信息内容。您可以看到 Protocol Buffer 信息的表示非常紧凑,这意味着消息的体积减少,自然需要更少的资源。比如网络上传输的字节数更少,需要的 IO 更少等,从而提高性能。
第二点我们需要理解 Protobuf 封解包的大致过程,从而理解为什么会比 XML 快很多。
Google Protocol Buffer 的 Encoding
Protobuf 序列化后所生成的二进制消息非常紧凑,这得益于 Protobuf 采用的非常巧妙的 Encoding 方法。
考察消息结构之前,让我首先要介绍一个叫做 Varint 的术语。
Varint 是一种紧凑的表示数字的方法。它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数。这能减少用来表示数字的字节数。
比如对于 int32 类型的数字,一般需要 4 个 byte 来表示。但是采用 Varint,对于很小的 int32 类型的数字,则可以用 1 个 byte 来表示。当然凡事都有好的也有不好的一面,采用 Varint 表示法,大的数字则需要 5 个 byte 来表示。从统计的角度来说,一般不会所有的消息中的数字都是大数,因此大多数情况下,采用 Varint 后,可以用更少的字节数来表示数字信息。下面就详细介绍一下 Varint。
Varint 中的每个 byte 的最高位 bit 有特殊的含义,如果该位为 1,表示后续的 byte 也是该数字的一部分,如果该位为 0,则结束。其他的 7 个 bit 都用来表示数字。因此小于 128 的数字都可以用一个 byte 表示。大于 128 的数字,比如 300,会用两个字节来表示:1010 1100 0000 0010
下图演示了 Google Protocol Buffer 如何解析两个 bytes。注意到最终计算前将两个 byte 的位置相互交换过一次,这是因为 Google Protocol Buffer 字节序采用 little-endian 的方式。