kafka 学习点滴<一>
处理机制:
首先我要分为以下几点来描述一下我对kafka运行机制的了解:
1.连接kafka: kafka是一个分布式消息分发系统,建议连接servers中指定大于2个的“host:port,host:port”. 可以降低kafka server失联。
例如: 张一和张二是好朋友, 他们在不同的城市上班,如果张一的手机被偷了。那么张二就没办法联系到张一(连接出现异常), 如果把张一的朋友圈当作
是一个集群的话,张二拥有1个或多个张一朋友的电话号码,这样张一就不容易失联了。
2.kafka Client端: 在kafka的官方文档中有提出如何配置client的缓存策略、与server的确认策略等等,有很多
client与servier的配置,例如kafka并不是100%保证消息不丢失的, 除非你的配置很严格(例如 acks=all),
但是那样会严重影响client端的处理能力,同时也极大增加kafka server node之间通信及负载压力(这个也与你的备份策略有关),
Client 发送数据的流程是:首先存储在本地的缓存当中,本地的缓存信息会被一次一次批量的发送到kafka server中 ,
相关配置可以有buffer.memory compression.type等等。
buffer.memory: producer 会用 buffer.memory 大小的缓存来缓存数据,当数据发送到server的速度小于 客户端send的速度时,
会产生两种可能: 阻塞、抛出异常, 这两种可能是由 block.on.buffer.full 配置决定,如果block.on.buffer.full=true, 代表阻塞,否者就是抛出异常。
这里提出2个值得测试的问题:
(1).直接调用的kafka Client的客户端机器也会被缓存数据,如果因为kafka server异常导致大量阻塞的话,那就会导致当前程序死掉、挂起、内存泄露
(2).从代码设计的角度分析, 我觉得任何采集日志代码直接调用kafka client是不合理的。因为kafka Client 和 kafka server就好比是两道缓冲区。
彼此相互影响。你的代码影响了kafka Client, 就一定会影响kafka server。
compression.type:压缩类型, 用来压缩所有由producer产生的数据(The compression type for all data generated by the producer ),默认是none
3.kafka server接收数据
当kafka server接收到消息之后,会根据partition计算策略,将消息分割为多个partition, partition是replicated一个单位。且一个partition会被完整的存储在一个节点上。
partition的另一个作用是起到:balancing load。(我会4.中提到),还有一个作用是,它也是多个consumers顺序消费的独立单位。
之后,kafka 会直接将数据写入磁盘, 看了kafka作者对“写入磁盘,就一定影响效率吗?”分析描述。所以大可放心, 现在的文件系统IO已经相当成熟,并且性能也已经得到很大的提高。
例如:传统的IO方式是要经历4个过程才能入盘。kafka的IO解决方案只需要1步就可以入盘(我记得好像是1步)。在加上kafka的消息订阅都是顺序读取,所以速度相当快。
所以kafka几乎不会将消息数据存入内存。kafka是以log日志的方式存放消息数据的。
kafka的消息是有过期时间的(记得文档上说是默认两天,我记不起来了)。过期的消息就会被自动删除。
关于这点我想提出两个问题
1、什么叫过期消息?
我的理解是:
超过指定的时间,就一定会变成过期数据,接着就会被自动删除
2、什么才会导致消息过期?
我的理解是:
我这里不关心已经消费的数据。我们谈谈未消费的数据可不可能变成过期数据,这在我们的业务当中叫做消息丢失!举个例子,当我们的consumers调用端
端程序发生异常、阻塞、消费太慢等等条件,kafka就会重复发送(应该是可配的)。可是kafka server的接收消息很快,这样很有可能会导致大量的未读消息过期
4.Consumers 消费数据
之前我们提过:“消息是以partition为单位存储的,一个partition会被完整的存储在一个集群节点上。而且发送消息也是基于topic发送的”。
以下是我对consumers的理解:
kafka可以保证Consumers接收消息的顺序,例如producer连续发了两个消息:message1、message2,那么不管是queuing模式 还是 publish-subscribe模式,
Consumers接收到的消息顺序都是message1、message2(这一点让我想到了zookeeper的一些机制)。那具体是怎么做到的呢? 首先kafka会记录
每一个partition的位置,一个消
息可以有多个partition。在单个
消息完整性方面,kafka可以保证每一个相关partition位置的准确性、一致性。当一个或多个Consumers去订阅一个topic时。Kafka is able to provide both ordering guarantees and
load balancing over a pool of consumer processes(这句英文仿佛更能描述问题)。接下来顺序的将每一个消息的所有partition传递给every one of consumer processes。
读完之后、且Consumers满意之后(也就是调用Consumers的代码未发生异常、或超时),当前的topic下的partition位置都会移动到下一个消息位置(我在3中有提到顺序读取)
这里提出2个值的测试问题:
(1).在 publish-subscribe模式下,如果其中一个Consumers发生问题,那么partition位置就会“回滚”, 但是其他的Consumers都成功,这样会不会导致其他的Consumers
重复接收
(2).当Consumers的处理很耗时,那么会不会影响客户端send的速度。如果影响的话,那就会影响producer的吞吐量
、或者Client数据丢失(除非你对异常进行处理)
能做什么
这里列出了官网的应用场景:
1、Commit Log / Log Aggregation: 例如 集中 对分布式环境下的 日志收集
2、Event Sourcing:可以作为一种事件发生源。该应用场景很多:下发通知、flume日志源、分布式交互、实时顺序队列(sequence)等等
3、Stream Processing:流式处理,Consumers可以当做是流式处理中的一个处理单元(或者叫做节点)。可以当做storm使用。例如可以将从一个topic获取的消息处理完之后传递给另一个topic,这样另外一个Consumers或多个Consumers就可以继续处理。处理失败之后还会重新处理。
4、Metrics: 例如分布式环境下,可以将 各个applications的实时监控、或者状态实时统计、汇总数据实时的发送到kafka server上,之后可以供任何应用系统订阅。
等等。个人觉得它的应用场景非常广泛
如何提高高可用性、稳定性
在大数据情况下,以下仅是我个人的观点:
1、掌握kafka与我们实际应用相关的一些具体指标参数(例如在某某环境下,它的处理速度、效率到底什么样的),我觉得这些参数很重要,他会影响我们的架构设计。严重时
会导致我们对基础服务代码的大量重构。
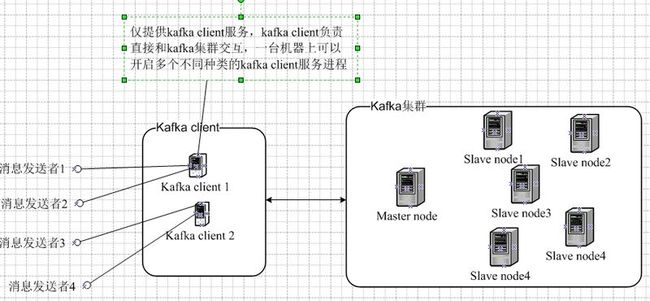
2、以下是我对大数据情况下,个人理解中的kafka具体架构设计与部署图(如下图):
kafka client 单独提出来的目的是:
(1)、充分应用kafka Client的缓存能力,平衡kafka集群的服务压力
(2)、提高“消息发送者" 的吞吐量. 因为kafka Client本身是异步的
(3)、提高可扩展性、配置灵活性:在适应环境的过程中,可以灵活方便的微调kafka Client 相关参数
首先我要分为以下几点来描述一下我对kafka运行机制的了解:
1.连接kafka: kafka是一个分布式消息分发系统,建议连接servers中指定大于2个的“host:port,host:port”. 可以降低kafka server失联。
例如: 张一和张二是好朋友, 他们在不同的城市上班,如果张一的手机被偷了。那么张二就没办法联系到张一(连接出现异常), 如果把张一的朋友圈当作
是一个集群的话,张二拥有1个或多个张一朋友的电话号码,这样张一就不容易失联了。
2.kafka Client端: 在kafka的官方文档中有提出如何配置client的缓存策略、与server的确认策略等等,有很多
client与servier的配置,例如kafka并不是100%保证消息不丢失的, 除非你的配置很严格(例如 acks=all),
但是那样会严重影响client端的处理能力,同时也极大增加kafka server node之间通信及负载压力(这个也与你的备份策略有关),
Client 发送数据的流程是:首先存储在本地的缓存当中,本地的缓存信息会被一次一次批量的发送到kafka server中 ,
相关配置可以有buffer.memory compression.type等等。
buffer.memory: producer 会用 buffer.memory 大小的缓存来缓存数据,当数据发送到server的速度小于 客户端send的速度时,
会产生两种可能: 阻塞、抛出异常, 这两种可能是由 block.on.buffer.full 配置决定,如果block.on.buffer.full=true, 代表阻塞,否者就是抛出异常。
这里提出2个值得测试的问题:
(1).直接调用的kafka Client的客户端机器也会被缓存数据,如果因为kafka server异常导致大量阻塞的话,那就会导致当前程序死掉、挂起、内存泄露
(2).从代码设计的角度分析, 我觉得任何采集日志代码直接调用kafka client是不合理的。因为kafka Client 和 kafka server就好比是两道缓冲区。
彼此相互影响。你的代码影响了kafka Client, 就一定会影响kafka server。
compression.type:压缩类型, 用来压缩所有由producer产生的数据(The compression type for all data generated by the producer ),默认是none
3.kafka server接收数据
当kafka server接收到消息之后,会根据partition计算策略,将消息分割为多个partition, partition是replicated一个单位。且一个partition会被完整的存储在一个节点上。
partition的另一个作用是起到:balancing load。(我会4.中提到),还有一个作用是,它也是多个consumers顺序消费的独立单位。
之后,kafka 会直接将数据写入磁盘, 看了kafka作者对“写入磁盘,就一定影响效率吗?”分析描述。所以大可放心, 现在的文件系统IO已经相当成熟,并且性能也已经得到很大的提高。
例如:传统的IO方式是要经历4个过程才能入盘。kafka的IO解决方案只需要1步就可以入盘(我记得好像是1步)。在加上kafka的消息订阅都是顺序读取,所以速度相当快。
所以kafka几乎不会将消息数据存入内存。kafka是以log日志的方式存放消息数据的。
kafka的消息是有过期时间的(记得文档上说是默认两天,我记不起来了)。过期的消息就会被自动删除。
关于这点我想提出两个问题
1、什么叫过期消息?
我的理解是:
超过指定的时间,就一定会变成过期数据,接着就会被自动删除
2、什么才会导致消息过期?
我的理解是:
我这里不关心已经消费的数据。我们谈谈未消费的数据可不可能变成过期数据,这在我们的业务当中叫做消息丢失!举个例子,当我们的consumers调用端
端程序发生异常、阻塞、消费太慢等等条件,kafka就会重复发送(应该是可配的)。可是kafka server的接收消息很快,这样很有可能会导致大量的未读消息过期
4.Consumers 消费数据
之前我们提过:“消息是以partition为单位存储的,一个partition会被完整的存储在一个集群节点上。而且发送消息也是基于topic发送的”。
以下是我对consumers的理解:
kafka可以保证Consumers接收消息的顺序,例如producer连续发了两个消息:message1、message2,那么不管是queuing模式 还是 publish-subscribe模式,
Consumers接收到的消息顺序都是message1、message2(这一点让我想到了zookeeper的一些机制)。那具体是怎么做到的呢? 首先kafka会记录
每一个partition的位置,一个消
息可以有多个partition。在单个
消息完整性方面,kafka可以保证每一个相关partition位置的准确性、一致性。当一个或多个Consumers去订阅一个topic时。Kafka is able to provide both ordering guarantees and
load balancing over a pool of consumer processes(这句英文仿佛更能描述问题)。接下来顺序的将每一个消息的所有partition传递给every one of consumer processes。
读完之后、且Consumers满意之后(也就是调用Consumers的代码未发生异常、或超时),当前的topic下的partition位置都会移动到下一个消息位置(我在3中有提到顺序读取)
这里提出2个值的测试问题:
(1).在 publish-subscribe模式下,如果其中一个Consumers发生问题,那么partition位置就会“回滚”, 但是其他的Consumers都成功,这样会不会导致其他的Consumers
重复接收
(2).当Consumers的处理很耗时,那么会不会影响客户端send的速度。如果影响的话,那就会影响producer的吞吐量
、或者Client数据丢失(除非你对异常进行处理)
能做什么
这里列出了官网的应用场景:
1、Commit Log / Log Aggregation: 例如 集中 对分布式环境下的 日志收集
2、Event Sourcing:可以作为一种事件发生源。该应用场景很多:下发通知、flume日志源、分布式交互、实时顺序队列(sequence)等等
3、Stream Processing:流式处理,Consumers可以当做是流式处理中的一个处理单元(或者叫做节点)。可以当做storm使用。例如可以将从一个topic获取的消息处理完之后传递给另一个topic,这样另外一个Consumers或多个Consumers就可以继续处理。处理失败之后还会重新处理。
4、Metrics: 例如分布式环境下,可以将 各个applications的实时监控、或者状态实时统计、汇总数据实时的发送到kafka server上,之后可以供任何应用系统订阅。
等等。个人觉得它的应用场景非常广泛
如何提高高可用性、稳定性
在大数据情况下,以下仅是我个人的观点:
1、掌握kafka与我们实际应用相关的一些具体指标参数(例如在某某环境下,它的处理速度、效率到底什么样的),我觉得这些参数很重要,他会影响我们的架构设计。严重时
会导致我们对基础服务代码的大量重构。
2、以下是我对大数据情况下,个人理解中的kafka具体架构设计与部署图(如下图):
kafka client 单独提出来的目的是:
(1)、充分应用kafka Client的缓存能力,平衡kafka集群的服务压力
(2)、提高“消息发送者" 的吞吐量. 因为kafka Client本身是异步的
(3)、提高可扩展性、配置灵活性:在适应环境的过程中,可以灵活方便的微调kafka Client 相关参数