- Heritrix网络爬虫与Tomcat服务器部署指南
Rubix-Kai
本文还有配套的精品资源,点击获取简介:Heritrix是一款功能强大的开源网络爬虫工具,由互联网档案馆开发,适用于大规模网页抓取。本文将指导读者如何下载、安装Heritrix,并在Tomcat服务器上进行部署和运行。内容包括Heritrix的基本概念、下载与安装步骤、集成到Eclipse的过程、配置Heritrix、构建与运行、部署到Tomcat以及如何访问Heritrix的Web界面。此外,还包
- Python爬虫实战
weixin_34007879
爬虫jsonjava
引言网络爬虫是抓取互联网信息的利器,成熟的开源爬虫框架主要集中于两种语言Java和Python。主流的开源爬虫框架包括:1.分布式爬虫框架:Nutch2.Java单机爬虫框架:Crawler4j,WebMagic,WebCollector、Heritrix3.python单机爬虫框架:scrapy、pyspiderNutch是专为搜索引擎设计的的分布式开源框架,上手难度高,开发复杂,基本无法满足快
- Berkeley DB JE版
jason成都
数据库
一、BerkeleyDB的介绍(1)BerkeleyDB是一个嵌入式数据库,它适合于管理海量的、简单的数据。如Google使用其来保存账户信息,Heritrix用其来保存froniter.(2)key/value是BerkeleyDB用来管理数据的基础,每个key/value对代表一条记录。(3)BerkeleyDB在底层实现采用B树,可以看成能够存储大量数据的HashMap。(4)它是Oracl
- Heritrix开源爬虫配置1.14.4和3.1
青峰祭坛
heritrix爬虫开源Heritrix
参考自:开源爬虫:Heritrix1.14.4安装/使用http://blog.sina.com.cn/s/blog_5f54f0be0101hcy8.html开源爬虫:Heritrix3.1Windows上安装/使用http://blog.sina.com.cn/s/blog_5f54f0be0101hcyt.htmlHeritrix是一个由java开发的、开源的网络爬虫,用户可以使用它来从网上
- heritrix mysql_Heritrix使用小结
有书
heritrixmysql
1.Heritrix简介Heritrix是一个专门为互联网上的网页进行存档而开发的网页检索器。它使用Java编写并且完全开源。它主要的用户界面可以通过一个web流量器来访问并通过它来控制检索器的行为,另外,它还有一个命令行工具来供用户选择调用。Heritrix是由互联网档案馆和北欧国家图书馆联合规范化编写于2003年初。第一次正式发布是在2004年1月,并不断的被互联网档案馆和其他感兴趣的第三方改
- Java爬虫技术框架之Heritrix框架详解
Heritrix是一个由Java开发的开源Web爬虫系统,用来获取完整的、精确的站点内容的深度复制,具有强大的可扩展性,运行开发者任意选择或扩展各个组件,实现特定的抓取逻辑。一、Heritrix介绍Heritrix采用了模块化的设计,用户可以在运行时选择要用的模块。它由核心类(coreclasses)和插件模块(pluggablemodules)构成。核心类可以配置,但不能被覆盖,插件模块可以由第
- Heritrix Crawler vs. Nutch Crawler
Fenng
爬虫数据库
在邮件列表中看到有人问Heritrix爬虫与Nutch爬虫的不同。搜索了一下,该项目的领导者是GordonMohr,Heritrix主要用在http://www.archive.org。基本定义描述:HeritrixistheInternetArchive’sopen-source,extensible,web-scale,archival-qualitywebcrawlerproject.没想到
- Nutch、heritrix、crawler4j优缺点
jiao732
Crawlers
Nutch:主页:https://nutch.apache.org/index.htmlApacheNutch是一个高度可扩展的和可伸缩的开源网页爬虫软件项目。源于ApacheLuceneTM,项目多样化,目前由两个代码库组成,即:1.Nutch1.x:一个非常成熟的爬虫产品。1.x版本支持细粒度的配置,依赖于一个很好的分布式处理的ApacheHadoop数据结构。2.Nutch2.x:一个新兴的
- 关于heritrix安装配置时出现"必须限制口令文件读取访问权限"的解决方法
jiangfullll
最近开始写一个RSS聚合程序,需要爬虫支持,于是就整来heritrix,没想到,这东西还挺拽,费了老衲好几个小时来安装配置这个heritrix。最后经过不懈努力,终于起来了,具体步骤如下:你如果在网上找相关配置,大多数都是讲先修改conf/properties文件的用户名和密码以及修改jmxremote.password.template,然后将其改名复制到heritrix根目录下,接着就让你无辜
- Heritrix的Modules界面不能改变选择项的问题
weixin_30455067
具体的原因分析见“Heritrix的Modules界面不能改变选择项的问题”原因:找相关的Options文件是在Modules相对路径下的,而Modules目录是在conf目录下。Classpath没有找到需要的文件目录。解决方法:在Eclipse里面设置conf为Classpath(在Eclipse的RunDialog中,Classpath标签Table,选中UserEntries,然后右边会有
- heritrix 3.2.0 -- 环境搭建
大齐zy
爬虫
heritrix作为一个比较经典的开源爬虫,写这篇文章目的是因为,3.X之后的heritrix的介绍以及配置的文章比较少了。heritrix3.x以后使用maven2配置jar包引用,但是总是有好多包没法从maven库下载。所以,这里讲的环境搭建直接使用了编译好的工程来做,heritrix-3.2.0-dist.tar.gz以及源码压缩包heritrix-3.2.0-src.tar.gz具体方法如
- 【Heritrix基础教程之2】Heritrix基本内容介绍
weixin_30487701
1、版本说明(1)最新版本:3.3.0(2)最新release版本:3.2.0(3)重要历史版本:1.14.43.1.0及之前的版本:http://sourceforge.net/projects/archive-crawler/files/3.2.0及之后的版本:http://archive.org/由于国情需要,后者无法访问,因此本blog研究的是1.14.4版本。2、官方材料source:h
- 我的Heritrix学习之路(一)
wan353694124
Heritrix
在Windows平台下,先把Heritrix启动起来详细步骤如下:1、老规矩,开源的东西,先下载,亲测地址:http://nchc.dl.sourceforge.net/project/archive-crawler/archive-crawler%20%28heritrix%201.x%29/1.14.4/heritrix-1.14.4.zip2、将下载的heritrix-1.14.4.zip解
- Heritrix的使用入门
systemuser
Hadoop
10.3扩展和定制Heritrix在前面两节中,向读者介绍了Heritrix的启动、创建任务、抓取网页、组件结构。但是,读者应该也可以明显的看出,如果不用Heritrix抓取和分析网页的行为进行一定的控制,它是无法达到要求的。对Heritrix的行为进行控制,是要建立在对其架构充分了解的基础之上的,因此,本节的内容完全是基于上一节中所讨论的基础。10.3.1向Heritrix中添加自己的Extra
- heritrix学习总结
蓝翔招生办
网络爬虫
1下载和解压从[url]http://crawler.archive.org/[/url]下载解压到本地E:\heritrix-1.14.32配置环境变量HERITRIX_HOME=E:\heritrix-1.14.3path后追加;%HERITRIX_HOME%\bin3配置heritrix拷贝E:\heritrix-1.14.3\conf\jmxremote.password.template
- Heritrix3.1.0的使用
jiang617325814
java开源包
1.在cmd下面进入Heritrix的bin目录下输入heritrix-aadmin:admin,弹出新窗口,新窗口中运行heritrix2.浏览中输入https://localhost:8443/得到界面如下第一个输入框中写入任意Job名称,如s第二个输入框如果不写则默认存储在bin目录下的jobs文件夹下3.点击create后:4.点击"s"任务:crawler-beans.cxml是配置本次
- Heritrix3.0 的安装,使用
jazwoo
搜索引擎
1、下载heritrix3.0或heritrix3.1,解压。运行cmd,进入到bin目录下(如笔者的目录:cdD:\heritrix-3.1.0\bin)。运行命令:heritrix-aadmin:admin,这里冒号前面admin是用户名,后面是密码,这样将会在另一个新建的窗口中运行heritrix程序。在浏览器地址栏输入https://localhost:8443,注意这里是https,端口
- Heritrix
iteye_14258
网络爬虫
Heritrix项目介绍Heritrix工程始于2003年初,IA的目的是开发一个特殊的爬虫,对网上的资源进行归档,建立网络数字图书馆。在过去的6年里,IA已经建立了400TB的数据。IA期望他们的crawler包含以下几种:宽带爬虫:能够以更高的带宽去站点爬。主题爬虫:集中于被选择的问题。持续爬虫:不仅仅爬更当前的网页还负责爬日后更新的网页。实验爬虫:对爬虫技术进行实验,以决定该爬什么,以及对不
- Heritrix3.0教程 使用入门(三) 配置文件crawler-beans.cxml介绍
iteye_1364
Heritrix
本博客属原创文章,转载请注明出处:http://www.yun5u.com/articles/heritrix3-4.html可以说crawler-beans.cxml可以主导整个Heritrix的抓取.不同于Heritrix1.x版本的order.xml是,crawler-beans.cxml采用Spring来管理.里面的配置都是一个个bean.所以无论从配置上,耦合上,动态控制上,Heritr
- Heritrix3.0教程 使用入门(一) 下载安装与运行
iteye_1364
Heritrix
本博客属原创文章,转载请注明出处:http://www.yun5u.com/articles/heritrix3-1.htmlHeritrix3.0.0在2009年底发布,但资料甚少.我这里就先抛砖引用,以前也分析过Heritrix1.4.3,但只是源码,不系统.这里就系统的介绍Heritrix的使用,源码分析和借鉴.先介绍Heritrix的下载与使用吧.1.下载,下载地址:http://sour
- Heritrix3.0教程 使用教程(三) CrawlJob控制台界面(一) 大概介绍
iteye_1364
Heritrix
本博客属原创文章,转载请注明出处:http://www.yun5u.com/articles/heritrix3-5.html我觉得Heritrix很直观的一点就是有控制台,但以前我忽略了这个功能,直接代码启动Heritrix,然后放在Tomcat里.后期才慢慢发现一个UI界面的价值.可以很方便的获知抓取情况,甚至完全在千里之外控制它的抓取.其实慢慢的发现很多开源框架都会有一个UI界面.我觉得这也
- 【Heritrix基础教程之1】在Eclipse中配置Heritrix
apple01010105
一、新建项目并将Heritrix源码导入1、下载heritrix-1.14.4-src.zip和heritrix-1.14.4.zip两个压缩包,并解压,以后分别简称SRC包和ZIP包;2、在Eclipse下新建Java项目,取名Heritrix.1.14.4;3、复制SRC包下面src/java文件夹下org和st两个文件夹到项目中的src包下;4、复制SRC包下src下conf文件夹到项目根目
- 【Heritrix基础教程之3】Heritrix的基本架构
apple01010105
运维java测试
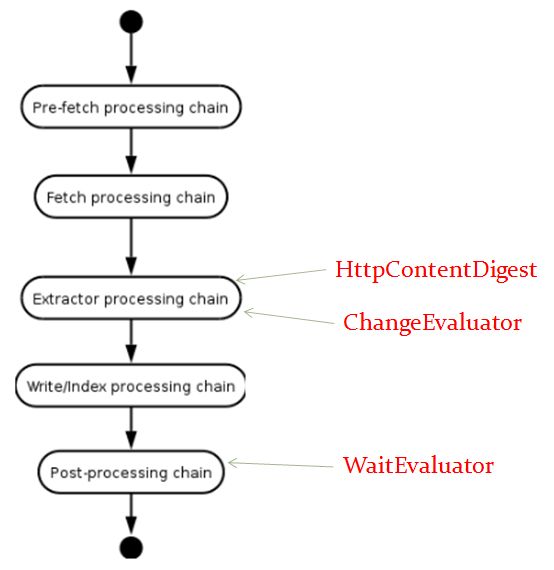
Heritrix可分为四大模块:1、控制器CrawlController2、待处理的uri列表Frontier3、线程池ToeThread4、各个步骤的处理器(1)Pre-fetchprocessingchain:主要处理DNS-lookup,robots.txt,认证,抓取范围检查等。(2)FetchProcessingchain:抓取处理器。对于每个协议,均有一个类作支持,如FetchHTTP
- Heritrix3.0教程 使用入门(二) 开始抓取
沐枫L
Heritrix3
本博客属原创文章,转载请注明出处:http://www.yun5u.com/articles/heritrix3-2.html上一篇博客介绍了,Heritrix3.0的下载,安装以及启动,可以通过UI去配置,和控制抓取任务.这一篇博将讲述,如何在Heritrix上创建抓取任务(CrawlJob)并运行.首先创建抓取,本可以通过WEB界面来创建,但有时会出现一些莫名奇妙的问题,我这里通过手工创建的方
- Heritrix3.0教程 使用入门(一) 下载安装与运行
沐枫L
Heritrix3jobs任务浏览器cmdieweb
本博客属原创文章,转载请注明出处:http://www.yun5u.com/articles/heritrix3-1.htmlHeritrix3.0.0在2009年底发布,但资料甚少.我这里就先抛砖引用,以前也分析过Heritrix1.4.3,但只是源码,不系统.这里就系统的介绍Heritrix的使用,源码分析和借鉴.先介绍Heritrix的下载与使用吧.1.下载,下载地址:http://sour
- 爬虫初探(一)crawler4j的robots
weixin_34123613
2019独角兽企业重金招聘Python工程师标准>>>最近刚刚开始研究爬虫,身为小白的我不知道应该从何处下手,网上查了查,发现主要的开源java爬虫有nutchapache/nutch·GitHub,Heritrixinternetarchive/heritrix3·GitHub和Crawler4jyasserg/crawler4j·GitHub,还有WebCollectorCrawlScript
- Lucene+Heritrix 开发搜索引擎
iteye_4245
搜索引擎lucene互联网
摘要:根据搜索引擎原理,Heritrix从互联网上抓取网页,Lucene建立索引数据库,在索引数据库中搜索排序.阅读全文jwebee2007-05-2420:09发表评论
- Heritrix源码分析(二) 配置文件order.xml介绍
nizaina_0
Heritrix
本博客属原创文章,欢迎转载!转载请务必注明出处:http://guoyunsky.iteye.com/blog/613412本博客已迁移到本人独立博客:http://www.yun5u.com/order.xml是整个Heritrix的核心,里面的每个一个配置都关系到Heritrix的运行情况,没读源码之前我只能从有限的渠道去获知这些配置的运用.读完之后才知道Heritrix竟然有如此灵活的运用,
- Web爬虫Heritrix的安装和配置
Rayping
爬虫爬虫人工智能
Web爬虫Heritrix的安装和配置2010-10-2720:00:01|分类:Web搜索|字号订阅1、将得到的heritrix-1.14.4.zip压缩包直接解压缩到某一目录,我选择的是F:\Heritrix。2、然后,将F:\Heritrix目录中的heritrix-1.14.4.jar文件解压缩,把profiles\default下的两个文件order.xml和seeds.txt复制到F:
- 开源爬虫: Heritrix 3.1 Windows 上安装/使用
xiaomin_____
java
目前Heritrix的最新版本是3.1.0(2011-10-21发布)http://blog.sina.com.cn/s/blog_5f54f0be0101hcy8.html讲了1.14.4版本的安装和使用http://blog.sina.com.cn/s/blog_5f54f0be0101hcyd.html讲了如何扩展1.14.4版本其中的模块本文讲如何安装和使用Heritrix最新的3.1.0
- 多线程编程之存钱与取钱
周凡杨
javathread多线程存钱取钱
生活费问题是这样的:学生每月都需要生活费,家长一次预存一段时间的生活费,家长和学生使用统一的一个帐号,在学生每次取帐号中一部分钱,直到帐号中没钱时 通知家长存钱,而家长看到帐户还有钱则不存钱,直到帐户没钱时才存钱。
问题分析:首先问题中有三个实体,学生、家长、银行账户,所以设计程序时就要设计三个类。其中银行账户只有一个,学生和家长操作的是同一个银行账户,学生的行为是
- java中数组与List相互转换的方法
征客丶
JavaScriptjavajsonp
1.List转换成为数组。(这里的List是实体是ArrayList)
调用ArrayList的toArray方法。
toArray
public T[] toArray(T[] a)返回一个按照正确的顺序包含此列表中所有元素的数组;返回数组的运行时类型就是指定数组的运行时类型。如果列表能放入指定的数组,则返回放入此列表元素的数组。否则,将根据指定数组的运行时类型和此列表的大小分
- Shell 流程控制
daizj
流程控制if elsewhilecaseshell
Shell 流程控制
和Java、PHP等语言不一样,sh的流程控制不可为空,如(以下为PHP流程控制写法):
<?php
if(isset($_GET["q"])){
search(q);}else{// 不做任何事情}
在sh/bash里可不能这么写,如果else分支没有语句执行,就不要写这个else,就像这样 if else if
if 语句语
- Linux服务器新手操作之二
周凡杨
Linux 简单 操作
1.利用关键字搜寻Man Pages man -k keyword 其中-k 是选项,keyword是要搜寻的关键字 如果现在想使用whoami命令,但是只记住了前3个字符who,就可以使用 man -k who来搜寻关键字who的man命令 [haself@HA5-DZ26 ~]$ man -k
- socket聊天室之服务器搭建
朱辉辉33
socket
因为我们做的是聊天室,所以会有多个客户端,每个客户端我们用一个线程去实现,通过搭建一个服务器来实现从每个客户端来读取信息和发送信息。
我们先写客户端的线程。
public class ChatSocket extends Thread{
Socket socket;
public ChatSocket(Socket socket){
this.sock
- 利用finereport建设保险公司决策分析系统的思路和方法
老A不折腾
finereport金融保险分析系统报表系统项目开发
决策分析系统呈现的是数据页面,也就是俗称的报表,报表与报表间、数据与数据间都按照一定的逻辑设定,是业务人员查看、分析数据的平台,更是辅助领导们运营决策的平台。底层数据决定上层分析,所以建设决策分析系统一般包括数据层处理(数据仓库建设)。
项目背景介绍
通常,保险公司信息化程度很高,基本上都有业务处理系统(像集团业务处理系统、老业务处理系统、个人代理人系统等)、数据服务系统(通过
- 始终要页面在ifream的最顶层
林鹤霄
index.jsp中有ifream,但是session消失后要让login.jsp始终显示到ifream的最顶层。。。始终没搞定,后来反复琢磨之后,得到了解决办法,在这儿给大家分享下。。
index.jsp--->主要是加了颜色的那一句
<html>
<iframe name="top" ></iframe>
<ifram
- MySQL binlog恢复数据
aigo
mysql
1,先确保my.ini已经配置了binlog:
# binlog
log_bin = D:/mysql-5.6.21-winx64/log/binlog/mysql-bin.log
log_bin_index = D:/mysql-5.6.21-winx64/log/binlog/mysql-bin.index
log_error = D:/mysql-5.6.21-win
- OCX打成CBA包并实现自动安装与自动升级
alxw4616
ocxcab
近来手上有个项目,需要使用ocx控件
(ocx是什么?
http://baike.baidu.com/view/393671.htm)
在生产过程中我遇到了如下问题.
1. 如何让 ocx 自动安装?
a) 如何签名?
b) 如何打包?
c) 如何安装到指定目录?
2.
- Hashmap队列和PriorityQueue队列的应用
百合不是茶
Hashmap队列PriorityQueue队列
HashMap队列已经是学过了的,但是最近在用的时候不是很熟悉,刚刚重新看以一次,
HashMap是K,v键 ,值
put()添加元素
//下面试HashMap去掉重复的
package com.hashMapandPriorityQueue;
import java.util.H
- JDK1.5 returnvalue实例
bijian1013
javathreadjava多线程returnvalue
Callable接口:
返回结果并且可能抛出异常的任务。实现者定义了一个不带任何参数的叫做 call 的方法。
Callable 接口类似于 Runnable,两者都是为那些其实例可能被另一个线程执行的类设计的。但是 Runnable 不会返回结果,并且无法抛出经过检查的异常。
ExecutorService接口方
- angularjs指令中动态编译的方法(适用于有异步请求的情况) 内嵌指令无效
bijian1013
JavaScriptAngularJS
在directive的link中有一个$http请求,当请求完成后根据返回的值动态做element.append('......');这个操作,能显示没问题,可问题是我动态组的HTML里面有ng-click,发现显示出来的内容根本不执行ng-click绑定的方法!
- 【Java范型二】Java范型详解之extend限定范型参数的类型
bit1129
extend
在第一篇中,定义范型类时,使用如下的方式:
public class Generics<M, S, N> {
//M,S,N是范型参数
}
这种方式定义的范型类有两个基本的问题:
1. 范型参数定义的实例字段,如private M m = null;由于M的类型在运行时才能确定,那么我们在类的方法中,无法使用m,这跟定义pri
- 【HBase十三】HBase知识点总结
bit1129
hbase
1. 数据从MemStore flush到磁盘的触发条件有哪些?
a.显式调用flush,比如flush 'mytable'
b.MemStore中的数据容量超过flush的指定容量,hbase.hregion.memstore.flush.size,默认值是64M 2. Region的构成是怎么样?
1个Region由若干个Store组成
- 服务器被DDOS攻击防御的SHELL脚本
ronin47
mkdir /root/bin
vi /root/bin/dropip.sh
#!/bin/bash/bin/netstat -na|grep ESTABLISHED|awk ‘{print $5}’|awk -F:‘{print $1}’|sort|uniq -c|sort -rn|head -10|grep -v -E ’192.168|127.0′|awk ‘{if($2!=null&a
- java程序员生存手册-craps 游戏-一个简单的游戏
bylijinnan
java
import java.util.Random;
public class CrapsGame {
/**
*
*一个简单的赌*博游戏,游戏规则如下:
*玩家掷两个骰子,点数为1到6,如果第一次点数和为7或11,则玩家胜,
*如果点数和为2、3或12,则玩家输,
*如果和为其它点数,则记录第一次的点数和,然后继续掷骰,直至点数和等于第一次掷出的点
- TOMCAT启动提示NB: JAVA_HOME should point to a JDK not a JRE解决
开窍的石头
JAVA_HOME
当tomcat是解压的时候,用eclipse启动正常,点击startup.bat的时候启动报错;
报错如下:
The JAVA_HOME environment variable is not defined correctly
This environment variable is needed to run this program
NB: JAVA_HOME shou
- [操作系统内核]操作系统与互联网
comsci
操作系统
我首先申明:我这里所说的问题并不是针对哪个厂商的,仅仅是描述我对操作系统技术的一些看法
操作系统是一种与硬件层关系非常密切的系统软件,按理说,这种系统软件应该是由设计CPU和硬件板卡的厂商开发的,和软件公司没有直接的关系,也就是说,操作系统应该由做硬件的厂商来设计和开发
- 富文本框ckeditor_4.4.7 文本框的简单使用 支持IE11
cuityang
富文本框
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<title>知识库内容编辑</tit
- Property null not found
darrenzhu
datagridFlexAdvancedpropery null
When you got error message like "Property null not found ***", try to fix it by the following way:
1)if you are using AdvancedDatagrid, make sure you only update the data in the data prov
- MySQl数据库字符串替换函数使用
dcj3sjt126com
mysql函数替换
需求:需要将数据表中一个字段的值里面的所有的 . 替换成 _
原来的数据是 site.title site.keywords ....
替换后要为 site_title site_keywords
使用的SQL语句如下:
updat
- mac上终端起动MySQL的方法
dcj3sjt126com
mysqlmac
首先去官网下载: http://www.mysql.com/downloads/
我下载了5.6.11的dmg然后安装,安装完成之后..如果要用终端去玩SQL.那么一开始要输入很长的:/usr/local/mysql/bin/mysql
这不方便啊,好想像windows下的cmd里面一样输入mysql -uroot -p1这样...上网查了下..可以实现滴.
打开终端,输入:
1
- Gson使用一(Gson)
eksliang
jsongson
转载请出自出处:http://eksliang.iteye.com/blog/2175401 一.概述
从结构上看Json,所有的数据(data)最终都可以分解成三种类型:
第一种类型是标量(scalar),也就是一个单独的字符串(string)或数字(numbers),比如"ickes"这个字符串。
第二种类型是序列(sequence),又叫做数组(array)
- android点滴4
gundumw100
android
Android 47个小知识
http://www.open-open.com/lib/view/open1422676091314.html
Android实用代码七段(一)
http://www.cnblogs.com/over140/archive/2012/09/26/2611999.html
http://www.cnblogs.com/over140/arch
- JavaWeb之JSP基本语法
ihuning
javaweb
目录
JSP模版元素
JSP表达式
JSP脚本片断
EL表达式
JSP注释
特殊字符序列的转义处理
如何查找JSP页面中的错误
JSP模版元素
JSP页面中的静态HTML内容称之为JSP模版元素,在静态的HTML内容之中可以嵌套JSP
- App Extension编程指南(iOS8/OS X v10.10)中文版
啸笑天
ext
当iOS 8.0和OS X v10.10发布后,一个全新的概念出现在我们眼前,那就是应用扩展。顾名思义,应用扩展允许开发者扩展应用的自定义功能和内容,能够让用户在使用其他app时使用该项功能。你可以开发一个应用扩展来执行某些特定的任务,用户使用该扩展后就可以在多个上下文环境中执行该任务。比如说,你提供了一个能让用户把内容分
- SQLServer实现无限级树结构
macroli
oraclesqlSQL Server
表结构如下:
数据库id path titlesort 排序 1 0 首页 0 2 0,1 新闻 1 3 0,2 JAVA 2 4 0,3 JSP 3 5 0,2,3 业界动态 2 6 0,2,3 国内新闻 1
创建一个存储过程来实现,如果要在页面上使用可以设置一个返回变量将至传过去
create procedure test
as
begin
decla
- Css居中div,Css居中img,Css居中文本,Css垂直居中div
qiaolevip
众观千象学习永无止境每天进步一点点css
/**********Css居中Div**********/
div.center {
width: 100px;
margin: 0 auto;
}
/**********Css居中img**********/
img.center {
display: block;
margin-left: auto;
margin-right: auto;
}
- Oracle 常用操作(实用)
吃猫的鱼
oracle
SQL>select text from all_source where owner=user and name=upper('&plsql_name');
SQL>select * from user_ind_columns where index_name=upper('&index_name'); 将表记录恢复到指定时间段以前
- iOS中使用RSA对数据进行加密解密
witcheryne
iosrsaiPhoneobjective c
RSA算法是一种非对称加密算法,常被用于加密数据传输.如果配合上数字摘要算法, 也可以用于文件签名.
本文将讨论如何在iOS中使用RSA传输加密数据. 本文环境
mac os
openssl-1.0.1j, openssl需要使用1.x版本, 推荐使用[homebrew](http://brew.sh/)安装.
Java 8
RSA基本原理
RS