1.数据完整性
检测数据的常用措施:在数据第一次引入系统时计算校验和,读取时再次计算校验和然后进行比较,常用的错误检测码是CRC-32。
注:校验和也是可能损坏的,但是校验和比数据小得多,所以损坏的可能性很小。
1)HDFS的数据完整性
HDFS会对写入的所有数据计算校验和,并在读取数据时验证校验和。默认针对每512个字节的数据计算校验和。
core-site.xml
<property> <name>io.bytes.per.checksum</name> <value>512</value> <description>The number of bytes per checksum. Must not be larger than io.file.buffer.size.</description> </property>
每个datanode均持久保存一个用于验证的校验和日志。
并且每个datanode会在后台线程中运行一个DataBlockScanner定期验证存储在这个datanode上的所有数据块。
假如发现错误,可以通过复制完好的数据复本来修复损坏的数据块,进而得到一个新的,完好无损的复本。
--禁用
FileSystem.setVerifyChecksum(false);
2)LocalFileSystem extends ChecksumFileSystem
执行客户端的校验和验证。意味着在写入一个名为filename的文件时,文件系统客户端会明确地在包含每个文件块校验和的同一个目录内新建一个名为.filename.crc的隐藏文件。和HDFS一样,文件块的大小由io.bytes.per.checksum控制。
--禁用
使用RawLocalFileSystem替代LocalFileSystem
core-site.xml
<property> <name>fs.file.impl</name> <value>org.apache.hadoop.fs.LocalFileSystem</value> <description>The FileSystem for file: uris.</description> </property>
2.压缩
好处:减少存储文件所需要的磁盘空间,加速数据在网络和磁盘上的传输。
1)hadoop常见压缩方法列表:
注:没有可用于生产DEFLATE文件的常用命令行工具,因为通常都用gzip格式。
注:gzip文件格式只是在DEFLATE格式上增加了一个文件头和一个文件尾。
所有压缩算法都需要权衡空间/时间。表中所有的压缩工具都提供9个不同的选项来控制压缩时必须考虑的权衡:-1为优化压缩速度,-9为优化压缩空间。
压缩速度比较:bzip2 < gzip < lzo
压缩效率比较:lzo < gzip < bizp2
是否可拆分:表示该压缩算法是否支持切分,即是否可以搜素数据流的任意位置并进一步往下读取数据。可切分压缩格式尤其适合MapReduce。
举个例子,一个未压缩的文件有1GB大小,hdfs默认的block大小是64MB,那么这个文件就会被分为16个block作为mapreduce的输入,每一个单独使用一个map任务。如果这个文件是已经使用gzip压缩的呢,如果分成16个块,每个块做成一个输入,显然是不合适的,因为gzip压缩流的随即读是不可能的。实际上,当mapreduce处理压缩格式的文件的时候它会认识到这是一个gzip的压缩文件,而gzip又不支持随即读,它就会把16个块分给一个map去处理,这里就会有很多非本地处理的map任务,整个过程耗费的时间就会相当长。
2)codec
--codec实现了一种压缩/解压缩算法。在hadoop中,一个对ComppressionCodec接口的实现代表一种codec。
Hadoop常见压缩方法的codec
e.g.
package com.siyuan.hadoop.test.codec;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.util.Arrays;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionInputStream;
import org.apache.hadoop.io.compress.CompressionOutputStream;
public class CodecTest {
public static void main(String[] args) throws IOException {
String compressStr = "HELLO HADOOP";
System.out.println("Before compression ...");
System.out.println(Arrays.toString(compressStr.getBytes()));
CompressionOutputStream compressOuput = null;
CompressionInputStream compressInput = null;
try {
CompressionCodec codec = new BZip2Codec();
// 压缩
ByteArrayOutputStream output = new ByteArrayOutputStream();
compressOuput = codec.createOutputStream(output);
compressOuput.write(compressStr.getBytes());
System.out.println("Afer compression ...");
System.out.println(Arrays.toString(output.toByteArray()));
//解压缩
ByteArrayInputStream input = new ByteArrayInputStream(output.toByteArray());
compressInput = codec.createInputStream(input);
byte[] buffer = new byte[1024];
compressInput.read(buffer);
System.out.println("Afer decompression ...");
System.out.println(Arrays.toString(buffer));
} finally {
IOUtils.closeQuietly(compressOuput);
IOUtils.closeQuietly(compressInput);
}
}
}
运行结果:
Before compression ... [72, 69, 76, 76, 79, 32, 72, 65, 68, 79, 79, 80] Afer compression ... [66, 90, 104] Exception in thread "main" java.io.IOException: Stream is not BZip2 formatted: illegal blocksize ? at org.apache.hadoop.io.compress.bzip2.CBZip2InputStream.init(CBZip2InputStream.java:474) at org.apache.hadoop.io.compress.bzip2.CBZip2InputStream.<init>(CBZip2InputStream.java:291) at org.apache.hadoop.io.compress.BZip2Codec$BZip2CompressionInputStream.<init>(BZip2Codec.java:334) at org.apache.hadoop.io.compress.BZip2Codec$BZip2CompressionInputStream.<init>(BZip2Codec.java:320) at org.apache.hadoop.io.compress.BZip2Codec.createInputStream(BZip2Codec.java:107) at com.siyuan.hadoop.test.codec.CodecTest.main(CodecTest.java:34)解压缩的时候报错了,之后尝试将压缩结果输出到本地文件,然后通过工具打开可以正常显示,但是通过压缩文件输入到codec进行解压时仍然报这个错误,百思不得其解,百度和谷歌也没帮到我,暂且搁置~~~~
--ComprssionCodecFactory
ComprssionCodecFactory提供了一个方法可以将文件扩展名映射到一个CompressionCodec,该方法获取文件的Path对象作为参数。
ComprssionCodecFactory会从io.compression.codecs属性定义的一个列表中找到codec。
因为ComppressionCodec接口中有一个getDefaultExtension方法。
core-site.xml
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec</value>
<description>A list of the compression codec classes that can be used
for compression/decompression.</description>
</property>
3)hadoop中使用压缩
--输入数据文件:通过ComprssionCodecFactory获取对应的codec自动解压
--map输出
JobConf.setCompressMapOutput(...)
JobConf.setMapOutputCompressorClass(...)
mapred-site.xml
<property>
<name>mapred.compress.map.output</name>
<value>false</value>
<description>Should the outputs of the maps be compressed before being
sent across the network. Uses SequenceFile compression.
</description>
</property>
<property>
<name>mapred.map.output.compression.codec</name>
<value>org.apache.hadoop.io.compress.DefaultCodec</value>
<description>If the map outputs are compressed, how should they be
compressed?
</description>
</property>
--reduce输出
mapred-site.xml
<property> <name>mapred.output.compress</name> <value>false</value> <description>Should the job outputs be compressed? </description> </property> <property> <name>mapred.output.compression.codec</name> <value>org.apache.hadoop.io.compress.DefaultCodec</value> <description>If the job outputs are compressed, how should they be compressed? </description> </property>
4)压缩算法的选择
通常情况下,在为应用选择压缩算法时,需要构建一套测试基准,通过尝试不同的策略,从而找到最理想的压缩格式。
例如:对于巨大的,无存储边界的文件,可以考虑如下选项:
--存储未经压缩的文件
--使用支持切分的压缩格式
--先分块后压缩
--使用顺序文件
--使用Avro数据文件
3.序列化
序列化:将结构化对象转化为字节流
反序列化:将字节流转化为结构化对象
主要用途:进程间通信,永久存储
在Hadoop中,系列中多个节点上进程间的通信是通过RPC实现的。RPC对序列化格式的要求有:
--紧凑:充分利用网络带宽
--快速:尽量减少序列化和反序列化的性能开销
--可扩展:可满足新的需求而不断变化
--互操作:能支持以不同语言写的客户端与服务器交互
1)Writable
Writable是Hadoop自己的序列化格式,它格式紧凑,速度快,但很难用Java以外的语言进行扩展和使用。
public interface Writable {
//序列化
void write(DataOutput out) throws IOException;
//反序列化
void readFields(DataInput in) throws IOException;
}
由于MapReduce中间有个基于键的排序阶段,所以类型的比较是非常重要的,所以务必要实现comparable方法,这里通过实现WritableComparable完成。
public interface WritableComparable<T> extends Writable, Comparable<T> {
} 为了优化排序,Hadoop提供了一个继承自Comprator的RawComparator接口,该接口允许实现直接比较数据流中的记录,而无需先把数据流反序列化为对象,这样避免了新建对象的额外开销。
public interface RawComparator<T> extends Comparator<T> {
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
} WritableComparator extends RawComparator,主要功能有
--提供了对原始compare方法的一个默认实现,该方法能够反序列化将在流中进行比较的对象,并调用对象的compare方法。
--它充当的是RawComparator实例的工厂(public static synchronized WritableComparator get(Class<? extends WritableComparable> c))。
Hadoop中的Writable类层次结构
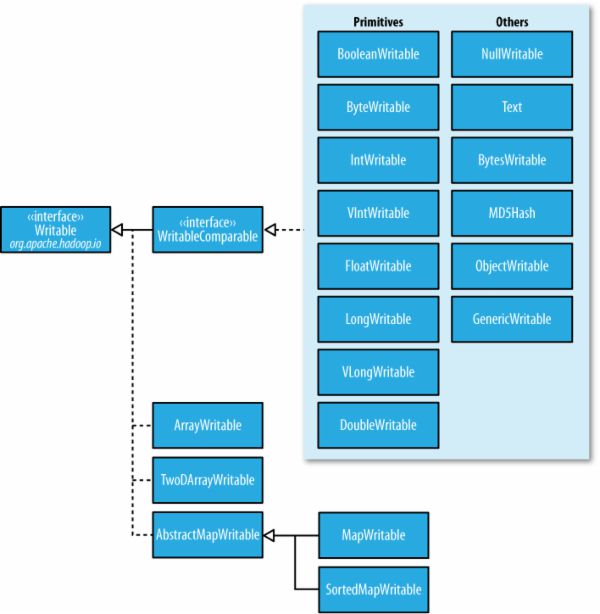
它们可分为:
--Java基本类型的Writable封装器
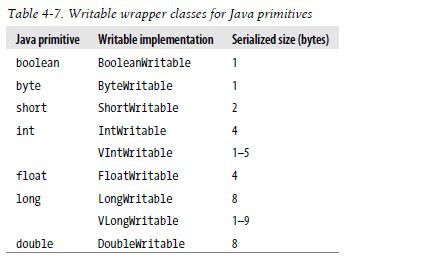
short和char可以存储在IntWritable中,每个类都提供get/set方法。我们以IntWritable的使用为例来了解系列化和反序列化的过程,以及比较的实现。e.g.
package com.siyuan.hadoop.test.writable;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.RawComparator;
import org.apache.hadoop.io.WritableComparator;
public class IntWritableTest {
public static void main(String[] args) throws IOException {
DataOutputStream dataOut = null;
DataInputStream dataIn = null;
DataOutputStream dataOut2 = null;
try {
//序列化
IntWritable num1 = new IntWritable();
num1.set(125);
ByteArrayOutputStream byteOut = new ByteArrayOutputStream();
dataOut = new DataOutputStream(byteOut);
num1.write(dataOut);
//反序列化
ByteArrayInputStream byteIn = new ByteArrayInputStream(byteOut.toByteArray());
dataIn = new DataInputStream(byteIn);
num1.readFields(dataIn);
System.out.println(num1.get());
//比较WritableComparable
IntWritable num2 = new IntWritable();
num2.set(126);
System.out.println(num1.compareTo(num2));
//比较RawComparator
@SuppressWarnings("unchecked")
RawComparator<IntWritable> intWritableComparator = WritableComparator.get(IntWritable.class);
System.out.println(intWritableComparator.compare(num1, num2));
ByteArrayOutputStream byteOut2 = new ByteArrayOutputStream();
dataOut2 = new DataOutputStream(byteOut2);
num2.write(dataOut2);
byte[] b1 = byteOut.toByteArray();
byte[] b2 = byteOut2.toByteArray();
System.out.println(intWritableComparator.compare(b1, 0, b1.length, b2, 0, b2.length));
} finally {
IOUtils.closeQuietly(dataOut);
IOUtils.closeQuietly(dataIn);
IOUtils.closeQuietly(dataOut2);
}
}
} --Text
Text是针对UTF-8序列的Writable类。一般可以认为它等价于String的Writable。
Text取代了UTF8类,一来它不支持对字节数超过32767的字符串进行编码,二者它使用的是JAVA的UTF-8修订版。
————索引:对Text类的索引是根据编码后字节序列中的位置实现,并非字符串中的Unicode字符,也不是Java Char的编码单元(如String)。
————Unicode:一旦开始使用需要多个字节编码的字符的时候,Text和String之间的区别就很明显的了,下面程序测试Text和String的不同:
public void teststring() throws UnsupportedEncodingException {
String s = "\u0041\u00DF\u6771\uD801\uDC00";
assertEquals(s.length(), 5);
assertEquals(s.getBytes("UTF-8").length, 10);
assertEquals(s.indexOf("\u0041"), 0);
assertEquals(s.indexOf("\u00DF"), 1);
assertEquals(s.indexOf("\u6771"), 2);
assertEquals(s.indexOf("\uD801\uDC00"), 3);
assertEquals(s.charAt(0), '\u0041');
assertEquals(s.charAt(1), '\u00DF');
assertEquals(s.charAt(2), '\u6771');
assertEquals(s.charAt(3), '\uD801');
assertEquals(s.charAt(4), '\uDC00');
assertEquals(s.codePointAt(0), 0x0041);
assertEquals(s.codePointAt(1), 0x00DF);
assertEquals(s.codePointAt(2), 0x6771);
assertEquals(s.codePointAt(3), 0x10400);
}
public void testText() {
Text t = new Text("\u0041\u00DF\u6771\uD801\uDC00");
assertEquals(t.getLength(), 10); //字节数
assertEquals(t.find("\u0041"), 0);
assertEquals(t.find("\u00DF"), 1);
assertEquals(t.find("\u6771"), 3); //3:字节偏移量
assertEquals(t.find("\uD801\uDC00"), 6);
assertEquals(t.charAt(0), 0x0041);
assertEquals(t.charAt(1), 0x00DF);
assertEquals(t.charAt(3), 0x6771); //3:字节偏移量
assertEquals(t.charAt(6), 0x10400);
}
————迭代:将Text对象变成java.nio.ByteBuffer,然后利用缓冲的Text反复调用bytesToCodePoint()静态方法。该方法能够获取下一个代码的的位置,并返回相应的int值,最后更新缓冲区的位置。当bytesToCodePoint()返回-1时,检测到字符串结束。
public class TextIterator {
public static void main(String[] args) {
Text t = new Text("\u0041\u00DF\u6771\uD801\uDC00");
ByteBuffer buf = ByteBuffer.wrap(t.getBytes(), 0, t.getLength());
int cp;
while (buf.hasRemaining() && (cp = Text.bytesToCodePoint(buf)) != -1) {
System.out.println(Integer.toHexString(cp));
}
}
}
————易变性:可以通过调用其中一个set()方法来重用Text实例
public void testChangable() {
Text text = new Text();
text.set("hello,hadoop");
text.set("test");
//之前书上说改变值后getBytes和getLength结果可能不一致,但是实际还是一致的
assertEquals(text.getBytes().length, 4);
assertEquals(text.getLength(), 4);
} ————转换为String,Text并不像String那样有丰富的字符串操作API,所以多数情况下,需要将Text对象转成String对象,可通过toString方法实现。
--BytesWritable
BytesWritable是对二进制数据数组的封装。它的序列化格式为一个用于指定后面数据字节数的整数域(4字节),后跟字节本身。
--NullWritable
一个特殊的Writable类型。它的序列化长度为0,它并不从数据流中读取数据,也不写入数据。它充当占位符;例如,在MapReduce中,如果不需要使用键或值,就可以将键或值声明为NullWritable——结果是存储常量控制。它是一个不可变的单实例类型:通过调用NullWritable.get()方法可以获取这个实例。
--ObjectWritable和GenericWritable
ObjectWritable是对java基本类型(string、enum、writable、null或这些类型组成的数组)的一个通用封装,它在Hadoop RPC中用于对方法的参数和返回类型进行封装和解封装。作为一个通用机制,每次序列化都封装类型的名称,这非常浪费空间。
如果封装的类型数量比较少并且能够提前知道,那么可以通过使用静态类型的数组,并使用对序列化后的类型的引用加入位置索引提高性能。这是 GenericWritable 类型采取的方法,并且你可以在继承子类中指定需要支持的类型 。
--Writable集合类
Hadoop有四种Writable集合类,分别是ArrayWritable,TwoDArrayWritable,MapperWritable和SortedMapWritable。
————ArrayWritable,TwoDArrayWritable是对Writable的数组和两维数组的实现,它们中的所有元素必须是同一类的Writable实例,类型必须在构造函数中指定。
使用:在MapReduce框架中使用时需要通过继承它并在默认构造函数中指定它的元素类型,因为MapReduce实例化的时候是使用默认构造函数。
————MapWritable和SortedMapWritable分别是java.util.Map<Writable, Writable>和java.util.SortedMap<WritableComparable,Writable>的实例。每个键/值字段的类型都是此字段序列化格式的一部分。类型存储为单个字节(类型数组的索引)。
————可以通过Writable集合类来实现集合(Set)和列表(List)。
--自定义Writable
————implements WritableComparable
提供一个默认的构造函数,MapReduce框架实例化使用
Writable实例具有易变性并且通常可以重用,所以尽量避免在write()和readFiedls()函数中分配对象
重写hashcode和equals方法,以供MapReduce中默认的分区类HashPartitioner使用
重写toString方法,TextOutputFormat对键和值调用该方法从而将键和值转换为相应的输出
————为速度实现一个RawComparator
编写Comparator需要谨慎,因为必须要处理字节级别的细节,编写时有必要参考io包中对Writable接口的实现,并且尽量使用WritableUtils中的方法。e.g.
TextPair.java
package com.siyuan.hadoop.test.writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.io.WritableUtils;
public class TextPair implements WritableComparable<TextPair> {
private Text first;
private Text second;
public TextPair() {
first = new Text();
second = new Text();
}
public TextPair(String first, String second) {
set(new Text(first), new Text(second));
}
public TextPair(Text first, Text second) {
set(first, second);
}
public void set(String first, String second) {
this.first.set(first);
this.second.set(second);
}
public void set(Text first, Text second) {
this.first = first;
this.second = second;
}
public Text getFirst() {
return first;
}
public Text getSecond() {
return second;
}
@Override
public void write(DataOutput out) throws IOException {
first.write(out);
second.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
first.readFields(in);
second.readFields(in);
}
@Override
public int compareTo(TextPair tp) {
int rs = this.first.compareTo(tp.getFirst());
if (rs == 0) {
rs = this.second.compareTo(tp.getSecond());
}
return rs;
}
@Override
public boolean equals(Object obj) {
if (obj instanceof TextPair) {
TextPair tp = (TextPair) obj;
return this.first.equals(tp.getFirst())
&& this.second.equals(tp.getSecond());
}
return false;
}
@Override
public int hashCode() {
return first.hashCode() * 163 + second.hashCode();
}
@Override
public String toString() {
return first + "\t" + second;
}
//注册到工厂类中 -- 不能写在静态类中,会注册失败
static {
WritableComparator.define(TextPair.class, new Comparator());
}
//RawComparator
public static class Comparator extends WritableComparator {
private WritableComparator textComparator = WritableComparator.get(Text.class);
protected Comparator() {
super(TextPair.class);
}
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
//Text序列化的二进制包含UTF-8的字节数以及UTF-8字节本身
int firstL1 = WritableUtils.decodeVIntSize(b1[s1]) + readVInt(b1, s1);
int firstL2 = WritableUtils.decodeVIntSize(b1[s2]) + readVInt(b2, s2);
int rs = textComparator.compare(b1, s1, firstL1, b2, s2, firstL2);
if (rs != 0) {
return rs;
}
return textComparator.compare(b1, s1 + firstL1, l1 - firstL1, b2, s2 + firstL2, l2 - firstL2);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return super.compare(b1, s1, l1, b2, s2, l2);
}
}
}
TextPairTest.java
package com.siyuan.hadoop.test.writable;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.io.WritableComparator;
public class TextPairTest {
public static void main(String[] args) throws IOException {
DataOutputStream dataOut = null;
DataInputStream dataIn = null;
DataOutputStream dataOut2 = null;
try {
//序列化
TextPair tp = new TextPair();
tp.set("name", "test");
System.out.println("序列化前-----------");
System.out.println(tp);
ByteArrayOutputStream byteOut = new ByteArrayOutputStream();
dataOut = new DataOutputStream(byteOut);
tp.write(dataOut);
//反序列化
ByteArrayInputStream byteIn = new ByteArrayInputStream(byteOut.toByteArray());
dataIn = new DataInputStream(byteIn);
TextPair tp2 = new TextPair();
tp2.readFields(dataIn);
System.out.println("序列化后-----------");
System.out.println(tp2);
//比较
System.out.println(tp.equals(tp2));
System.out.println(tp.compareTo(tp2));
//RawCompartor
byte[] b = byteOut.toByteArray();
ByteArrayOutputStream byteOut2 = new ByteArrayOutputStream();
dataOut2 = new DataOutputStream(byteOut2);
tp2.write(dataOut2);
byte[] b2 = byteOut2.toByteArray();
System.out.println(WritableComparator.get(TextPair.class).compare(b, 0, b.length, b2, 0, b2.length));
} finally {
IOUtils.closeQuietly(dataOut);
IOUtils.closeQuietly(dataIn);
IOUtils.closeQuietly(dataOut2);
}
}
}
2)序列化框架
Hadoop中的序列化并非强制使用Writable,它只是默认值。
为了支持这一机制,Hadoop有一个针对可替换的序列化框架的API,一个序列化框架用一个org.apache.hadoop.io.serializer.Serialization<T>的实现表示。
core-site.xml
<property> <name>io.serializations</name> <value>org.apache.hadoop.io.serializer.WritableSerialization</value> <description>A list of serialization classes that can be used for obtaining serializers and deserializers.</description> </property>Hadoop提供了两种Serialization的实现,JavaSerialization, WritableSerialization。
--序列化IDL
IDL(Interface Description Language)接口定义语言,以不依赖于具体语言的方式进行声明,也可以用来实现序列化。
比较有名的序列化框架有Apache Thrift,Protocal Buffers,Apache Avro。
5.顺序文件
SequenceFile类提供了二进制键/值对的永久存储的数据结构。它非常适合记录二进制类型,同样也可以作为小文件的容器。而HDFS和MapReduce是针对大文件进行优化的,所以通过SequenceFile类型将小文件包装起来,可以获得更高效的存储和处理。
1)格式
顺序文件的格式是由文件头和随后的一条或多条记录组成。顺序文件的前三个字节为SEQ(顺序文件代码),紧随其后的是一个字节表示顺序文件的版本号。文件头还包括其他一些字段,包括键和值相应类的名称,数据压缩细节,用户定义的元数据,以及同步标识。同步标识主要用于读取文件的时候能够从任意位置开始识别记录便捷。每个文件有随机生成的同步标识,该标识内容存储在文件头中,同步标识位于顺序文件中的记录与记录之间。同步标识的额外存储开销要求小于1%,所以没有必要再每条记录末尾添加该标识。
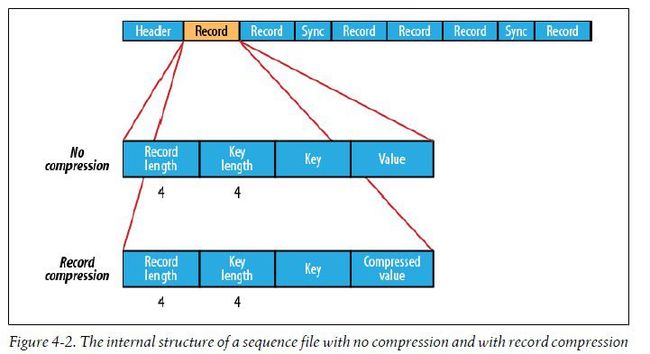
记录的内部结构与是否启用压缩有关。如果启用,则与是记录压缩还是数据块压缩有关。
如果没有启用压缩(默认情况),那么每条记录有记录长度(字节数),键长度,键和值组成。长度字段为4字节长的整数,并且需要遵循java.io.DataOutput类中writeInt()方法的协定。通过为数据写入顺序文件而定义的Serialization类,可以实现对键和值的序列化。
记录压缩的格式与无压缩情况相同,只不过值需要通过文件头中定义的压缩codec进行压缩。注意,键是不会压缩的。
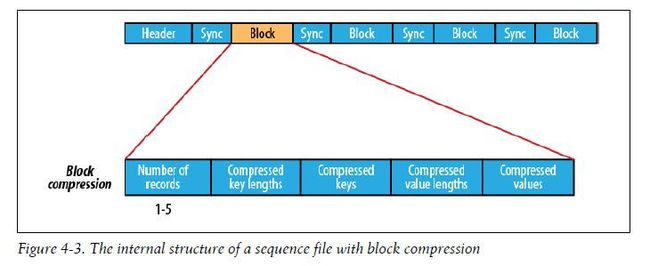
块压缩一次对多个记录进行压缩,因此相对于单条记录压缩,也所效率会更高,因为可以利用记录件的相似性进行压缩。新块的开始处都需要出入同步标识,设置块的大小
core-site.xml
<property>
<name>io.seqfile.compress.blocksize</name>
<value>1000000</value>
<description>The minimum block size for compression in block compressed
SequenceFiles.
</description>
</property>
当MapReduce输出结果为SequenceFile时设置压缩类型
mapred-site.xml
<property>
<name>mapred.output.compression.type</name>
<value>RECORD</value>
<description>If the job outputs are to compressed as SequenceFiles, how should
they be compressed? Should be one of NONE, RECORD or BLOCK.
</description>
</property>
2)写入
通过creatWriter()静态方法可以创建SequenceFile对象,并返回SequenceFile.Writer实例。该静态方法有多个重载版本,但都需要指定待写入的数据流(FSDataOutputStream或FileSystem或Path),Configuration对象,以及键和值的类型。另外可选参数包括压缩类型以及相应的codec,Progressable回调函数用于通知写入的进度,以及在SequenceFile头文件中存储的Metadata实例。
存储在SequenceFile中的键和值并不一定需要Writable类型,任何可以通过Serialization类实现序列化和反序列化的类型均可以。
一旦拥有SequenceFile.Writer实例,就可以通过append()方法在文件末尾附加键/值。写完后调用close()。
并且可以通过sync方法写入同步点。
public void testWrite() throws IOException, URISyntaxException {
SequenceFile.Writer writer = null;
try {
Configuration conf = new Configuration();
writer = SequenceFile.createWriter(
FileSystem.get(new URI("file:///"), conf),
conf,
new Path("E:/Hadoop/testfiles/test.seq"),
IntWritable.class,
Text.class);
IntWritable key = new IntWritable();
Text value = new Text();
for (int i = 0; i < 1000; i++) {
key.set(i);
value.set("路人甲" + i);
writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}
}
3)读取
从头到尾读取顺序文件的过程是创建SequenceFile.Reader实例后反复调用next()方法迭代读取记录的过程。读取的是哪条记录与你使用的序列化框架相关。如果你使用的是Writable类型,那么通过键和值作为参数的next()方法可以将数据流中的下一条键值对读入变量中,如果读取成功则返回true,如果以读到文件尾则返回false。
public boolean next(Writable key, Writable val);
如果读取非Writable类型的序列化框架,则需要使用
public Object next( Object key ) throws IOException; public Object getCurrentValue(Object val) throws IOException;
这种情况下请确保在io.serializations属性已经设置了你想使用的序列化框架。如果next()方法返回非空对象,则可以从数据流中读取键值对,并且可以通过getCurrentValue()方法读取该值。否则返回null表示到文件尾。
--随机访问
void seek(long position)此方法可以读取文件的给定位置,但是如果给的位置不是记录的边界,则会报错。
public void sync(long position)
此方法则为读取position之后的下一个同步点。
public void testRead() throws IOException, URISyntaxException {
Configuration conf = new Configuration();
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(
FileSystem.get(new URI("file:///"), conf),
new Path("E:/Hadoop/testfiles/test.seq"),
conf);
IntWritable key = new IntWritable();
Text value = new Text();
long position = reader.getPosition();
String syncStr = "";
while (reader.next(key, value)) {
//当前位置是否为同步点
syncStr = reader.syncSeen() ? "*" : "";
System.out.printf("[%s%s]%s\t%s\n", position, syncStr, key, value);
position = reader.getPosition();
}
//seek
reader.seek(192);
reader.next(key, value);
syncStr = reader.syncSeen() ? "*" : "";
System.out.printf("[%s%s]%s\t%s\n", position, syncStr, key, value);
//sync
reader.sync(192);
reader.next(key, value);
syncStr = reader.syncSeen() ? "*" : "";
System.out.printf("[%s%s]%s\t%s\n", position, syncStr, key, value);
} finally {
IOUtils.closeStream(reader);
}
}
4)排序和合并
使用SequeceFile.Sorter类中的sort和merge方法实现。该方法比Hadoop的MapReduce工具出现得更早,并且提供的功能更底层,所以更常用。
5)工具
Hadoop提供了工具来实现SequeceFile文件的查看,排序和合并
6.MapFile
MapFile是已经排序的SequenceFile,它已加入用于搜索键的索引。可以将MapFile视为java.util.Map的持久化形式。
1)写入
MapFile写入类似于SequenceFile的写入。
区别:
--键必须是WritableComparable类型的实例,值必须是Writable类型的实例
--写入时必须按顺序写入,否则会报错
2)原理
MapFile实际上是一个包含data和index两个文件的文件夹,两个文件都是SequenceFile。
data文件包含所有记录。
index文件包含一部分键和data文件中键偏移量的映射。
调整索引中的间隔数:
--MapFile.Writer.setIndexInterval()
--io.map.index.interval属性
3)读取
在MapFile文件依次遍历所有条目的过程类似SequenceFile中的过程:先建立MapFile.Reader实例,然后调用next()方法,直到返回值为false。
boolean next(WritableComparable key, Writable val)
通过调用get或者getClost方法可以随机访问文件中的数据。
Writable get(WritableComparable key, Writable val) WritableComparable getClosest(WritableComparable key, Writable val); WritableComparable getClosest(WritableComparable key, Writable val, boolean before);
随机访问时需要将index文件读入内存中,可以通过设置来加载一部分索引键。
mapred-site.xml
<property> <name>io.map.index.skip</name> <value>0</value> <description>Number of index entries to skip between each entry. Zero by default. Setting this to values larger than zero can facilitate opening large map files using less memory.</description> </property>
4)将SequenceFile转化为MapFile
--将*.seq排序后,保存到一个*.map文件夹中
--将该文件重命名为data
--建立index文件
7.参考资料
Hadoop权威指南
http://www.cnblogs.com/biyeymyhjob/archive/2012/08/10/2630484.html