Hibernate学习笔记!
Hibernate 是一个开放源代码的对象关系映射框架,它对 JDBC 进行了轻量级的对象封装,使 Java 程序员可以随心所欲的使用对象编程思维来操纵数据库。它不仅提供了从 Java 类到数据表之间的映射,也提供了数据查询和恢复机制。相对于使用 JDBC 和 SQL 来手工操作数据库,Hibernate 可以大大减少操作数据库的工作量。 另外 Hibernate 可以利用代理模式来简化载入类的过程,这将大大减少利用 Hibernate QL 从数据库提取数据的代码的编写量,从而节约开发时间和开发成本 Hibernate 可以和多种Web 服务器或者应用服务器良好集成,如今已经支持几乎所有的流行的数据库服务器。
Hibernate 简单介绍与图示原理
http://hi.baidu.com/verdana/blog/item/1eddd43f73dbbac27d1e71c1.html
简单说说 hibernate 的原理
http://www.21jn.net/html/80/n-1180.html
Hibernate 与传统 Java 软件架构的对比
http://hi.baidu.com/verdana/blog/item/796033fa56c5b81ea8d311c0.html
1、SessionFactory:
Configuration的实例会根据当前的配置信息,构造SessionFactory实例。SessionFactory是线程安全的,一般情况下一个应用中一个数据库共享一个SessionFactory实例。
构建SessionFactory
Hibernate 的SessionFactory接口提供Session类的实例,Session类用于完成对数据库的操作。由于SessionFactory实例是线程安全的(而Session实例不是线程安全的) ,所以每个操作都可以共用同一个SessionFactory来获取Session。
从XML文件读取配置信息构建SessionFactory:
(1)创建一个Configuration对象,并通过该对象的configura()方法加载Hibernate配置文件,代码如下。
Configuration config = new Configuration().configure();
configure() 方法:用于告诉Hibernate加载hibernate.cfg.xml文件。Configuration在实例化时默认加载classpath中的 hibernate.cfg.xml,当然也可以加载名称不是hibernate.cfg.xml的配置文件,例如 wghhibernate.cfg.xml,可以通过以下代码实现。
Configuration config = new Configuration().configure("wghhibernate.cfg.xml");
public class AppManager extends ContextLoaderListener implements
ServletContextListener {
private ServletContext context;
private WebApplicationContext webApplicationContext;
public void contextDestroyed(ServletContextEvent sce) {
Enumeration<String> enumeration = this.context.getAttributeNames();
while (enumeration.hasMoreElements()) {
context.removeAttribute(enumeration.nextElement());
}
}
public void contextInitialized(ServletContextEvent sce) {
this.context = sce.getServletContext();
this.webApplicationContext = WebApplicationContextUtils.getRequiredWebApplicationContext(context);
this.context.setAttribute("WEBAPPLICATIONCONTEXT", webApplicationContext);
String path = this.context.getRealPath(this.context.getInitParameter("configUrl"));
ConfigurationFactory factory = new ConfigurationFactory(path);
Configuration config = factory.getConfiguration();
this.context.setAttribute(MyConstants.CONFIGURATION_KEY, config);
}
}
(2)完成配置文件和映射文件的加载后,将得到一个包括所有Hibernate运行期参数的Configuration实例,通过Configuration实例的buildSessionFactory()方法可以构建一个惟一的SessionFactory,代码如下。
SessionFactory sessionFactory = config.buildSessionFactory();
构建SessionFactory要放在静态代码块中,因为它只在该类被加载时执行一次。 一个典型的构建SessionFactory的代码如下。
private static SessionFactory sessionFactory = null;
static {
try {
Configuration cfg = new Configuration().configure();
sessionFactory = cfg.buildSessionFactory();
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
}
2、 了解 get和load的区别?
* get不支持lazy,load支持lazy
* 采用get加载数据,如果没有匹配的数据,返回null,而load则抛出异常
3、hibernate中Java对象的三种状态
临时状态transient:
* 在数据库中没有与之匹配的数据
* 没有纳入session的管理
持久状态persistent:
* 在数据库中有与对应的数据
* 纳入了session的管理
* 在清理缓存(脏数据检查)的时候,会和数据库同步
持久的实例在数据库中有对应的记录,并拥有一个持久化标识 (identifier).
持久对象总是与 Session 和 Transaction 相关联,在一个 Session 中,对持久对象的改变不会马上对数据库进行变更,而必须在 Transaction 终止,也就是执行 commit() 之后,才在数据库中真正运行 SQL 进行变更,持久对象的状态才会与数据库进行同步。在同步之前的持久对象称为脏 (dirty) 对象。
游离(脱管状态)detached:
* 在数据库中还可能存在一条与它对应的记录
* 不再纳入session的管理 中
与持久对象关联的 Session 被关闭后,对象就变为脱管对象。对脱管对象的引用依然有效,对象可继续被修改。
脱管对象特点:
(1) 本质上和瞬时对象相同
(2) 只是比瞬时对象多了一个数据库记录标识值 id.
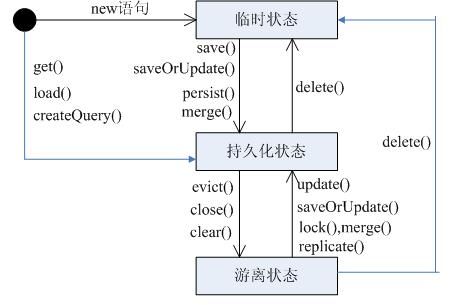
持久对象转为脱管对象:
当执行 close() 或 clear(),evict() 之后,持久对象会变为脱管对象。
瞬时(临时)对象转为持久对象:
(1) 通过 Session 的 save() 和 saveOrUpdate() 方法把一个瞬时对象与数据库相关联,这个瞬时对象就成为持久化对象。
(2) 使用 find(),get(),load() 和 iterater() 待方法查询到的数据对象,将成为持久化对象。
上述 3 个状态之间是可以相互转化的,而且 我们所说的状态都是针对某一个session实例而言的 ,比方说,对象 A 对于 session1 而言是处于持久化状态的,因为它处于 session1 的缓存中,但是对于 session2 而言对象 A 并不在它的缓存中,因此它是处于游离状态的。
持久状态的对象发生变化会自动同步到数据库:
结合 save(),update(),saveOrUpdate() 方法说明对象的状态
(1)Save() 方法将瞬时对象保存到数据库,对象的临时状态将变为持久化状态。当对象在持久化状态时,它一直位于 Session 的缓存中,对它的任何操作在事务提交时都将同步到数据库,因此,对一个已经持久的对象调用 save() 或 update() 方法是没有意义的。如:
Student stu = new Strudnet();
stu.setCarId(“200234567”);
stu.setId(“100”);
// 打开 Session, 开启事务
session.save(stu);
stu.setCardId(“20076548”);
session.save(stu); // 无效
session.update(stu); // 无效
// 提交事务,关闭 Session
(2)update() 方法两种用途重新关联脱管对象为持久化状态对象,显示调用 update() 以更新对象。调用 update() 只为了关联一个脱管对象到持久状态,当对象已经是持久状态时,调用 update() 就没有多大意义了。如:
// 打开 session ,开启事务
stu = (Student)session.get(Student.class,”123456”);
stu.setName(“Body”);
session.update(stu); // 由于 stu 是持久对象,必然位于 Session 缓冲中,对 stu 所做的变更将
// 被同步到数据库中。所以 update() 是没有意义的,可以不要这句效果一样的。
对于脱管对象而言,Hibernate 总是执行 update 语句,不管这个脱管对象在离开 Session 之后有没有更改过,在清理缓存时 Hibernate 总是发送一条 update 语句,以确保脱管对象和数据库记录的数据一致 ,如:
Student stu = new Strudnet();
stu.setCarId(“1234”);
// 打开 Session1, 开启事务
session1.save(stu);
// 提交事务,关闭 Session1
stu.set(“4567”); // 对脱管对象进行更改
// 打开 Session2, 开启事务
session2.update(stu);
// 提交事务,关闭 Session2
注:即使把 session2.update(stu); 这句去掉,提交事务时仍然会执行一条 update() 语句。
如果希望只有脱管对象改变了, Hibernate 才生成 update 语句,可以把映射文件中 <class> 标签的 select-before-update 设为 true, 这种会先发送一条 select 语句取得数据库中的值,判断值是否相同,如果相同就不执行 update 语句。不过这种做法有一定的缺点,每次 update 语句之前总是要发送一条多余的 select 语句,影响性能。对于偶尔更改的类,设置才是有效的,对于经常要更改的类这样做是影响效率的。
(3)saveOrUpdate() 方法兼具 save() 和 update() 方法的功能,对于传入的对象, saveOrUpdate() 首先判断其是脱管对象还是临时对象,然后调用合适的方法。
关于Session接口的update方法主要有如下几点要注意:
1.输入参数
一般而言,传递给update的对象要是处于游离状态的对象。如果传一个持久化对象,那么update方法就是多余的 ,因为Hibernate的脏检查机制会自动根据对象属性值的变化向数据库发送一条update语句;如果传入的对象处于临时状态,那么此时Hibernate应该会抛出异常。因为Hibernate在更新数据时会根据对象的OID去数据库查找相应的记录并更新之,而在数据库中是没有记录与这个临时对象相关联的 ,因此Hibernate会抛出异常,当然如果你人为的给临时对象指定一个OID就该另当别论了,如下所示代码片段:
Customer customer=new Customer();
customer.setId(3L);
customer.setName(“Cindyelf”);
session.update(customer);
这段代码会导致如下的sql:update Customer set name=’Cindyelf’ where id=3;当然如果数据库不存在id为3的那行记录,Hibernate就会抛出异常。而给临时对象指定OID是不合规范的操作,应尽量避免。也就是说不管传入是什么状态对象,数据库中必须要有一条记录与这个对象的OID相对应,否则抛出异常。
2.操作
执行update方法的时候,Hibernate会首先把传入的对象放入Session的缓存中,使之持久化,然后计划执行一个update语句。Hibernate在生成sql语句的时候会根据对象的当前属性值来组装sql语句,也就是说,不管程序中修改了多少次属性值,在执行时只会执行一条update一句。
此外,在update的官方API中特意强调了一点,“如果在session的缓存中有一个持久化对象和所要更新的对象具有相同的OID,那么Hibernate会抛出异常”。下面的代码片段演示了这个错误:
Customer customer=new Customer();
session1.save(customer);
Customer customer1=(Customer)session.load(Customer.class,new Long(6))
session2.update(customer);
如上所示,我在session1中持久化了一个Customer对象,它的OID是6,然后我在session2中load一个OID为6的对象customer1,然后在session2中update之前的customer,注意,对于session2而已,customer1是处于游离状态的,因为它不处于session2的缓存中。此时程序会报如下错误:a different object with the same identifier value was already associated with the session。
session.flush与transaction.commit:
以session的save方法为例来看一个简单、完整的事务流程,如下是代码片段:
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
session.save(customer);//之前已实例化好了的一个对象
tx.commit();
示例很简单,就是向数据库中插入一条顾客信息,这是一个最简单的数据库事务。在这个简单的过程中,Hibernate为我们做了一些什么事情呢?为了更好的观察,我们将Hibernate的”show_sql”属性设置为true,然后运行我们的程序,控制台打印出如下信息:
Hibernate: select max(ID) from CUSTOMER
Hibernate: insert into CUSTOMER (NAME, EMAIL, PASSWORD, PHONE, ADDRESS, SEX, IS_MARRIED, description, BIRTHDAY, REGISTERED_TIME, ID) values (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
这里也许看不出什么端倪来,现在在session.save(customer)后面加一行代码,输出这个customer的OID,System.out.println(customer.getId()),再次运行程序,控制台输出为:
Hibernate: select max(ID) from CUSTOMER
22
Hibernate: insert into CUSTOMER (NAME, EMAIL, PASSWORD, PHONE, ADDRESS, SEX, IS_MARRIED, description, BIRTHDAY, REGISTERED_TIME, ID) values (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
OID在insert语句之前输出,这可以说明两个问题:1.insert语句并不是在执行save的时候发送给数据库的;2.insert语句是在执行commit的时候发送给数据库的 。结合前面我们所说过的:执行save的时候,Hibernate会首先把对象放入缓存,然后计划一条insert语句。一个基本的插入流程就出来了:
1. 判断所要保存的实例是否已处于持久化状态,如果不是,则将其置入缓存;
2. 根据所要保存的实例计划一条insert sql语句,注意只是计划,并不执行;
3. 事务提交时执行之前所计划的insert语句;
后台还打印出了select max(ID) from CUSTOMER,这主要是为了给customer赋予一个OID,因为一般情况下临时对象的OID是NULL。
接着我们做两个测试:
1. 将tx.commit();注释掉,此时控制台没有打印出insert语句;
2. 将tx.commit()换成session.flush,此时控制太打印出了insert语句,但是数据库中并没有添加新的记录;
通过查阅Hibernate的API可以知道flush方法的主要作用就是清理缓存,强制数据库与Hibernate缓存同步,以保证数据的一致性。它的主要动作就是向数据库发送一系列的sql语句,并执行这些sql语句,但是不会向数据库提交 。而commit方法则会首先调用flush方法,然后提交事务。这就是为什么我们仅仅调用flush的时候记录并未插入到数据库中的原因,因为只有提交了事务,对数据库所做的更新才会被保存下来。因为commit方法隐式的调用了flush,所以一般我们都不会显示的调用flush方法。
http://blog.csdn.net/CMTobby/archive/2007/08/11/1738392.aspx
4、单向关联与双向关联的区别:
单向:
只能通过A查询B,或者B查询A
双向:
既可以通过A查询B,也可以通过B查询A
如果只单向关联~A one to many B~
当hibernate查询A的时候回自动加载相关的B~ 用A.getBorder()之类的就能得到B~(看你设置的方法是什么就是什么~打比方是getBorder())
当查询B的时候~不会加载A~也就是说从B中是读不到A的~没有B.getAorder()之类的方法在B类里~
双向关联就是~查询A会自动加载B~用A类相应方法得到A类相应的B类~
同时查询B也会自动加载A类~用B类相应方法得到B类相应的A类~
5、延迟加载:
当真正使用的时候,才发出SQL语句
lazy只有 session打开状态下才有效
使用缓存的一个很明显的好处就是可以减少数据库访问的频率,提高应用程序的性能,因为从内存中读取数据显然要比从数据库中查询快多了。
Hibernate与延迟加载
Hibernate对象关系映射提供延迟的与非延迟的对象初始化。非延迟加载在读取一个对象的时候会将与这个对象所有相关的其他对象一起读取出来 。这有时会导致成百的(如果不是成千的话)select语句在读取对象的时候执行。这个问题有时出现在使用双向关系的时候,经常会导致整个数据库都在初始化的阶段被读出来了。当然,你可以不厌其烦地检查每一个对象与其他对象的关系,并把那些最昂贵的删除,但是到最后,我们可能会因此失去了本想在ORM工具中获得的便利。
一个明显的解决方法是使用Hibernate提供的延迟加载机制 。这种初始化策略只在一个对象调用它的一对多或多对多关系时才将关系对象读取出来 。这个过程对开发者来说是透明的,而且只进行了很少的数据库操作请求,因此会得到比较明显的性能提升。这项技术的一个缺陷是延迟加载技术要求一个Hibernate会话要在对象使用的时候一直开着。这会成为通过使用DAO模式将持久层抽象出来时的一个主要问题。为了将持久化机制完全地抽象出来,所有的数据库逻辑,包括打开或关闭会话,都不能在应用层出现。最常见的是,一些实现了简单接口的DAO实现类将数据库逻辑完全封装起来了。一种快速但是笨拙的解决方法是放弃DAO模式,将数据库连接逻辑加到应用层中来。这可能对一些小的应用程序有效,但是在大的系统中,这是一个严重的设计缺陷,妨碍了系统的可扩展性。
spring的容器是提供了lazy-load的,即默认的缺省设置是bean没有lazy-load,该属性处于false状态,这样导致spring 在启动过程导致在启动时候,会默认加载整个对象实例图,从初始化ACTION配置、到service配置到dao配置、乃至到数据库连接、事务等等。
把beans的default-lazy-init改为true的话,spring在启动的时候并没有真正实例化对象,而只是用一个代理来实现。当真正需要调用该类的时候,才会去实例化
不是说有的beans都能设置default-lazy-init成为true.对于scheduler的bean不能用lazy-init
Hibernate习题总结:
一、Hibernate工作原理:
1. 读取并解析配置文件
2. 读取并解析映射信息,创建SessionFactory
3. 打开Sesssion
4. 创建事务Transation
5. 持久化操作
6. 提交事务
7. 关闭Session
8. 关闭SesstionFactory
二、Hibernate有什么好处:
* 对JDBC访问数据库的代码做了封装 ,大大简化了数据访问层繁琐的重复性代码。
* Hibernate是一个基于JDBC的主流持久化框架,是一个优秀的ORM实现。他很大程度的简化DAO层的编码工作
* hibernate使用Java反射机制,而不是字节码增强程序来实现透明性。
* hibernate的性能非常好,因为它是个轻量级框架。映射的灵活性很出色。它支持各种关系数据库,从一对一到多对多的各种复杂关系。
三、Hibernate是如何延迟加载的:
Hibernate2延迟加载实现:a)实体对象 b)集合(Collection)
Hibernate3 提供了属性的延迟加载功能
四、Hibernate的查询方式:
Sql、Criteria,object comptosition
Hql:
* 属性查询
* 参数查询、命名参数查询
* 关联查询
* 分页查询
* 统计函数
五、说下Hibernate的缓存机制:
1. 内部缓存存在Hibernate中又叫一级缓存,属于应用事物级缓存
2. 二级缓存:
a) 应用及缓存
b) 分布式缓存
条件:数据不会被第三方修改、数据大小在可接受范围、数据更新频率低、同一数据被系统频繁使用、非 关键数据
c) 第三方缓存的实现
六、如何优化Hibernate:
1.使用双向一对多关联,不使用单向一对多
2.灵活使用单向一对多关联
3.不用一对一,用多对一取代
4.配置对象缓存,不使用集合缓存
5.一对多集合使用Bag,多对多集合使用Set
6. 继承类使用显式多态
7. 表字段要少,表关联不要怕多,有二级缓存撑腰