学习使用正则表达式
1,我的总结:
【.】匹配任何单个字符。例如正则表达式r.t匹配这些字符串:rat、rut、r t,但是不匹配root。
【$】匹配以此字符串结束行的结束符。
【^】匹配以此字符串结束行的结束符。
【*】匹配0或多个正好在它之前的那个字符。例如正则表达式.*意味着能够匹配任意数量的任何字符。
【\】这是引用符,用来将这里列出的这些元字符当作普通的字符来进行匹配(将一些特殊的符号正常化使用)。
[A-Za-z]可以匹配任何大小写字母
【\< \>】匹配词(word)的开始(\<)和结束(\>)。例如正则表达式\<the能够匹配字符串"for the wise"中的"the",但是不能匹配字符串"otherwise"中的"the"
[^269A-Z] 将匹配除了2、6、9和所有大写字母之外的任何字符。
{n} n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。
{n,} n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。
{n,m} m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。 请注意在逗号和两个数之间不能有空格。
* 匹配前面的子表达式零次或多次。例如,zo*能匹配“z”以及“zoo”。*等价于{0,}。
+ 匹配前面的子表达式一次或多次。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。
? 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等价于{0,1}。
2,这是一篇非常好的总结:
转载:http://www.zeuux.org/science/learning-regex.cn.html#PERE
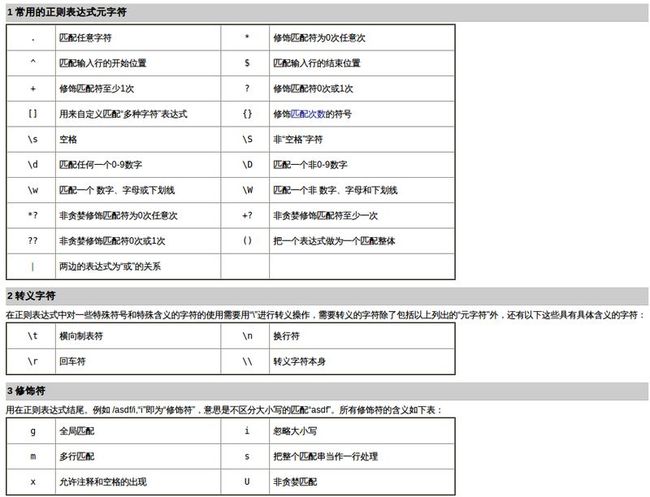
注:
(1)匹配多次
关于“匹配次数”的语法的使用有两种,一种是使用\{\};一种是{},但是无论如何含义都是一样的:
* RE{N}:是精确的匹配RE N次
* RE{N,}:会匹配RE N次或多于N次
* RE{N,M}:会匹配RE在N次和M次之间
* RE{,M}:匹配RE小于或等于M次
(2)子表达式
使用小括号“(” “)”括起来的表达式为“子表达式”或“分组”。
他有两个做用:
A,他把括号中的内容作为一个整体匹配;B,其后的修饰符(+、?、*等)对括号的整体有效;
C,并且这个其中匹配到的内容能通过“\digit”(后续引用)在正在表达式内部或着外部引用
如:/\(ab\) and \(cd\)/\2 and \1
将"ab and cd"替换为了“cd and ab”
【.】匹配任何单个字符。例如正则表达式r.t匹配这些字符串:rat、rut、r t,但是不匹配root。
【$】匹配以此字符串结束行的结束符。
【^】匹配以此字符串结束行的结束符。
【*】匹配0或多个正好在它之前的那个字符。例如正则表达式.*意味着能够匹配任意数量的任何字符。
【\】这是引用符,用来将这里列出的这些元字符当作普通的字符来进行匹配(将一些特殊的符号正常化使用)。
[A-Za-z]可以匹配任何大小写字母
【\< \>】匹配词(word)的开始(\<)和结束(\>)。例如正则表达式\<the能够匹配字符串"for the wise"中的"the",但是不能匹配字符串"otherwise"中的"the"
[^269A-Z] 将匹配除了2、6、9和所有大写字母之外的任何字符。
{n} n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。
{n,} n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。
{n,m} m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。 请注意在逗号和两个数之间不能有空格。
* 匹配前面的子表达式零次或多次。例如,zo*能匹配“z”以及“zoo”。*等价于{0,}。
+ 匹配前面的子表达式一次或多次。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。
? 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等价于{0,1}。
2,这是一篇非常好的总结:
转载:http://www.zeuux.org/science/learning-regex.cn.html#PERE
注:
(1)匹配多次
关于“匹配次数”的语法的使用有两种,一种是使用\{\};一种是{},但是无论如何含义都是一样的:
* RE{N}:是精确的匹配RE N次
* RE{N,}:会匹配RE N次或多于N次
* RE{N,M}:会匹配RE在N次和M次之间
* RE{,M}:匹配RE小于或等于M次
(2)子表达式
使用小括号“(” “)”括起来的表达式为“子表达式”或“分组”。
他有两个做用:
A,他把括号中的内容作为一个整体匹配;B,其后的修饰符(+、?、*等)对括号的整体有效;
C,并且这个其中匹配到的内容能通过“\digit”(后续引用)在正在表达式内部或着外部引用
如:/\(ab\) and \(cd\)/\2 and \1
将"ab and cd"替换为了“cd and ab”