Heritrix抓取hexun网上的stock信息
使用Heritrix抓取必须的三个文件order.xml,seeds.txt和state.job
之前使用的是ui配置order.xml,现在已经能抓取自己想要的文件了,就直接把order.xml拿来用修改一下就可以了,order.xml代码如下
seeds.txt里的内容为http://stock.hexun.com/
state.job里的内容为
状态一定要位Pending,才能抓取。
启动类MainHeritrix
扩展类FrontierSchedulerforHexunStockNews
代码:
注意这个类还要在conf文件夹下的modules下的Processor.option里配置过
启动Main类就可以进行抓取了
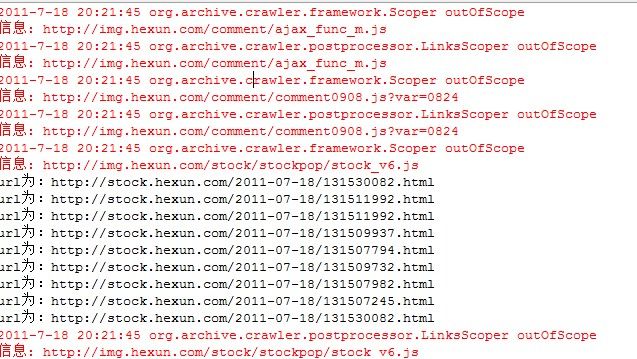
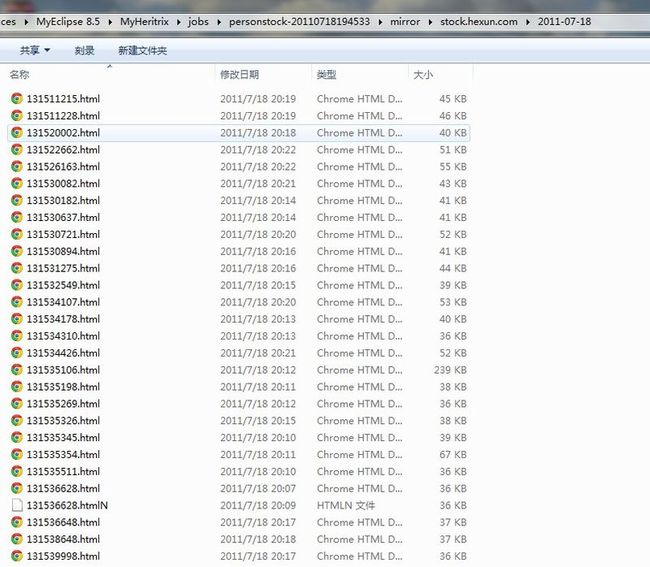
之前使用的是ui配置order.xml,现在已经能抓取自己想要的文件了,就直接把order.xml拿来用修改一下就可以了,order.xml代码如下
<?xml version="1.0" encoding="UTF-8"?><crawl-order xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="heritrix_settings.xsd">
<meta>
<name>personstock</name>
<description>hexunstockInformation</description>
<operator>Admin</operator>
<organization/>
<audience/>
<date>20110718194533</date>
</meta>
<controller>
<string name="settings-directory">settings</string>
<string name="disk-path"/>
<string name="logs-path">logs</string>
<string name="checkpoints-path">checkpoints</string>
<string name="state-path">state</string>
<string name="scratch-path">scratch</string>
<long name="max-bytes-download">0</long>
<long name="max-document-download">0</long>
<long name="max-time-sec">0</long>
<integer name="max-toe-threads">50</integer>
<integer name="recorder-out-buffer-bytes">4096</integer>
<integer name="recorder-in-buffer-bytes">65536</integer>
<integer name="bdb-cache-percent">0</integer>
<newObject name="scope" class="org.archive.crawler.deciderules.DecidingScope">
<boolean name="enabled">true</boolean>
<string name="seedsfile">seeds.txt</string>
<boolean name="reread-seeds-on-config">true</boolean>
<newObject name="decide-rules" class="org.archive.crawler.deciderules.DecideRuleSequence">
<map name="rules">
<newObject name="rejectByDefault" class="org.archive.crawler.deciderules.RejectDecideRule">
</newObject>
<newObject name="acceptIfSurtPrefixed" class="org.archive.crawler.deciderules.SurtPrefixedDecideRule">
<string name="decision">ACCEPT</string>
<string name="surts-source-file"/>
<boolean name="seeds-as-surt-prefixes">true</boolean>
<string name="surts-dump-file"/>
<boolean name="also-check-via">false</boolean>
<boolean name="rebuild-on-reconfig">true</boolean>
</newObject>
<newObject name="rejectIfTooManyHops" class="org.archive.crawler.deciderules.TooManyHopsDecideRule">
<integer name="max-hops">20</integer>
</newObject>
<newObject name="rejectIfPathological" class="org.archive.crawler.deciderules.PathologicalPathDecideRule">
<integer name="max-repetitions">2</integer>
</newObject>
<newObject name="rejectIfTooManyPathSegs" class="org.archive.crawler.deciderules.TooManyPathSegmentsDecideRule">
<integer name="max-path-depth">20</integer>
</newObject>
<newObject name="acceptIfPrerequisite" class="org.archive.crawler.deciderules.PrerequisiteAcceptDecideRule">
</newObject>
</map>
</newObject>
</newObject>
<map name="http-headers">
<string name="user-agent">Mozilla/5.0 (compatible; heritrix/1.14.4 +http://192.168.111.200)</string>
<string name="from">[email protected]</string>
</map>
<newObject name="robots-honoring-policy" class="org.archive.crawler.datamodel.RobotsHonoringPolicy">
<string name="type">classic</string>
<boolean name="masquerade">false</boolean>
<text name="custom-robots"/>
<stringList name="user-agents">
</stringList>
</newObject>
<newObject name="frontier" class="org.archive.crawler.frontier.BdbFrontier">
<float name="delay-factor">4.0</float>
<integer name="max-delay-ms">20000</integer>
<integer name="min-delay-ms">2000</integer>
<integer name="respect-crawl-delay-up-to-secs">300</integer>
<integer name="max-retries">30</integer>
<long name="retry-delay-seconds">900</long>
<integer name="preference-embed-hops">1</integer>
<integer name="total-bandwidth-usage-KB-sec">0</integer>
<integer name="max-per-host-bandwidth-usage-KB-sec">0</integer>
<string name="queue-assignment-policy">org.archive.crawler.frontier.HostnameQueueAssignmentPolicy</string>
<string name="force-queue-assignment"/>
<boolean name="pause-at-start">false</boolean>
<boolean name="pause-at-finish">false</boolean>
<boolean name="source-tag-seeds">false</boolean>
<boolean name="recovery-log-enabled">true</boolean>
<boolean name="hold-queues">true</boolean>
<integer name="balance-replenish-amount">3000</integer>
<integer name="error-penalty-amount">100</integer>
<long name="queue-total-budget">-1</long>
<string name="cost-policy">org.archive.crawler.frontier.ZeroCostAssignmentPolicy</string>
<long name="snooze-deactivate-ms">300000</long>
<integer name="target-ready-backlog">50</integer>
<string name="uri-included-structure">org.archive.crawler.util.BdbUriUniqFilter</string>
<boolean name="dump-pending-at-close">false</boolean>
</newObject>
<map name="uri-canonicalization-rules">
<newObject name="Lowercase" class="org.archive.crawler.url.canonicalize.LowercaseRule">
<boolean name="enabled">true</boolean>
</newObject>
<newObject name="Userinfo" class="org.archive.crawler.url.canonicalize.StripUserinfoRule">
<boolean name="enabled">true</boolean>
</newObject>
<newObject name="WWW[0-9]*" class="org.archive.crawler.url.canonicalize.StripWWWNRule">
<boolean name="enabled">true</boolean>
</newObject>
<newObject name="SessionIDs" class="org.archive.crawler.url.canonicalize.StripSessionIDs">
<boolean name="enabled">true</boolean>
</newObject>
<newObject name="SessionCFIDs" class="org.archive.crawler.url.canonicalize.StripSessionCFIDs">
<boolean name="enabled">true</boolean>
</newObject>
<newObject name="QueryStrPrefix" class="org.archive.crawler.url.canonicalize.FixupQueryStr">
<boolean name="enabled">true</boolean>
</newObject>
</map>
<map name="pre-fetch-processors">
<newObject name="Preselector" class="org.archive.crawler.prefetch.Preselector">
<boolean name="enabled">true</boolean>
<newObject name="Preselector#decide-rules" class="org.archive.crawler.deciderules.DecideRuleSequence">
<map name="rules">
</map>
</newObject>
<boolean name="override-logger">false</boolean>
<boolean name="recheck-scope">true</boolean>
<boolean name="block-all">false</boolean>
<string name="block-by-regexp"/>
<string name="allow-by-regexp"/>
</newObject>
<newObject name="Preprocessor" class="org.archive.crawler.prefetch.PreconditionEnforcer">
<boolean name="enabled">true</boolean>
<newObject name="Preprocessor#decide-rules" class="org.archive.crawler.deciderules.DecideRuleSequence">
<map name="rules">
</map>
</newObject>
<integer name="ip-validity-duration-seconds">21600</integer>
<integer name="robot-validity-duration-seconds">86400</integer>
<boolean name="calculate-robots-only">false</boolean>
</newObject>
</map>
<map name="fetch-processors">
<newObject name="DNS" class="org.archive.crawler.fetcher.FetchDNS">
<boolean name="enabled">true</boolean>
<newObject name="DNS#decide-rules" class="org.archive.crawler.deciderules.DecideRuleSequence">
<map name="rules">
</map>
</newObject>
<boolean name="accept-non-dns-resolves">false</boolean>
<boolean name="digest-content">true</boolean>
<string name="digest-algorithm">sha1</string>
</newObject>
<newObject name="HTTP" class="org.archive.crawler.fetcher.FetchHTTP">
<boolean name="enabled">true</boolean>
<newObject name="HTTP#decide-rules" class="org.archive.crawler.deciderules.DecideRuleSequence">
<map name="rules">
</map>
</newObject>
<newObject name="midfetch-decide-rules" class="org.archive.crawler.deciderules.DecideRuleSequence">
<map name="rules">
</map>
</newObject>
<integer name="timeout-seconds">1200</integer>
<integer name="sotimeout-ms">20000</integer>
<integer name="fetch-bandwidth">0</integer>
<long name="max-length-bytes">0</long>
<boolean name="ignore-cookies">false</boolean>
<boolean name="use-bdb-for-cookies">true</boolean>
<string name="load-cookies-from-file"/>
<string name="save-cookies-to-file"/>
<string name="trust-level">open</string>
<stringList name="accept-headers">
</stringList>
<string name="http-proxy-host"/>
<string name="http-proxy-port"/>
<string name="default-encoding">ISO-8859-1</string>
<boolean name="digest-content">true</boolean>
<string name="digest-algorithm">sha1</string>
<boolean name="send-if-modified-since">true</boolean>
<boolean name="send-if-none-match">true</boolean>
<boolean name="send-connection-close">true</boolean>
<boolean name="send-referer">true</boolean>
<boolean name="send-range">false</boolean>
<string name="http-bind-address"/>
</newObject>
</map>
<map name="extract-processors">
<newObject name="ExtractorHTTP" class="org.archive.crawler.extractor.ExtractorHTTP">
<boolean name="enabled">true</boolean>
<newObject name="ExtractorHTTP#decide-rules" class="org.archive.crawler.deciderules.DecideRuleSequence">
<map name="rules">
</map>
</newObject>
</newObject>
<newObject name="ExtractorHTML" class="org.archive.crawler.extractor.ExtractorHTML">
<boolean name="enabled">true</boolean>
<newObject name="ExtractorHTML#decide-rules" class="org.archive.crawler.deciderules.DecideRuleSequence">
<map name="rules">
</map>
</newObject>
<boolean name="extract-javascript">true</boolean>
<boolean name="treat-frames-as-embed-links">true</boolean>
<boolean name="ignore-form-action-urls">false</boolean>
<boolean name="extract-only-form-gets">true</boolean>
<boolean name="extract-value-attributes">true</boolean>
<boolean name="ignore-unexpected-html">true</boolean>
</newObject>
<newObject name="ExtractorCSS" class="org.archive.crawler.extractor.ExtractorCSS">
<boolean name="enabled">true</boolean>
<newObject name="ExtractorCSS#decide-rules" class="org.archive.crawler.deciderules.DecideRuleSequence">
<map name="rules">
</map>
</newObject>
</newObject>
<newObject name="ExtractorJS" class="org.archive.crawler.extractor.ExtractorJS">
<boolean name="enabled">true</boolean>
<newObject name="ExtractorJS#decide-rules" class="org.archive.crawler.deciderules.DecideRuleSequence">
<map name="rules">
</map>
</newObject>
</newObject>
<newObject name="ExtractorSWF" class="org.archive.crawler.extractor.ExtractorSWF">
<boolean name="enabled">true</boolean>
<newObject name="ExtractorSWF#decide-rules" class="org.archive.crawler.deciderules.DecideRuleSequence">
<map name="rules">
</map>
</newObject>
</newObject>
</map>
<map name="write-processors">
<newObject name="MirrorWriter" class="org.archive.crawler.writer.MirrorWriterProcessor">
<boolean name="enabled">true</boolean>
<newObject name="MirrorWriter#decide-rules" class="org.archive.crawler.deciderules.DecideRuleSequence">
<map name="rules">
</map>
</newObject>
<boolean name="case-sensitive">true</boolean>
<stringList name="character-map">
</stringList>
<stringList name="content-type-map">
</stringList>
<string name="directory-file">index.html</string>
<string name="dot-begin">%2E</string>
<string name="dot-end">.</string>
<stringList name="host-map">
</stringList>
<boolean name="host-directory">true</boolean>
<string name="path">mirror</string>
<integer name="max-path-length">1023</integer>
<integer name="max-segment-length">255</integer>
<boolean name="port-directory">false</boolean>
<boolean name="suffix-at-end">true</boolean>
<string name="too-long-directory">LONG</string>
<stringList name="underscore-set">
</stringList>
</newObject>
</map>
<map name="post-processors">
<newObject name="Updater" class="org.archive.crawler.postprocessor.CrawlStateUpdater">
<boolean name="enabled">true</boolean>
<newObject name="Updater#decide-rules" class="org.archive.crawler.deciderules.DecideRuleSequence">
<map name="rules">
</map>
</newObject>
</newObject>
<newObject name="LinksScoper" class="org.archive.crawler.postprocessor.LinksScoper">
<boolean name="enabled">true</boolean>
<newObject name="LinksScoper#decide-rules" class="org.archive.crawler.deciderules.DecideRuleSequence">
<map name="rules">
</map>
</newObject>
<boolean name="override-logger">false</boolean>
<boolean name="seed-redirects-new-seed">true</boolean>
<integer name="preference-depth-hops">-1</integer>
<newObject name="scope-rejected-url-rules" class="org.archive.crawler.deciderules.DecideRuleSequence">
<map name="rules">
</map>
</newObject>
</newObject>
<newObject name="FrontierSchedulerForHexunStockNews" class="my.FrontierSchedulerForHexunStockNews">
<boolean name="enabled">true</boolean>
<newObject name="FrontierSchedulerForHexunStockNews#decide-rules" class="org.archive.crawler.deciderules.DecideRuleSequence">
<map name="rules">
</map>
</newObject>
</newObject>
</map>
<map name="loggers">
<newObject name="crawl-statistics" class="org.archive.crawler.admin.StatisticsTracker">
<integer name="interval-seconds">20</integer>
</newObject>
</map>
<string name="recover-path"/>
<boolean name="checkpoint-copy-bdbje-logs">true</boolean>
<boolean name="recover-retain-failures">false</boolean>
<boolean name="recover-scope-includes">true</boolean>
<boolean name="recover-scope-enqueues">true</boolean>
<newObject name="credential-store" class="org.archive.crawler.datamodel.CredentialStore">
<map name="credentials">
</map>
</newObject>
</controller>
</crawl-order>
seeds.txt里的内容为http://stock.hexun.com/
state.job里的内容为
20110718194533 hexunstock Pending false true 2 0 order.xml
状态一定要位Pending,才能抓取。
启动类MainHeritrix
package my;
import java.io.File;
import javax.management.InvalidAttributeValueException;
import org.archive.crawler.event.CrawlStatusListener;
import org.archive.crawler.framework.CrawlController;
import org.archive.crawler.framework.exceptions.InitializationException;
import org.archive.crawler.settings.XMLSettingsHandler;
public class MainHeritrix
{
public static void main(String[] args)
{
String orderFile = "D:\\Workspaces\\MyEclipse 8.5\\MyHeritrix\\jobs\\personstock-20110718194533\\order.xml";
File file = null;
XMLSettingsHandler handler = null;
CrawlStatusListener listerner = null;
CrawlController controller = null;
try {
file = new File(orderFile);
handler = new XMLSettingsHandler(file);
handler.initialize();
controller = new CrawlController();
controller.initialize(handler);
if(listerner != null)
{
controller.addCrawlStatusListener(listerner);
}
controller.requestCrawlStart();
while(true)
{
if(controller.isRunning() == false)
{
break;
}
Thread.sleep(1000);
System.out.println("The current thread is:"+Thread.currentThread());
}
//controller.requestCrawlStop();
} catch (InvalidAttributeValueException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InitializationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
扩展类FrontierSchedulerforHexunStockNews
代码:
package my;
import java.util.logging.Logger;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.archive.crawler.datamodel.CandidateURI;
import org.archive.crawler.postprocessor.FrontierScheduler;
public class FrontierSchedulerForHexunStockNews extends FrontierScheduler {
private static Logger logger = Logger.getLogger(FrontierSchedulerForHexunStockNews.class.getName());
private static Pattern pattern ;
private static String regex = "http://stock.hexun.com/[\\d]+-[\\d]+-\\d+/[\\d]+.html";
private static String regexStock="stock.hexun.com";
private static String regexStockDns="dns:stock.hexun.com";
private static String regexReal="stock.hexun.com/real/"; //个股主页面
public FrontierSchedulerForHexunStockNews(String name) {
super(name);
// TODO Auto-generated constructor stub
}
static {
}
/**
*
*/
private static final long serialVersionUID = 1L;
protected void schedule(CandidateURI cdUri)
{
String url = cdUri.toString();
//Matcher m = null;
try {
// m = pattern.matcher(url);
/*if(url.indexOf("dns:") !=-1
||url.indexOf("robots.txt") !=-1
||url.indexOf(regexReal) != -1
||url.indexOf(regexStock) != -1
)url.startsWith(regexStock)||||url.equals(regexStockDns)
{*/
if(url.matches(regex)||url.indexOf("dns:stock.hexun.com") !=-1|| url.indexOf("robots.txt") !=-1)
{
System.out.println("url为:"+url);
getController().getFrontier().schedule(cdUri);
}
/*if(url.indexOf("stock.hexun.com") != -1||url.indexOf("dns:stock.hexun.com") !=-1|| url.indexOf("robots.txt") !=-1)
{
getController().getFrontier().schedule(cdUri);
}*/
else
{
return;
}
/* if(url.indexOf("stock.hexun.com") != -1||url.indexOf("dns:") !=-1|| url.indexOf("robots.txt") !=-1)
{
getController().getFrontier().schedule(cdUri);
}
else
{
return;
}
*/
} catch (Exception e) {
logger.info(e.getMessage());
}
}
}
注意这个类还要在conf文件夹下的modules下的Processor.option里配置过
启动Main类就可以进行抓取了