什么是filtercache?
solr应用中为了提高查询速度有可以利用几种cache来优化查询速度,分别是fieldValueCache,queryResultCache,documentCache,filtercache,在日常使用中最为立竿见影,最有效的应属filtercache,何谓filtercache?这个需要从一段solr的查询日志开始说起,下面是我截取的solr运行中打印的一段查询日志:
[search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A2+AND+class_id%3A1&sort=index_sort_order+desc&start=0&rows=5,queryTime_is ==> 2 [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A1+AND+class_id%3A1+AND+%28group_id%3A411%29&sort=gmt_create+desc&start=0&rows=20,queryTime_is ==> 2 [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A2+AND+class_id%3A1&sort=index_sort_order+desc&start=0&rows=5,queryTime_is ==> 2 [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A1+AND+class_id%3A1+AND+%28group_id%3A8059%29&sort=gmt_create+desc&start=0&rows=20,queryTime_is ==> 0 [search4alive-0] Request_is ==> debugQuery=on&group=true&group.field=group_id&group.ngroups=true&group.sort=gmt_create+desc&q=status%3A0++AND+biz_type%3A1+AND+class_id%3A1+AND+ha [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A2+AND+class_id%3A1&sort=index_sort_order+desc&start=30&rows=30,queryTime_is ==> 4 [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A2+AND+class_id%3A1&sort=index_sort_order+desc&start=0&rows=5,queryTime_is ==> 1 [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A1+AND+class_id%3A1+AND+%28group_id%3A375%29&sort=gmt_create+desc&start=0&rows=20,queryTime_is ==> 3 [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A2+AND+class_id%3A1&sort=index_sort_order+desc&start=0&rows=5,queryTime_is ==> 1 [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A2+AND+class_id%3A1&sort=index_sort_order+desc&start=0&rows=30,queryTime_is ==> 4 [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A2+AND+class_id%3A1&sort=index_sort_order+desc&start=0&rows=5,queryTime_is ==> 1 [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A2+AND+class_id%3A1&sort=index_sort_order+desc&start=0&rows=30,queryTime_is ==> 4 [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A2+AND+class_id%3A1&sort=index_sort_order+desc&start=0&rows=30,queryTime_is ==> 3
看到这段查询日志之后,我们开始考虑如何提升查询的rt(查询速度),因为在参数q中的查询是要有磁盘IO开销的,很自然的思路是将整个查询的参数q作为key,对应的结果作为value,这样做是可以的,但是查询的命中率会很低,会占用大量内存空间。
查询参数q上基本上每次都会出现status,biz_type,class_id 对于这样的字查询,所以可以把整个查询条件分成两部分一部分是以status,biz_type,class_id 这几个条件组成的子查询条件,另外一部分是除这三个条件之外的子查询。在进程查询的时候,先将status,biz_type,class_id 条件组成的条件作为key,对应的结果作为value进行缓存,然后再和另外一部分查询的结果进行求交运算。
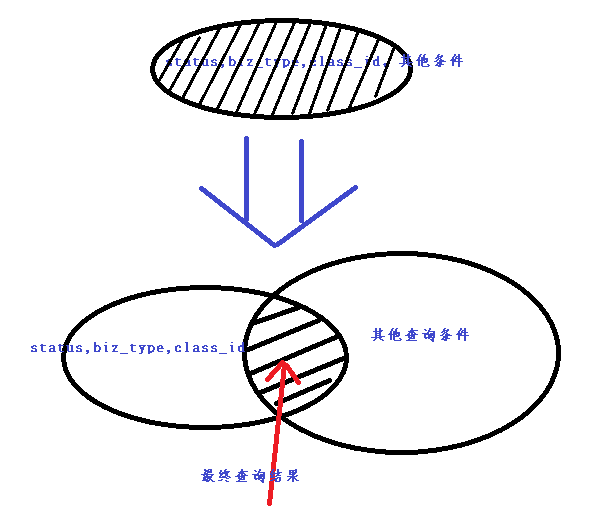 |
通过上面这幅图明白了filtercache的意义是,将原先一个普通查询分割成两个组合查询的与运算,两个子查询至少有一个使用缓存,这样既减少了查询过程的IO操作,又控制了缓存的容量不会消耗过多的内存。
如何使用?
首先要配置solrconfig.xml 要开启fltercache:
- <query>
- <filterCache class="solr.LRUCache" size="50000" initialSize="512" autowarmCount="0"/>
- </query>
这里使用的是solr实现的基于LRU算法的缓实现,以上配置是使用solr.LRUCache ,使用这个cache在插入多,查询少的情况比较使用,如果是查询多,插入少的情况,可以使用solr.FastLRUCache缓存模块。
客户端API调用:
下面是原先的客户端端查询代码:
- SolrQuery query = new SolrQuery();
- query.setQuery("status:0 AND biz_type:1 AND class_id:1 AND xxx:123");
- QueryResponse response = qyeryServer.query(query);
使用filterQuery之后的查询代码:
- SolrQuery query = new SolrQuery();
- query.addFilterQuery("status:0 AND biz_type:1 AND class_id:1");
- query.setQuery("xxx:123");
- QueryResponse response = qyeryServer.query(query);
经过测试这样优化之后,查询的RT会明显减小,QPS会有明显提升。
使用filterquery过程中需要注意点:
●不能在filterQuery 上重复出现query中的查询参数,如果上面的filterquery调用方法如下所示:
- query.addFilterQuery("status:0 AND biz_type:1 AND class_id:1 AND xxx:123");
- query.setQuery("xxx:123");
如上,条件xxx:123 在filterQuery和query上都出现了,这样的写法非但起不到查询优化的目的,而且还会增加查询的性能开销。
●尽量减少调用addFilterQuery方法的次数
- query.addFilterQuery("status:0 ");
- query.addFilterQuery("biz_type:1 ");
- query.addFilterQuery("class_id:1 ");
- query.setQuery("xxx:123");
如上,将status:0 AND biz_type:1 AND class_id:1 这个组合查询条件,分三次调用filterQuery方法来完成,这样的调用方法虽然是正确的,并且能起到性能优化的效果,优化性能没有调用一次addFilterQuery方法来得高,原因是多调用了两次addFilterQuery,就意味着最后需要多进行两次结果集的求交运算,虽然结果集求交运算速度很快,但毕竟是有性能损耗的。
不过从内存开销的角度来说,调用三次addfilterQuery方法这样可以有效降低内存的使用量,这个是肯定的。所以在是否调用多次addFilterQuery方法的原则是,在内存开销允许的前提下,将量将所有filterQuery条件,通过调用有限次数的addFilterQuery方法来完成。