细说HBase怎么完成一个Get操作 (client side)
源码解析基于HBase-0.20.6。
先看HTable类get()方法的code:
HTable.java
/**
* Extracts certain cells from a given row.
* @param get The object that specifies what data to fetch and from which row.
* @return The data coming from the specified row, if it exists. If the row
* specified doesn't exist, the {@link Result} instance returned won't
* contain any {@link KeyValue}, as indicated by {@link Result#isEmpty()}.
* @throws IOException if a remote or network exception occurs.
* @since 0.20.0
*/
public Result get(final Get get) throws IOException {
return connection.getRegionServerWithRetries(
new ServerCallable<Result>(connection, tableName, get.getRow()) {
public Result call() throws IOException {
return server.get(location.getRegionInfo().getRegionName(), get);
}
}
);
}
这段code 比较绕,但至少我们知道可以去查connection的getRegionServerWithRetries方法。那么connection是个什么东西呢?
这个玩意是定义在HTable里面的:
private final HConnection connection;
何时实例化的呢?在HTable的构造函数里面:
this.connection = HConnectionManager.getConnection(conf);
这个conf是一个HBaseConfiguration对象,是HTable构造函数的参数。OK,继续道HConnectionManager里面看看这个connection怎么来的吧:
HConnectionManager.java
/**
* Get the connection object for the instance specified by the configuration
* If no current connection exists, create a new connection for that instance
* @param conf
* @return HConnection object for the instance specified by the configuration
*/
public static HConnection getConnection(HBaseConfiguration conf) {
TableServers connection;
synchronized (HBASE_INSTANCES) {
connection = HBASE_INSTANCES.get(conf);
if (connection == null) {
connection = new TableServers(conf);
HBASE_INSTANCES.put(conf, connection);
}
}
return connection;
}
现在我们知道每一个conf对应一个connection,具体来说是TableServers类对象(实现了HConnection接口),所有的connections放在一个pool里。那么connection到底干嘛用呢?我们要看看HConnection这个接口的定义。
HConnection.java
/**
* Cluster connection.
* {@link HConnectionManager} manages instances of this class.
*/
public interface HConnection {
/**
* Retrieve ZooKeeperWrapper used by the connection.
* @return ZooKeeperWrapper handle being used by the connection.
* @throws IOException
*/
public ZooKeeperWrapper getZooKeeperWrapper() throws IOException;
/**
* @return proxy connection to master server for this instance
* @throws MasterNotRunningException
*/
public HMasterInterface getMaster() throws MasterNotRunningException;
/** @return - true if the master server is running */
public boolean isMasterRunning();
/**
* Checks if <code>tableName</code> exists.
* @param tableName Table to check.
* @return True if table exists already.
* @throws MasterNotRunningException
*/
public boolean tableExists(final byte [] tableName)
throws MasterNotRunningException;
/**
* A table that isTableEnabled == false and isTableDisabled == false
* is possible. This happens when a table has a lot of regions
* that must be processed.
* @param tableName
* @return true if the table is enabled, false otherwise
* @throws IOException
*/
public boolean isTableEnabled(byte[] tableName) throws IOException;
/**
* @param tableName
* @return true if the table is disabled, false otherwise
* @throws IOException
*/
public boolean isTableDisabled(byte[] tableName) throws IOException;
/**
* @param tableName
* @return true if all regions of the table are available, false otherwise
* @throws IOException
*/
public boolean isTableAvailable(byte[] tableName) throws IOException;
/**
* List all the userspace tables. In other words, scan the META table.
*
* If we wanted this to be really fast, we could implement a special
* catalog table that just contains table names and their descriptors.
* Right now, it only exists as part of the META table's region info.
*
* @return - returns an array of HTableDescriptors
* @throws IOException
*/
public HTableDescriptor[] listTables() throws IOException;
/**
* @param tableName
* @return table metadata
* @throws IOException
*/
public HTableDescriptor getHTableDescriptor(byte[] tableName)
throws IOException;
/**
* Find the location of the region of <i>tableName</i> that <i>row</i>
* lives in.
* @param tableName name of the table <i>row</i> is in
* @param row row key you're trying to find the region of
* @return HRegionLocation that describes where to find the reigon in
* question
* @throws IOException
*/
public HRegionLocation locateRegion(final byte [] tableName,
final byte [] row)
throws IOException;
/**
* Find the location of the region of <i>tableName</i> that <i>row</i>
* lives in, ignoring any value that might be in the cache.
* @param tableName name of the table <i>row</i> is in
* @param row row key you're trying to find the region of
* @return HRegionLocation that describes where to find the reigon in
* question
* @throws IOException
*/
public HRegionLocation relocateRegion(final byte [] tableName,
final byte [] row)
throws IOException;
/**
* Establishes a connection to the region server at the specified address.
* @param regionServer - the server to connect to
* @return proxy for HRegionServer
* @throws IOException
*/
public HRegionInterface getHRegionConnection(HServerAddress regionServer)
throws IOException;
/**
* Establishes a connection to the region server at the specified address.
* @param regionServer - the server to connect to
* @param getMaster - do we check if master is alive
* @return proxy for HRegionServer
* @throws IOException
*/
public HRegionInterface getHRegionConnection(
HServerAddress regionServer, boolean getMaster)
throws IOException;
/**
* Find region location hosting passed row
* @param tableName
* @param row Row to find.
* @param reload If true do not use cache, otherwise bypass.
* @return Location of row.
* @throws IOException
*/
HRegionLocation getRegionLocation(byte [] tableName, byte [] row,
boolean reload)
throws IOException;
/**
* Pass in a ServerCallable with your particular bit of logic defined and
* this method will manage the process of doing retries with timed waits
* and refinds of missing regions.
*
* @param <T> the type of the return value
* @param callable
* @return an object of type T
* @throws IOException
* @throws RuntimeException
*/
public <T> T getRegionServerWithRetries(ServerCallable<T> callable)
throws IOException, RuntimeException;
/**
* Pass in a ServerCallable with your particular bit of logic defined and
* this method will pass it to the defined region server.
* @param <T> the type of the return value
* @param callable
* @return an object of type T
* @throws IOException
* @throws RuntimeException
*/
public <T> T getRegionServerForWithoutRetries(ServerCallable<T> callable)
throws IOException, RuntimeException;
/**
* Process a batch of Puts. Does the retries.
* @param list A batch of Puts to process.
* @param tableName The name of the table
* @return Count of committed Puts. On fault, < list.size().
* @throws IOException
*/
public int processBatchOfRows(ArrayList<Put> list, byte[] tableName)
throws IOException;
/**
* Process a batch of Deletes. Does the retries.
* @param list A batch of Deletes to process.
* @return Count of committed Deletes. On fault, < list.size().
* @param tableName The name of the table
* @throws IOException
*/
public int processBatchOfDeletes(ArrayList<Delete> list, byte[] tableName)
throws IOException;
}
上面的code是整个接口的定义,我们现在知道这玩意是封装了一些客户端查询处理请求,像put、delete这些封装在方法
public <T> T getRegionServerWithRetries(ServerCallable<T> callable) 里执行,put、delete等被封装在callable里面。这也就是为我们刚才在HTable.get()里看到的。
到这里要看TableServers.getRegionServerWithRetries(ServerCallable<T> callable)了,继续看code
public <T> T getRegionServerWithRetries(ServerCallable<T> callable)
throws IOException, RuntimeException {
List<Throwable> exceptions = new ArrayList<Throwable>();
for(int tries = 0; tries < numRetries; tries++) {
try {
callable.instantiateServer(tries!=0); return callable.call();
} catch (Throwable t) {
t = translateException(t);
exceptions.add(t);
if (tries == numRetries - 1) {
throw new RetriesExhaustedException(callable.getServerName(),
callable.getRegionName(), callable.getRow(), tries, exceptions);
}
}
try {
Thread.sleep(getPauseTime(tries));
} catch (InterruptedException e) {
// continue
}
}
return null;
}
比较核心的code就那两句,首先根据callable对象来完成一些定位ReginServer的工作,然后执行call来进行请求,这里要注意这个call方法是在最最最最开始的HTable.get里面的内部类里重写的。看ServerCallable类的一部分code:
public abstract class ServerCallable<T> implements Callable<T> {
protected final HConnection connection;
protected final byte [] tableName;
protected final byte [] row;
protected HRegionLocation location;
protected HRegionInterface server;
/**
* @param connection
* @param tableName
* @param row
*/
public ServerCallable(HConnection connection, byte [] tableName, byte [] row) {
this.connection = connection;
this.tableName = tableName;
this.row = row;
}
/**
*
* @param reload set this to true if connection should re-find the region
* @throws IOException
*/
public void instantiateServer(boolean reload) throws IOException {
this.location = connection.getRegionLocation(tableName, row, reload);
this.server = connection.getHRegionConnection(location.getServerAddress());
}
所以一个ServerCallable对象包括tableName,row等,并且会通过构造函数传入一个connection引用,并且会调用该connection.getHRegionConnection方法来获取跟RegionServer打交道的一个handle(其实我也不知道称呼它啥了,不能叫connection吧,那就重复了,所以说HBase代码起的名字让我很ft,会误解)。
具体看怎么获得这个新玩意的:
HConnectinManager.java
public HRegionInterface getHRegionConnection(
HServerAddress regionServer, boolean getMaster)
throws IOException {
if (getMaster) {
getMaster();
}
HRegionInterface server;
synchronized (this.servers) {
// See if we already have a connection
server = this.servers.get(regionServer.toString());
if (server == null) { // Get a connection
try {
server = (HRegionInterface)HBaseRPC.waitForProxy(
serverInterfaceClass, HBaseRPCProtocolVersion.versionID,
regionServer.getInetSocketAddress(), this.conf,
this.maxRPCAttempts, this.rpcTimeout);
} catch (RemoteException e) {
throw RemoteExceptionHandler.decodeRemoteException(e);
}
this.servers.put(regionServer.toString(), server);
}
}
return server;
}
再挖下去看这个server怎么出来的(HBaseRPC类里面):
public static VersionedProtocol getProxy(Class<?> protocol,
long clientVersion, InetSocketAddress addr, UserGroupInformation ticket,
Configuration conf, SocketFactory factory)
throws IOException {
VersionedProtocol proxy =
(VersionedProtocol) Proxy.newProxyInstance(
protocol.getClassLoader(), new Class[] { protocol },
new Invoker(addr, ticket, conf, factory));
long serverVersion = proxy.getProtocolVersion(protocol.getName(),
clientVersion);
if (serverVersion == clientVersion) {
return proxy;
}
throw new VersionMismatch(protocol.getName(), clientVersion,
serverVersion);
}
这两部分code看出用到了java的动态代理机制,server是一个动态代理对象,实现了变量serverInterfaceClass指定的接口。在这里也就是HRegionInterface,也就是说server实现了该接口的内容。那么该接口定义哪些方法呢?
public interface HRegionInterface extends HBaseRPCProtocolVersion {
/**
* Get metainfo about an HRegion
*
* @param regionName name of the region
* @return HRegionInfo object for region
* @throws NotServingRegionException
*/
public HRegionInfo getRegionInfo(final byte [] regionName)
throws NotServingRegionException;
/**
* Return all the data for the row that matches <i>row</i> exactly,
* or the one that immediately preceeds it.
*
* @param regionName region name
* @param row row key
* @param family Column family to look for row in.
* @return map of values
* @throws IOException
*/
public Result getClosestRowBefore(final byte [] regionName,
final byte [] row, final byte [] family)
throws IOException;
/**
*
* @return the regions served by this regionserver
*/
public HRegion [] getOnlineRegionsAsArray();
/**
* Perform Get operation.
* @param regionName name of region to get from
* @param get Get operation
* @return Result
* @throws IOException
*/
public Result get(byte [] regionName, Get get) throws IOException;
/**
* Perform exists operation.
* @param regionName name of region to get from
* @param get Get operation describing cell to test
* @return true if exists
* @throws IOException
*/
public boolean exists(byte [] regionName, Get get) throws IOException;
/**
* Put data into the specified region
* @param regionName
* @param put the data to be put
* @throws IOException
*/
public void put(final byte [] regionName, final Put put)
throws IOException;
/**
* Put an array of puts into the specified region
*
* @param regionName
* @param puts
* @return The number of processed put's. Returns -1 if all Puts
* processed successfully.
* @throws IOException
*/
public int put(final byte[] regionName, final Put [] puts)
throws IOException;
/**
* Deletes all the KeyValues that match those found in the Delete object,
* if their ts <= to the Delete. In case of a delete with a specific ts it
* only deletes that specific KeyValue.
* @param regionName
* @param delete
* @throws IOException
*/
public void delete(final byte[] regionName, final Delete delete)
throws IOException;
/**
* Put an array of deletes into the specified region
*
* @param regionName
* @param deletes
* @return The number of processed deletes. Returns -1 if all Deletes
* processed successfully.
* @throws IOException
*/
public int delete(final byte[] regionName, final Delete [] deletes)
throws IOException;
/**
* Atomically checks if a row/family/qualifier value match the expectedValue.
* If it does, it adds the put.
*
* @param regionName
* @param row
* @param family
* @param qualifier
* @param value the expected value
* @param put
* @throws IOException
* @return true if the new put was execute, false otherwise
*/
public boolean checkAndPut(final byte[] regionName, final byte [] row,
final byte [] family, final byte [] qualifier, final byte [] value,
final Put put)
throws IOException;
/**
* Atomically increments a column value. If the column value isn't long-like,
* this could throw an exception.
*
* @param regionName
* @param row
* @param family
* @param qualifier
* @param amount
* @param writeToWAL whether to write the increment to the WAL
* @return new incremented column value
* @throws IOException
*/
public long incrementColumnValue(byte [] regionName, byte [] row,
byte [] family, byte [] qualifier, long amount, boolean writeToWAL)
throws IOException;
//
// remote scanner interface
//
/**
* Opens a remote scanner with a RowFilter.
*
* @param regionName name of region to scan
* @param scan configured scan object
* @return scannerId scanner identifier used in other calls
* @throws IOException
*/
public long openScanner(final byte [] regionName, final Scan scan)
throws IOException;
/**
* Get the next set of values
* @param scannerId clientId passed to openScanner
* @return map of values; returns null if no results.
* @throws IOException
*/
public Result next(long scannerId) throws IOException;
/**
* Get the next set of values
* @param scannerId clientId passed to openScanner
* @param numberOfRows the number of rows to fetch
* @return Array of Results (map of values); array is empty if done with this
* region and null if we are NOT to go to the next region (happens when a
* filter rules that the scan is done).
* @throws IOException
*/
public Result [] next(long scannerId, int numberOfRows) throws IOException;
/**
* Close a scanner
*
* @param scannerId the scanner id returned by openScanner
* @throws IOException
*/
public void close(long scannerId) throws IOException;
/**
* Opens a remote row lock.
*
* @param regionName name of region
* @param row row to lock
* @return lockId lock identifier
* @throws IOException
*/
public long lockRow(final byte [] regionName, final byte [] row)
throws IOException;
/**
* Releases a remote row lock.
*
* @param regionName
* @param lockId the lock id returned by lockRow
* @throws IOException
*/
public void unlockRow(final byte [] regionName, final long lockId)
throws IOException;
/**
* Method used when a master is taking the place of another failed one.
* @return All regions assigned on this region server
* @throws IOException
*/
public HRegionInfo[] getRegionsAssignment() throws IOException;
/**
* Method used when a master is taking the place of another failed one.
* @return The HSI
* @throws IOException
*/
public HServerInfo getHServerInfo() throws IOException;
}
可以看出HRegionInterface是定义了具体的向RegionServer查询的方法。
现在回过头来,当server这个动态代理对象实例化后,经过ServerCallable.call() 最后会调到server.get()。按照java的代理机制,又会传递到我们在构造这个动态代理对象时候传进去的new Invoker(addr, ticket, conf, factory))对象去执行具体的方法。
简单的说,这个Invoker对象使用HBase的RPC客户端跟RegionServer通信完成请求以及结果接收等等。
看看这个RPC客户端长什么样吧:
public Invoker(InetSocketAddress address, UserGroupInformation ticket,
Configuration conf, SocketFactory factory) {
this.address = address;
this.ticket = ticket;
this.client = CLIENTS.getClient(conf, factory); //client就是RPC客户端
}
这个client是HBaseClient类的对象,这个HBaseClient类就是HBase中用来做RPC的客户端类。在这里HBaseClient也做了一个pool机制,不理解。。。code里面的注释如下:
// Construct & cache client. The configuration is only used for timeout,
// and Clients have connection pools. So we can either (a) lose some
// connection pooling and leak sockets, or (b) use the same timeout for all
// configurations. Since the IPC is usually intended globally, not
// per-job, we choose (a).
继续说下去,看这么一个client怎么完成最后的请求:
public Writable call(Writable param, InetSocketAddress addr,
UserGroupInformation ticket)
throws IOException {
Call call = new Call(param);
Connection connection = getConnection(addr, ticket, call);
connection.sendParam(call); // send the parameter
boolean interrupted = false;
synchronized (call) {
while (!call.done) {
try {
call.wait(); // wait for the result
} catch (InterruptedException ie) {
// save the fact that we were interrupted
interrupted = true;
}
}
if (interrupted) {
// set the interrupt flag now that we are done waiting
Thread.currentThread().interrupt();
}
if (call.error != null) {
if (call.error instanceof RemoteException) {
call.error.fillInStackTrace();
throw call.error;
}
// local exception
throw wrapException(addr, call.error);
}
return call.value;
}
}
又见connection,这次的connection可是用来发送接收数据用的thread了。从getConnection(addr, ticket, call)推断又是一个pool,果不其然:
/** Get a connection from the pool, or create a new one and add it to the
* pool. Connections to a given host/port are reused. */
private Connection getConnection(InetSocketAddress addr,
UserGroupInformation ticket,
Call call)
throws IOException {
if (!running.get()) {
// the client is stopped
throw new IOException("The client is stopped");
}
Connection connection;
/* we could avoid this allocation for each RPC by having a
* connectionsId object and with set() method. We need to manage the
* refs for keys in HashMap properly. For now its ok.
*/
ConnectionId remoteId = new ConnectionId(addr, ticket);
do {
synchronized (connections) {
connection = connections.get(remoteId);
if (connection == null) {
connection = new Connection(remoteId);
connections.put(remoteId, connection);
}
}
} while (!connection.addCall(call));
//we don't invoke the method below inside "synchronized (connections)"
//block above. The reason for that is if the server happens to be slow,
//it will take longer to establish a connection and that will slow the
//entire system down.
connection.setupIOstreams();
return connection;
}
也就是说,只要所要查询的RegionServer的addr和用户组信息一样,就会共享一个connection。connection拿到后会将当前call放进自己内部的一个队列里(维护着call的id=》call的一个映射),当call完成后会更新call的状态(主要是否完成这么一个标志Call.done以及将请求结果填充在Call.value里)。
好了现在的情形是,现在看connection如何发送请求数据。
/** Initiates a call by sending the parameter to the remote server.
* Note: this is not called from the Connection thread, but by other
* threads.
* @param call
*/
public void sendParam(Call call) {
if (shouldCloseConnection.get()) {
return;
}
DataOutputBuffer d=null;
try {
synchronized (this.out) {
if (LOG.isDebugEnabled())
LOG.debug(getName() + " sending #" + call.id);
//for serializing the
//data to be written
d = new DataOutputBuffer();
d.writeInt(call.id);
call.param.write(d);
byte[] data = d.getData();
int dataLength = d.getLength();
out.writeInt(dataLength); //first put the data length
out.write(data, 0, dataLength);//write the data
out.flush();
}
} catch(IOException e) {
markClosed(e);
} finally {
//the buffer is just an in-memory buffer, but it is still polite to
// close early
IOUtils.closeStream(d);
}
}
从code里面看出,请求发送是synchronized,所以会有上一篇日志里提到的问题。
HBase客户端的code先看到这里吧。
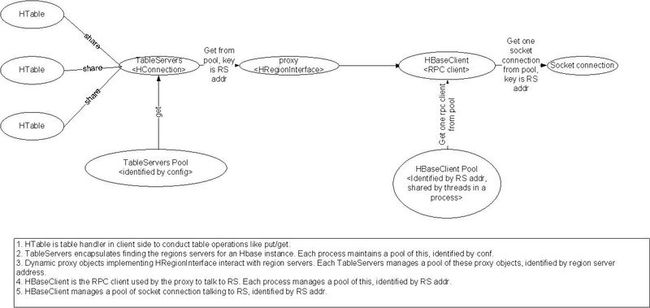
下面这个图帮助理解一下上面各种pool