RDD
RDD初始参数:上下文和一组依赖
- abstract class RDD[T: ClassTag](
- @transient private var sc: SparkContext,
- @transient private var deps: Seq[Dependency[_]]
- ) extends Serializable
以下需要仔细理清:
A list of Partitions
Function to compute split (sub RDD impl)
A list of Dependencies
Partitioner for K-V RDDs (Optional)
Preferred locations to compute each spliton (Optional)
Dependency
Dependency代表了RDD之间的依赖关系,即血缘
RDD中的使用
RDD给子类提供了getDependencies方法来制定如何依赖父类RDD
- protected def getDependencies: Seq[Dependency[_]] = deps
事实上,在获取first parent的时候,子类经常会使用下面这个方法
- protected[spark] def firstParent[U: ClassTag] = {
- dependencies.head.rdd.asInstanceOf[RDD[U]]
- }
可以看到,Seq里的第一个dependency应该是直接的parent,从而从第一个dependency类里获得了rdd,这个rdd就是父RDD。
一般的RDD子类都会这么实现compute和getPartition方法,以SchemaRDD举例:
- override def compute(split: Partition, context: TaskContext): Iterator[Row] =
- firstParent[Row].compute(split, context).map(_.copy())
- override def getPartitions: Array[Partition] = firstParent[Row].partitions
compute()方法调用了第一个父类的compute,把结果RDD copy返回
getPartitions返回的就是第一个父类的partitions
下面看一下Dependency类及其子类的实现。
宽依赖和窄依赖
- abstract class Dependency[T](val rdd: RDD[T]) extends Serializable
Dependency里传入的rdd,就是父RDD本身。
继承结构如下:
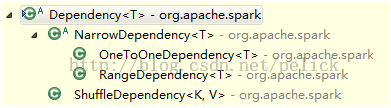
NarrowDependency代表窄依赖,即父RDD的分区,最多被子RDD的一个分区使用。所以支持并行计算。
子类需要实现方法:
- def getParents(partitionId: Int): Seq[Int]
OneToOneDependency表示父RDD和子RDD的分区依赖是一对一的。
RangeDependency表示在一个range范围内,依赖关系是一对一的,所以初始化的时候会有一个范围,范围外的partitionId,传进去之后返回的是Nil。
下面介绍宽依赖。
- class ShuffleDependency[K, V](
- @transient rdd: RDD[_ <: Product2[K, V]],
- val partitioner: Partitioner,
- val serializer: Serializer = null)
- extends Dependency(rdd.asInstanceOf[RDD[Product2[K, V]]]) {
- // 上下文增量定义的Id
- val shuffleId: Int = rdd.context.newShuffleId()
- // ContextCleaner的作用和实现在SparkContext章节叙述
- rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
- }
宽依赖针对的RDD是KV形式的,需要一个partitioner指定分区方式(下一节介绍),需要一个序列化工具类,序列化工具目前的实现如下:
宽依赖和窄依赖对失败恢复时候的recompute有不同程度的影响,宽依赖可能是要全部计算的。
Partition
Partition具体表示RDD每个数据分区。
Partition提供trait类,内含一个index和hashCode()方法,具体子类实现与RDD子类有关,种类如下:
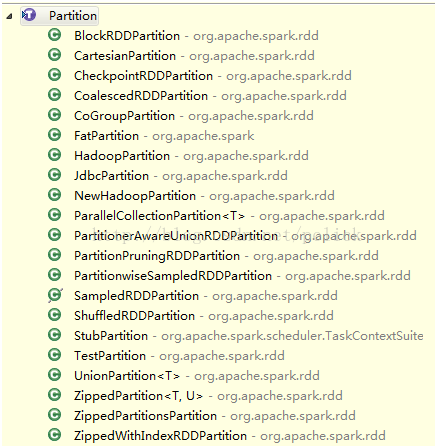
在分析每个RDD子类的时候再涉及。
Partitioner
Partitioner决定KV形式的RDD如何根据key进行partition

- abstract class Partitioner extends Serializable {
- def numPartitions: Int // 总分区数
- def getPartition(key: Any): Int
- }
在ShuffleDependency里对应一个Partitioner,来完成宽依赖下,子RDD如何获取父RDD。
默认Partitioner
Partitioner的伴生对象提供defaultPartitioner方法,逻辑为:
传入的RDD(至少两个)中,遍历(顺序是partition数目从大到小)RDD,如果已经有Partitioner了,就使用。如果RDD们都没有Partitioner,则使用默认的HashPartitioner。而HashPartitioner的初始化partition数目,取决于是否设置了spark.default.parallelism,如果没有的话就取RDD中partition数目最大的值。
如果上面这段文字看起来费解,代码如下:
- def defaultPartitioner(rdd: RDD[_], others: RDD[_]*): Partitioner = {
- val bySize = (Seq(rdd) ++ others).sortBy(_.partitions.size).reverse
- for (r <- bySize if r.partitioner.isDefined) {
- return r.partitioner.get
- }
- if (rdd.context.conf.contains("spark.default.parallelism")) {
- new HashPartitioner(rdd.context.defaultParallelism)
- } else {
- new HashPartitioner(bySize.head.partitions.size)
- }
- }
HashPartitioner
HashPartitioner基于java的Object.hashCode。会有个问题是Java的Array有自己的hashCode,不基于Array里的内容,所以RDD[Array[_]]或RDD[(Array[_], _)]使用HashPartitioner会有问题。
顾名思义,getPartition方法实现如下
- def getPartition(key: Any): Int = key match {
- case null => 0
- case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
- }
RangePartitioner
RangePartitioner处理的KV RDD要求Key是可排序的,即满足Scala的Ordered[K]类型。所以它的构造如下:
- class RangePartitioner[K <% Ordered[K]: ClassTag, V](
- partitions: Int,
- @transient rdd: RDD[_ <: Product2[K,V]],
- private val ascending: Boolean = true)
- extends Partitioner {
内部会计算一个rangBounds(上界),在getPartition的时候,如果rangBoundssize小于1000,则逐个遍历获得;否则二分查找获得partitionId。
Persist
默认cache()过程是将RDD persist在内存里,persist()操作可以为RDD重新指定StorageLevel,
- class StorageLevel private(
- private var useDisk_ : Boolean,
- private var useMemory_ : Boolean,
- private var useOffHeap_ : Boolean,
- private var deserialized_ : Boolean,
- private var replication_ : Int = 1)
- object StorageLevel {
- val NONE = new StorageLevel(false, false, false, false)
- val DISK_ONLY = new StorageLevel(true, false, false, false)
- val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
- val MEMORY_ONLY = new StorageLevel(false, true, false, true)
- val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
- val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
- val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
- val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
- val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
- val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
- val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
- val OFF_HEAP = new StorageLevel(false, false, true, false) // Tachyon
RDD的persist()和unpersist()操作,都是由SparkContext执行的(SparkContext的persistRDD和unpersistRDD方法)。
Persist过程是把该RDD存在上下文的TimeStampedWeakValueHashMap里维护起来。也就是说,其实persist并不是action,并不会触发任何计算。
Unpersist过程如下,会交给SparkEnv里的BlockManager处理。
- private[spark] def unpersistRDD(rddId: Int, blocking: Boolean = true) {
- env.blockManager.master.removeRdd(rddId, blocking)
- persistentRdds.remove(rddId)
- listenerBus.post(SparkListenerUnpersistRDD(rddId))
- }
Checkpoint
RDD Actions api里提供了checkpoint()方法,会把本RDD save到SparkContext CheckpointDir
目录下。建议该RDD已经persist在内存中,否则需要recomputation。
如果该RDD没有被checkpoint过,则会生成新的RDDCheckpointData。RDDCheckpointData类与一个RDD关联,记录了checkpoint相关的信息,并且记录checkpointRDD的一个状态,
[ Initialized --> marked for checkpointing--> checkpointing in progress --> checkpointed ]
内部有一个doCheckpoint()方法(会被下面调用)。
执行逻辑
真正的checkpoint触发,在RDD私有方法doCheckpoint()里。doCheckpoint()会被DAGScheduler调用,且是在此次job里使用这个RDD完毕之后,此时这个RDD就已经被计算或者物化过了。可以看到,会对RDD的父RDD进行递归。
- private[spark] def doCheckpoint() {
- if (!doCheckpointCalled) {
- doCheckpointCalled = true
- if (checkpointData.isDefined) {
- checkpointData.get.doCheckpoint()
- } else {
- dependencies.foreach(_.rdd.doCheckpoint())
- }
- }
- }
RDDCheckpointData的doCheckpoint()方法关键代码如下:
- // Create the output path for the checkpoint
- val path = new Path(rdd.context.checkpointDir.get, "rdd-" + rdd.id)
- val fs = path.getFileSystem(rdd.context.hadoopConfiguration)
- if (!fs.mkdirs(path)) {
- throw new SparkException("Failed to create checkpoint path " + path)
- }
- // Save to file, and reload it as an RDD
- val broadcastedConf = rdd.context.broadcast(
- new SerializableWritable(rdd.context.hadoopConfiguration))
- // 这次runJob最终调的是dagScheduler的runJob
- rdd.context.runJob(rdd,
- CheckpointRDD.writeToFile(path.toString, broadcastedConf) _)
- // 此时rdd已经记录到磁盘上
- val newRDD = new CheckpointRDD[T](rdd.context, path.toString)
- if (newRDD.partitions.size != rdd.partitions.size) {
- throw new SparkException("xxx")
- }
runJob最终调的是dagScheduler的runJob。做完后,生成一个CheckpointRDD。
具体CheckpointRDD相关内容可以参考其他章节。
API
子类需要实现的方法
- // 计算某个分区
- def compute(split: Partition, context: TaskContext): Iterator[T]
- protected def getPartitions: Array[Partition]
- // 依赖的父RDD,默认就是返回整个dependency序列
- protected def getDependencies: Seq[Dependency[_]] = deps
- protected def getPreferredLocations(split: Partition): Seq[String] = Nil
Transformations
Actions
略。SubRDDs
部分RDD子类的实现分析,包括以下几个部分:
1)子类本身构造参数
2)子类的特殊私有变量
3)子类的Partitioner实现
4)子类的父类函数实现
- def compute(split: Partition, context: TaskContext): Iterator[T]
- protected def getPartitions: Array[Partition]
- protected def getDependencies: Seq[Dependency[_]] = deps
- protected def getPreferredLocations(split: Partition): Seq[String] = Nil
CheckpointRDD
- class CheckpointRDD[T: ClassTag](sc: SparkContext, val checkpointPath: String)
- extends RDD[T](sc, Nil)
CheckpointRDDPartition继承自Partition,没有什么增加。
有一个被广播的hadoop conf变量,在compute方法里使用(readFromFile的时候用)
- val broadcastedConf = sc.broadcast(
- new SerializableWritable(sc.hadoopConfiguration))
getPartitions: Array[Partition]方法:
根据checkpointPath去查看Path下有多少个partitionFile,File个数为partition数目。getPartitions方法返回的Array[Partition]内容为New CheckpointRDDPartition(i),i为[0, 1, …, partitionNum]
getPreferredLocations(split:Partition): Seq[String]方法:
文件位置信息,借助hadoop core包,获得block location,把得到的结果按照host打散(flatMap)并过滤掉localhost,返回。
compute(split: Partition, context:TaskContext): Iterator[T]方法:
调用CheckpointRDD.readFromFile(file, broadcastedConf,context)方法,其中file为hadoopfile path,conf为广播过的hadoop conf。
Hadoop文件读写及序列化
伴生对象提供writeToFile方法和readFromFile方法,主要用于读写hadoop文件,并且利用env下的serializer进行序列化和反序列化工作。两个方法具体实现如下:
- def writeToFile[T](
- path: String,
- broadcastedConf: Broadcast[SerializableWritable[Configuration]],
- blockSize: Int = -1
- )(ctx: TaskContext, iterator: Iterator[T]) {
创建hadoop文件的时候会若存在会抛异常。把hadoop的outputStream放入serializer的stream里,serializeStream.writeAll(iterator)写入。
writeToFile的调用在RDDCheckpointData类的doCheckpoint方法里,如下:
- rdd.context.runJob(rdd,
- CheckpointRDD.writeToFile(path.toString, broadcastedConf) _)
- def readFromFile[T](
- path: Path,
- broadcastedConf: Broadcast[SerializableWritable[Configuration]],
- context: TaskContext
- ): Iterator[T] = {
打开Hadoop的inutStream,读取的时候使用env下的serializer得到反序列化之后的流。返回的时候,DeserializationStream这个trait提供了asIterator方法,每次next操作可以进行一次readObject。
在返回之前,调用了TaskContext提供的addOnCompleteCallback回调,用于关闭hadoop的inputStream。
NewHadoopRDD
- class NewHadoopRDD[K, V](
- sc : SparkContext,
- inputFormatClass: Class[_ <: InputFormat[K, V]],
- keyClass: Class[K],
- valueClass: Class[V],
- @transient conf: Configuration)
- extends RDD[(K, V)](sc, Nil)
- with SparkHadoopMapReduceUtil
- private[spark] class NewHadoopPartition(
- rddId: Int,
- val index: Int,
- @transient rawSplit: InputSplit with Writable)
- extends Partition {
- val serializableHadoopSplit = new SerializableWritable(rawSplit)
- override def hashCode(): Int = 41 * (41 + rddId) + index
- }
getPartitions操作:
根据inputFormatClass和conf,通过hadoop InputFormat实现类的getSplits(JobContext)方法得到InputSplits。(ORCFile在此处的优化)
这样获得的split同RDD的partition直接对应。
compute操作:
针对本次split(partition),调用InputFormat的createRecordReader(split)方法,
得到RecordReader<K,V>。这个RecordReader包装在Iterator[(K,V)]类内,复写Iterator的next()和hasNext方法,让compute返回的InterruptibleIterator[(K,V)]能够被迭代获得RecordReader取到的数据。
getPreferredLocations(split: Partition)操作:
- theSplit.serializableHadoopSplit.value.getLocations.filter(_ != "localhost")
在NewHadoopPartition里SerializableWritable将split序列化,然后调用InputSplit本身的getLocations接口,得到有数据分布节点的nodes name列表。
WholeTextFileRDD
NewHadoopRDD的子类
- private[spark] class WholeTextFileRDD(
- sc : SparkContext,
- inputFormatClass: Class[_ <: WholeTextFileInputFormat],
- keyClass: Class[String],
- valueClass: Class[String],
- @transient conf: Configuration,
- minSplits: Int)
- extends NewHadoopRDD[String, String](sc, inputFormatClass, keyClass, valueClass, conf) {
复写了getPartitions方法:
NewHadoopRDD有自己的inputFormat实现类和recordReader实现类。在spark/input package下专门写了这两个类的实现。感觉是种参考。
InputFormat
WholeTextFileRDD在spark里实现了自己的inputFormat。读取的File以K,V的结构获取,K为path,V为整个file的content。
复写createRecordReader以使用WholeTextFileRecordReader
复写setMaxSplitSize方法,由于用户可以传入minSplits数目,计算平均大小(splits files总大小除以split数目)的时候就变了。
RecordReader
复写nextKeyValue方法,会读出指定path下的file的内容,生成new Text()给value,结果是String。如果文件正在被别的进行打开着,会返回false。否则把file内容读进value里。
使用场景
在SparkContext下提供wholeTextFile方法,
- def wholeTextFiles(path: String, minSplits: Int = defaultMinSplits):
- RDD[(String, String)]
用于读取一个路径下的所有text文件,以K,V的形式返回,K为一个文件的path,V为文件内容。比较适合小文件。