类似渲染管线相关的讲解,这个网址链接的内容比较好:
http://fgiesen.wordpress.com/2011/07/09/a-trip-through-the-graphics-pipeline-2011-index/
可惜外网进不去,进不去看这里也是一样:
http://www.opengpu.org/forum.php?mod=viewthread&tid=6299
1.最小功能模块:
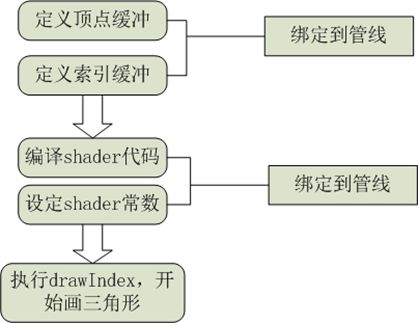
一次绘制其实就代表着一个渲染的最小功能模块,在这个过程中,CPU把准备好的数据和逻辑打包通过管线的形式传递给GPU执行。为什么会是这个模式呢?原因:1.CPU没有GPU的效率高。2.GPU的显存无法独立加载数据。正是因为同时满足这两个条件,才会出现这种恶心的局面。我们知道,最开始的时候其实所有的事情都是在CPU里面做的,后来因为效果的需要,出现了GPU并且GPU的运算效率越来越高。才导致出现GPU编程,但是GPU发展到现在还是个畸形,主要是因为它永远独立而强大的运算能力,却缺乏独立的数据加载的能力。如果它拥有独立的数据加载的能力,管线的作用最多是维持一些少量的CPU和GPU的数据交换。为什么GPU不具备独立加载数据的能力?原因:显存小,腿短才是内伤,当然也设计到不统一等数据交换的问题。最终的比较好的发展趋势,当然是统一寻址,就是现在AMD搞的那套,虽然它制作工艺不行,但是会折腾,能推动硬件发展也是不错的。
2.功能模块
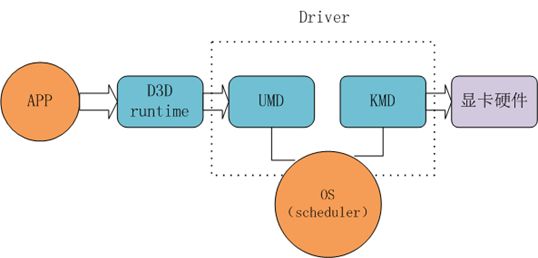
这张图主要是用来让我们理解DX这个平台所做的事情,APP是咱们的程序,显卡是硬件,D3D runtime是微软提供给APP使用的API,UMD和KMD是显卡厂商提供的驱动模块,这体现了微软订规范,厂商实现细节的思想。
D3D runtime:一方面它会提供给用户使用的接口,就是咱们用的API,另一方面它会制定自己需要调用的接口,让UMD模块实现。这其中会做一些校验之类的事情,纯粹辅助。
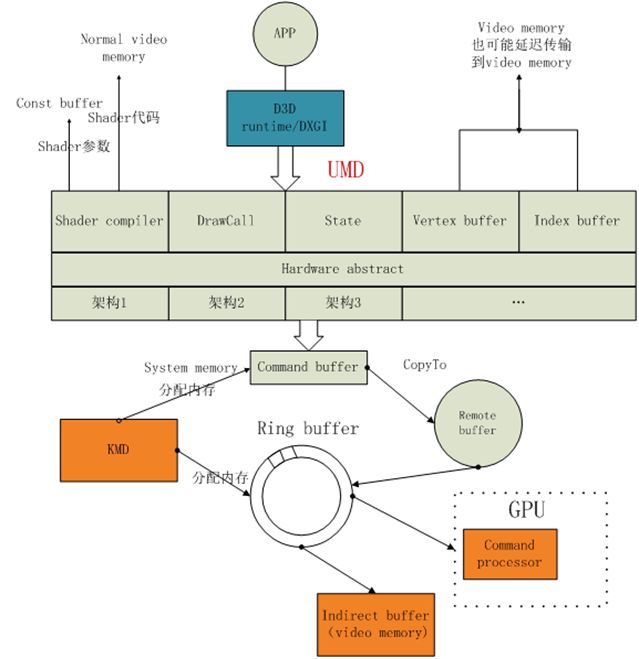
UMD(user mode driver):用户模式驱动,此模块运行在CPU端,主要功能:
1.shader编译:老实说我一直以为是runtime做的,runtime连这都不做真不知道做些什么。UMD会把shader编译成IR(中间码),然后再编译成硬件相关的代码,编译过程runtime不参入或许是有道理的,因为pengl也是要编译的,总不能又针对它来一套吧。最终结果会被存储到显存中,shader的参数会存储在显存的const buffer中,不知道纹理是不是存在这里。
2.UMD内存管理:它管理的是GPU访问的系统内存和CPU能访问的显存,看来UMD也可以称作远程内存访问控制器。
3.UMD硬件抽象层:一般硬件具备两个特点,一个是快,一个是笨,效率是高但是只会做自己会做的事情。这个时候,就需要一个模块把各类复杂的绘制信息转换成简单的指令,其实感觉跟编译的意义类似。UMD硬件抽象层把程序转换成一个个的packet,packet类型主要包括硬件寄存器设置packet,drawcall packet等等。然后把packet写入command buffer(或称作DMA buffer),这些buffer先被拷贝到remote buffer,最终会被传送到gpu端的indirect ring buffer。
4.UMD创建顶点缓冲索引缓冲:可能会直接创建在显存中,也可能创建在内存中,这不是关键。关键:在我们使用API的时候,创建buffer和创建纹理都会要求设置一个BindFlags,其实这个时候我们的描述,就决定了在UMD里面会以何种形式为其分配存储空间。
5.纹理的处理:在内存中我们的纹理是以二维数组的形式存储的,但是在GPU是以z tile格式渲染的。UMD并不做处理只是传给GPU,GPU自己会对特定格式的纹理进行swizzle操作,就是转成z tile格式。为什么要使用z tile格式格式呢?因为它效率高,它总是优先处理自己附近的像素。
6.context switch概念:UMD单元是一个dll,这说明它并不独享硬件,所以就算它出现bug也不会影响整个电脑的运行,至少不会蓝屏。这样说明GPU的时间片段跟CPU一样也是需要抢的,而在抢的过程中就涉及到状态保存的问题。这个状态保存的过程就是由context switch来实现的。
KMD(kernel mode driver):KMD负责直接和硬件打交道,可以看做是申请GPU运算资源的入口。
1.context switch:CS就是它主要功能之一,用来为多个程序分配GPU资源的,并保存他们的状态。
2.管理command buffer:UMD使用的remote buffer就是有KMD负责分配的。Indirect ring buffer也是KMD分配的,它位于video memory中,最终会被传输到GPU的command processor单元。ring buffer是一个环形队列。
这里面有好几个buffer都没有描述它的作用,好在这些东西只影响理解而不影响操作,以后有时间慢慢熟悉。
GPU的command processor:CP是GPU最前端的block,它从位于video memory中的command buffer中取出UMD产生的command packet,比如状态设置,drawIndex等,然后把它们翻译成GPU后端block的具体操作,并把这些操作送到具体的block。
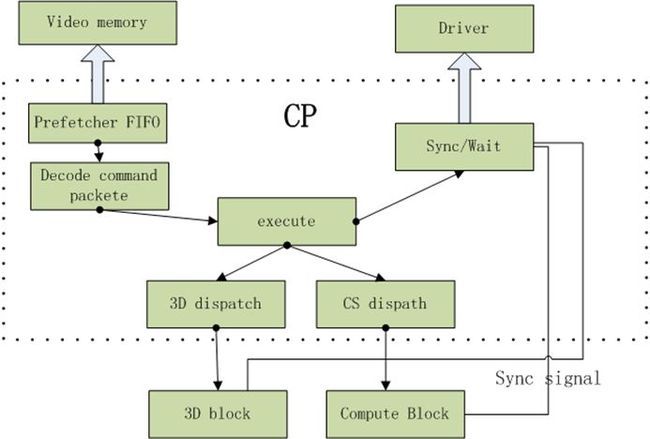
1.prefetcher模块会把command packet从内存中取出并放在FIFO中,FIFO是一个缓存,存放这些命令。command packet之前存储在ring buffer或indirect buffer里面。
2.decode模块:解析command packet并进行分配任务。
3.execute模块:也就是执行,执行的时候目前DX11除了2D和3D以外多了一个compute通用运算模块。
4.返回运算结果,证明自己已经处理完了之类。
至此,整个数据从APP到GPU执行完的过程已经结束了。
总结:
任何设计,理解作者意图是最关键的,其实之所以会出现这样一个结构,完全是由GPU还不具备完全的通用运算,而CPU由不具备图形加速能力引起的。或许,在未来的某一天这样的结构将成为历史。
整个过程分为CPU端和GPU端,CPU端的代码是UMD,它主要的作用就是把我们写的shader从编译到解析再到处理,最终形成一个个小的计算单元packet,存储到command buffer供GPU使用。
在GPU端,不知道remote buffer是干嘛的,但是可以想象的到ring buffer相当于内存里面的栈,而Indirect buffer相当于堆。KMD就一个调度的功能,没别的。
单看这个没什么不好理解的,关键是结合渲染管线的流程图,然后知道管线里面的每个阶段对应到这里是什么样子的。