这段时间本人利用空闲时间解读了一下Hibernate3的源码,饶有收获,愿与大家共享。
废话不多说,首先我们先对Hibernate有一个大致的印象
l 设计模式Hibernate=监听器,实际上是回调
l Hibernate3支持拦截器
Hibernate配置方面的大原则:
l bhn.xml文件所有配置都是描述本实体,除了cascade描述级联,即如何将本实体的操作(增删查改)传递给关联方。
l inverse属性表示本实体是否拥有主动权,在一条cascade链路传递过程中,当出现inverse=false表示不再返回原cascade链路,而是从此处重新开始链路。inverse只有在非many方才有,也就是many-to-many或者one-to-many的set,List等。
下面是注明inverse=true与inverse=false的cascade链路的区别:
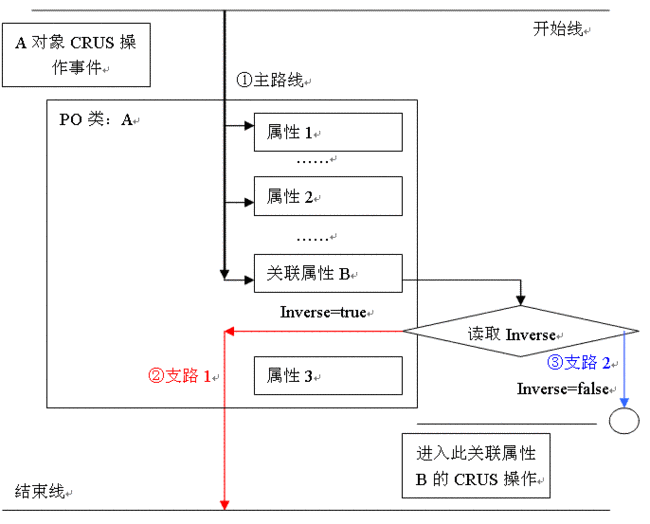
说明:若关联属性inverse=true,操作的结果将是校对A的属性所生成的sql;若关联属性inverse=false,结果将是丢弃先前A的操作,而转向对B的属性的校验所生成的sql;如果B中的属性也关联着inverse=false,则仍丢弃B继续新开启链路,直至没有关联方为inervse=false。不必担心,关联着的双方只有一方拥有inverse属性,所以不会一直传递下去。还有,丢弃了先前的操作不等于之前的对象操作无效,其效果相当于,原先的session.save(A),变成了session(A.B)而在B校对属性时总会找回A对象的。
测试用例:(暂不考虑inverse=false)
测试1:save()一个实体对象操作,预计insert发生在拥有外键方的表,拥有外键方的表是一对多中的多方。
结论1:如果实体对象的外键属性为null,表示不会产生关联,可直接生成sql;如果外键属性不为空,根据配置中的cascade去做关联。如果cascade=all则生成此表的insert和关联表update的sql,也就是说此时要求关联属性的主键id不能为null;如果cascade=save-update则生成此表的insert和关联表的insert/update的sql(关键属性的主键为null为insert,否则为update)。
见下图:
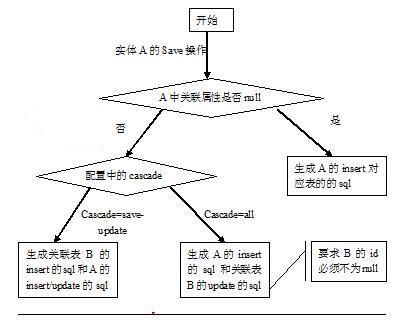
举例说明:
---------PO类:A中有B类型的关联属性
class A{
private int id;
private B b;
}
class B{
private int id;
private String str;
}
---------调用处关键代码:
A a=new A();//待操作的实体对象
B b=new B();//关联属性
a.setB(b);//设置关联属性
//----
//a.setId(1);//save()操作不允许预定一个id,hibernate的Id必须使用配置中的方式生成
//a.setB(null);//关联属性为null
//----
b.setId(1);/*关联属性的主键有值。只有cascade链在B对象校验为update操作才有效,也就是说A.bhn.xml中B
*的级联设为cascade=save-update。*/
b.setId(null);/*关联属性的主键为null。支持cascade=all与cascade=save-update的操作,最终在B生成的
* 是insert操作*/
//--------
b.setStr("当前用于测试");//------数据项
//-------操作
session.save(a);
源码解读:(粗略)
Hibernate主要是事件监听模式(回调的一种实现),其核心类为Session类,Session类承载了CRUS操作和Commit操作。
补充知识点:回调的好处在于事件源对象eventSource和数据对象Object,被集中在监听器Listener里完成业务,集中的好处在于新写Listener就可以达到功能的扩展。Listener的处理方法的参数为,事件对象eventObject,事件对象包含事件源eventSource和数据对象,相当于Listener传的是两个参数,也就是说Listener得到了此数据模型中的所有数据,自然可以完成任何功能,其余部分在模型中可理解为仅是为了给Listener传参做准备。通常的运行流程是事件源先被调用方法,所以事件源的方法里完成了业务功能,所谓回调就是形式上还是调用了事件源的方法,但是业务功能的代码却在第三方的Listener类中完成,而事件源的方法里只是为了实现如何传参给Listener。这样就像是与传统编程相反由Listener去调用事件源。
案例1:Session的S查询操作
过程略:
小结:Hibernate的Select操作直接生成sql,当然通过了内存缓存才生成的sql。
案例2:Session调用CRU操作(非S操作,增删改)。
以Save()操作为例
步骤1. SessionImpl.save(obj); SessionImpl.save(null,obj);--从save(Object,Object)统一调用
步骤2. new SaveOrUpdateEvent(entityName, object, this)—创建并组装事件对象(用于Listener的参数)
步骤3. SessionImpl.fireSave(SaveOrUpdateEvent);--触发事件,即调用Listener的处理方法,目的在于传参步骤2中new出的SaveOrUpdateEvent事件对象。
代码如下:
private Serializable fireSave(SaveOrUpdateEvent event) {
errorIfClosed();
checkTransactionSynchStatus();
SaveOrUpdateEventListener[] saveEventListener = listeners.getSaveEventListeners();
for ( int i = 0; i < saveEventListener.length; i++ ) {
saveEventListener[i].onSaveOrUpdate(event);
}
return event.getResultId();
}
红色为关键代码,其中listeners为Session的EventListeners属性。
EventListeners包含有一系列的监听器,而各种监听器以数组的形式允许有多个并且按顺序调用。本例中调用的监听器种类为saveOrUpdateEventListeners,处理方法为onSaveOrUpdate()方法。实现onSaveOrUpdate(event)的类是DefaultSaveOrUpdateEventListener。所以业务实现代码应该在DefaultSaveOrUpdateEventListener.onSaveOrUpdate()中
EventListeners类中的一系列Listener []属性:
private LoadEventListener[] loadEventListeners = { new DefaultLoadEventListener() };
private SaveOrUpdateEventListener[] saveOrUpdateEventListeners = { newDefaultSaveOrUpdateEventListener() };
private MergeEventListener[] mergeEventListeners = { new DefaultMergeEventListener() };
private PersistEventListener[] persistEventListeners = { newDefaultPersistEventListener() };
private PersistEventListener[] persistOnFlushEventListeners = { newDefaultPersistOnFlushEventListener() };
private ReplicateEventListener[] replicateEventListeners = { newDefaultReplicateEventListener() };
private DeleteEventListener[] deleteEventListeners = { newDefaultDeleteEventListener() };
private AutoFlushEventListener[] autoFlushEventListeners = { newDefaultAutoFlushEventListener() };
private DirtyCheckEventListener[] dirtyCheckEventListeners = { newDefaultDirtyCheckEventListener() };
private FlushEventListener[] flushEventListeners = { new DefaultFlushEventListener() };
private EvictEventListener[] evictEventListeners = { new DefaultEvictEventListener() };
private LockEventListener[] lockEventListeners = { new DefaultLockEventListener() };
private RefreshEventListener[] refreshEventListeners = { newDefaultRefreshEventListener() };
private FlushEntityEventListener[] flushEntityEventListeners = { newDefaultFlushEntityEventListener() };
private InitializeCollectionEventListener[] initializeCollectionEventListeners =
{ new DefaultInitializeCollectionEventListener() };
步骤4. DefaultSaveOrUpdateEventListener.onSaveOrUpdate()----业务功能代码。由于方法的实现涉及内容比较多,此处暂不作详细介绍。大致功能有为了补充齐全SaveOrUpdateEvent事件对象的其他属性,可见事件对象是记录Hibernate操作过程的容器。
步骤5.根据我们提交给Hibernate的Session的CRU指令操作,重复步骤1到步骤4多次直到最后到tran.commit()操作,tran是Session开启的Transction对象,默认JDBCTransction实现,根据hibernate.cfg.xml中配置确定了在new Configuration().configure()创立的,假定JDBCTransction.commit()的实现,具体代码如下:
public void commit() throws HibernateException {
if (!begun) {
throw new TransactionException("Transaction not successfully started");
}
log.debug("commit");
if ( !transactionContext.isFlushModeNever() && callback ) {
transactionContext.managedFlush(); //if an exception occurs during flush, user must call rollback()
}
notifyLocalSynchsBeforeTransactionCompletion();
if ( callback ) {
jdbcContext.beforeTransactionCompletion( this );
}
try {
commitAndResetAutoCommit();
log.debug("committed JDBC Connection");
committed = true;
if ( callback ) {
jdbcContext.afterTransactionCompletion( true, this );
}
notifyLocalSynchsAfterTransactionCompletion( Status.STATUS_COMMITTED );
}
catch (SQLException e) {
log.error("JDBC commit failed", e);
commitFailed = true;
if ( callback ) {
jdbcContext.afterTransactionCompletion( false, this );
}
notifyLocalSynchsAfterTransactionCompletion( Status.STATUS_UNKNOWN );
throw new TransactionException("JDBC commit failed", e);
}
finally {
closeIfRequired();
}
}
其中红色部分是生成sql的方法,这里暂不展开说明,生成sql依据的是上面步骤1-4所补充完整的事件对象。
绿色部分是Hibernate3对拦截器的支持,我们都知道Hibernate3比较之前的版本的一个重要的新特性就是支持拦截器,而这一特性就体现在此处。
小结:Session的非查询操作,只有到tran.commit()才生成sql,期间所有的CRU操作的结果都存放到对应的EventObject对象,对于保存C操作和更改U操作都存放在SaveOrUpdateEvent,删除操作R存放在DeleteEvent,而后commit()完成所有EventObject生成sql的规则。
各种操作与相应的流程如下面:
| 操作/流程 |
入口 |
创建事件对象 |
触发事件 |
事件处理方法 |
| save |
SessionImpl.save() |
new SaveOrUpdateEvent() |
fireSave() |
DefaultSaveOrUpdateEventListener |
| update |
SessionImpl.update() |
new SaveOrUpdateEvent() |
fireUpdate() |
DefaultSaveOrUpdateEventListener |
| Delete |
SessionImpl.delete() |
new DeleteEvent() |
fireDelete() |
DefaultDeleteEventListener |
补充:所有业务处理监听器都在org.hibernate.event.def包下
总结:
1.save操作:commit()时,数据库执行,并增加缓存中的对象。
2.delete操作:要求含有主键,commit()时,数据库执行,并删除缓存中的对象。
如果删除执行记录数无影响,即没有找到要删除的记录,报错。
3.Select操作:直接查询数据库,更新缓存中的对象。
4.update操作:要求含有主键,commit()时,数据库执行,并更新缓存中的对象。
如果更新执行记录数无影响,即没有找到要修改的记录,报错。
使用Hibernate时需要确定表的结构,只有确定了表的结构才能确定表的执行顺序,虽然Hibernate的目地是让我们编程只关心要操作对象,但是我们要明白维护(cascade链路方向)的方向是单向的,即使我们说Hibernate支持双向关联。
-
维护方向是cascade和inverse配置出来的,Hibernate会遵循配置,去生成sql;
-
另外所谓的双向关联只不过是维护方向单向查询出所关联的对象而后在内存中进行回填。如,User:Address=1:1,双向关联的目标是查询User对象,可得到User=User.getAddress().getUser()的结果,Hibernate的实现是单向查询得到User即关联属性Address对象,而后User.getAddress().setUser(User)进行回填。
SessionImpl==EventSource 事件源
SaveOrUpdateEvent==Event事件对象