一. 简述
URI调度,简单的来说就是提供一个分配URI和加入URI的方法,抓取线程通过分配URI获取待抓取URI,抓取分析完成后需要把希望继续抓取的URI加入到调度器内,等待调度。Heritrix的CrawlController是通过定义一个
private transient Frontier frontier
来实现调度器的管理的,Heritrix提供了若干个调度器的实现,当然也可以根据自己的实际需要改写或完全重新定义自己的调度器,可以通过order.xml定义frontier为自定义的实现类。默认的实现类是BdbFrontier,一个基于BDB持久化的调度器实现,以下是其配置例子
<newObject name="frontier" class="org.archive.crawler.frontier.BdbFrontier"><!-- Frontier 调度器-->
<float name="delay-factor">4.0</float><!-- 从同一个服务器(host)获取需要等待的间隔时间,可以预防无节制的抓取一个网站.通常是用该值去乘以上一个url的抓取时间来表示为下一个url需要等待的时间 -->
<integer name="max-delay-ms">20000</integer><!-- 最大的等待时间,单位毫秒 -->
<integer name="min-delay-ms">2000</integer><!-- 最小等待时间,单位毫秒-->
<integer name="respect-crawl-delay-up-to-secs">300</integer><!--当读取robots.txt时推迟抓取的时间,单位毫秒 -->
<integer name="max-retries">30</integer><!-- 已经尝试失败的URI的重新尝试次数,很多人在跑Heritrix的时候,发现只跑了30个URL就停止了,其实是一个URL都没成功,它这里重试了30次 -->
<long name="retry-delay-seconds">900</long><!--默认多长时间我们重新去抓取一个检索失败的URI -->
<integer name="preference-embed-hops">1</integer><!--嵌入或者重定向URI调度等级,例如,该值为1(默认也为1),调度时将比普通的link等级高.如果设置为0,则和link一样 -->
<integer name="total-bandwidth-usage-KB-sec">0</integer><!--爬虫所允许的最大宽带平均数,实际的读取速度是不受此影响的,当爬虫使用的宽带接近极限时,它会阻碍新的URI去处理,0表示没有限制 -->
<integer name="max-per-host-bandwidth-usage-KB-sec">0</integer><!--爬虫允许的每个域名所使用的最大宽带数,实际的读取速度不会受此影响,当爬虫使用的宽带接近极限时,它会阻碍新的URI去处理,0表示没有限制 -->
<string name="queue-assignment-policy">org.archive.crawler.frontier.HostnameQueueAssignmentPolicy</string><!--定义如何去分配URI到各个队列,这个类是相同的host的url就属于同一个队列 -->
<string name="force-queue-assignment"></string><!--强制URI的队列名字, -->
<boolean name="pause-at-start">false</boolean><!-- 在URI被尝试前,当爬虫启动后是否暂停?这个操作可以在爬虫工作前核实或调整爬虫。默认为false -->
<boolean name="pause-at-finish">false</boolean><!-- 当爬虫结束时是否暂停,而不是立刻停止工作.这个操作可以在爬虫状态还是可用时,有机会去显示爬虫结果,并有可能去增加URI和调整setting,默认为false-->
<boolean name="source-tag-seeds">false</boolean><!-- 是否去标记通过种子抓取的uri作为种子的遗传,用source值代替.-->
<boolean name="recovery-log-enabled">true</boolean><!--设置为false表示禁用恢复日志写操作,为true时候表示你用checkpoint去恢复crawl销毁的数据 -->
<boolean name="hold-queues">true</boolean><!--当队列数量未达到时,是否不让其运行,达到了才运行。是否要去持久化一个创建的每个域名一个的URI工作队列直到他们需要一直繁忙(开始工作)。如果为false(默认值),队列会在任何时间提供URI去抓取。如果为true,则队列一开始(还有收集的url)会处于不在活动中的状态,只有在Frontier需要另外一个队列使得所有线程繁忙的时候才会让一个新的队列出于活动状态. -->
<integer name="balance-replenish-amount">3000</integer><!--补充一定的数量去使得队列平衡,更大的数目则意味着更多的URI将在它们处于等待队列停用之前将被尝试 -->
<integer name="error-penalty-amount">100</integer><!-- 当队列中的一个URI处理失败时,需要另外处罚的数量.加速失活或问题队列,反应迟钝的网站完全退休。,默认为100-->
<long name="queue-total-budget">-1</long><!--单个队列所允许的活动的开支,队列超出部分将被重试或者不再抓取,默认为-1,则表示没有这个限制 -->
<string name="cost-policy">org.archive.crawler.frontier.ZeroCostAssignmentPolicy</string><!-- 用于计算每个URI成本,默认为UnitCostAssignmentPolicy则认为每个URI的成本为1-->
<long name="snooze-deactivate-ms">300000</long><!--任何snooze延迟都会影响队列不活动,允许其他队列有机会进入活动状态,通常设置为比在成功获取时暂停时间长,比连接失败短,默认为5分钟 -->
<integer name="target-ready-backlog">50</integer><!--准备积压队列的目标大小,这里多个队列将会进入准备状态即使线程不再等待.只有hold-queues为true才有效,默认为50 -->
<string name="uri-included-structure">org.archive.crawler.util.BdbUriUniqFilter</string><!-- -->
<boolean name="dump-pending-at-close">false</boolean><!-- -->
</newObject>
这些配置属性在稍后的代码分析中可以看到是怎样使用的。
二. 接口定义

这里先解释一下主要的几个方法:
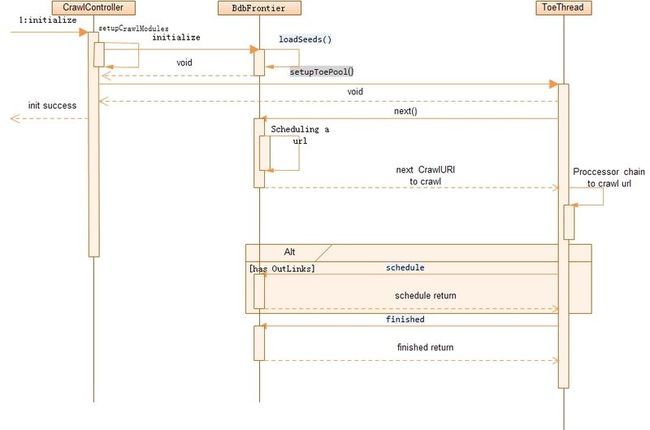
initialize :调度器初始化入口
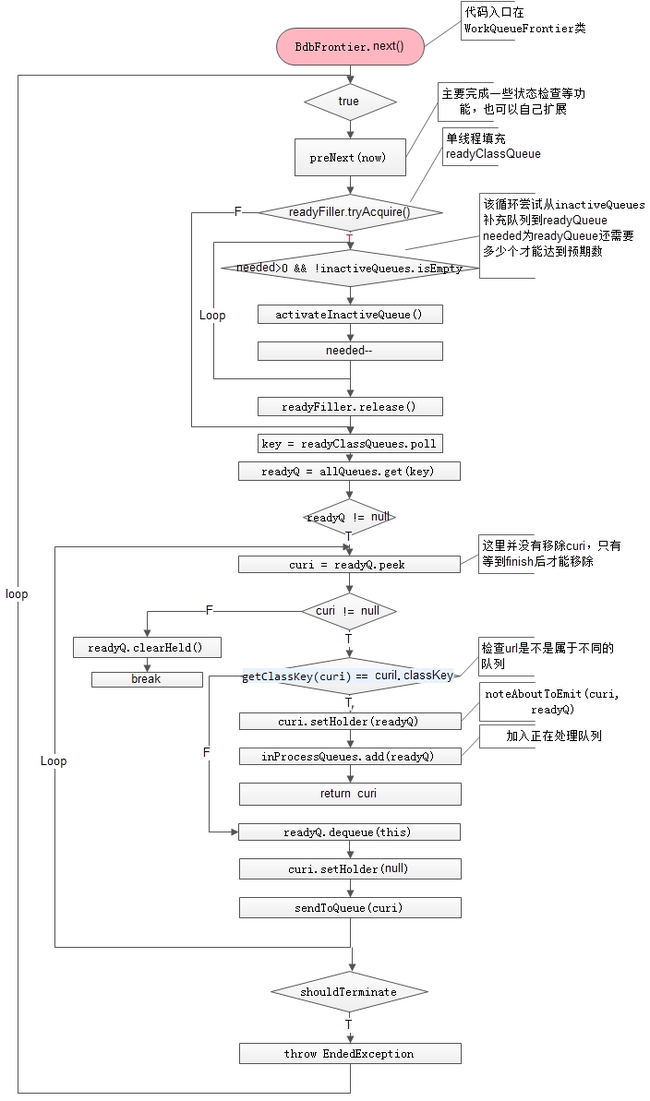
next :由抓取线程调用该方法以 获取待抓取uri
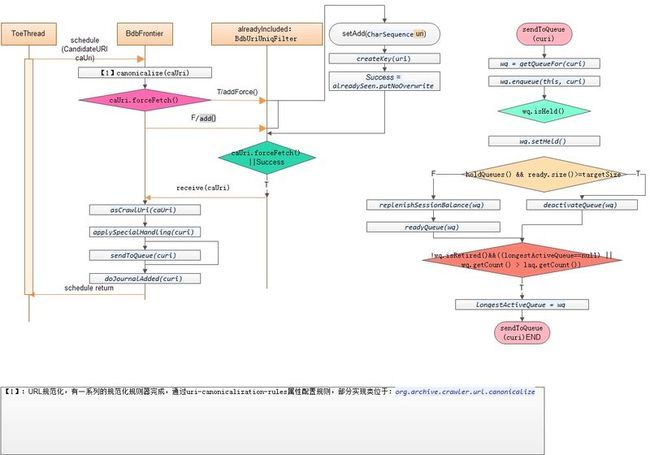
schedule :由抓取线程调用该方法以将指定需要抓取的uri加入调度器
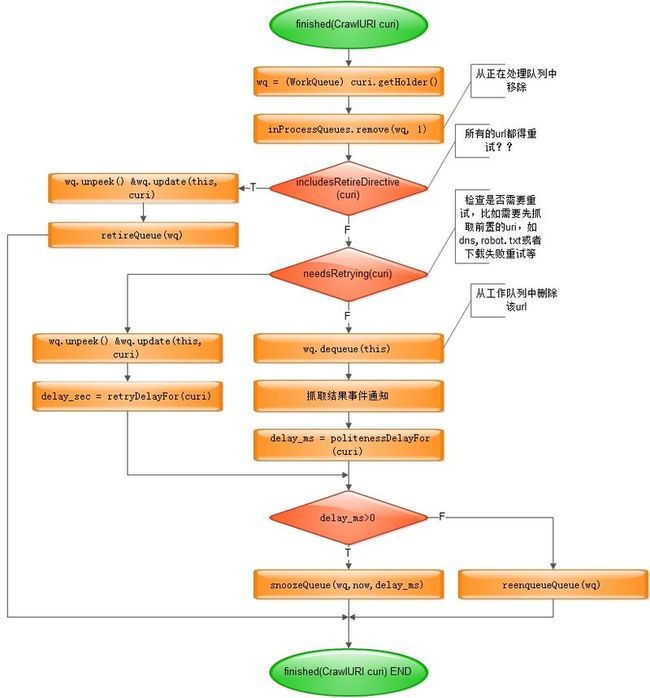
finished : 由抓取线程调用该方法以处理uri抓取结果
loadSeeds : 加载种子
start :开始工作
三. 主要的成员变量分析(BdbFrontier)
1. protected transient UriUniqFilter alreadyIncluded
protected transient UriUniqFilter alreadyIncluded;
由WorkQueueFrontier定义:
protected abstract UriUniqFilter createAlreadyIncluded() throws IOException
BdbFrontier实现:
/**
* Create a UriUniqFilter that will serve as record
* of already seen URIs.
*
* @return A UURISet that will serve as a record of already seen URIs
* @throws IOException
*/
protected UriUniqFilter createAlreadyIncluded() throws IOException {
UriUniqFilter uuf;
String c = null;
try {
c = (String)getAttribute(null, ATTR_INCLUDED);
} catch (AttributeNotFoundException e) {
// Do default action if attribute not in order.
}
// TODO: avoid all this special-casing; enable some common
// constructor interface usable for all alt implemenations
if (c != null && c.equals(BloomUriUniqFilter.class.getName())) {
uuf = this.controller.isCheckpointRecover()?
deserializeAlreadySeen(BloomUriUniqFilter.class,
this.controller.getCheckpointRecover().getDirectory()):
new BloomUriUniqFilter();
} else if (c!=null && c.equals(MemFPMergeUriUniqFilter.class.getName())) {
// TODO: add checkpointing for MemFPMergeUriUniqFilter
uuf = new MemFPMergeUriUniqFilter();
} else if (c!=null && c.equals(DiskFPMergeUriUniqFilter.class.getName())) {
// TODO: add checkpointing for DiskFPMergeUriUniqFilter
uuf = new DiskFPMergeUriUniqFilter(controller.getScratchDisk());
} else {
// Assume its BdbUriUniqFilter.
uuf = this.controller.isCheckpointRecover()?
deserializeAlreadySeen(BdbUriUniqFilter.class,
this.controller.getCheckpointRecover().getDirectory()):
new BdbUriUniqFilter(this.controller.getBdbEnvironment());
if (this.controller.isCheckpointRecover()) {
// If recover, need to call reopen of the db.
try {
((BdbUriUniqFilter)uuf).
reopen(this.controller.getBdbEnvironment());
} catch (DatabaseException e) {
throw new IOException(e.getMessage());
}
}
}
uuf.setDestination(this);
return uuf;
}
默认使用BdbUriUniqFilter实例化 BdbUriUniqFilter使用bdb数据库进行url去重,key为url的指纹,比较简单,就不惜将了。