operation log记录了比较重要的metadata数据修改,它是GFS的核心。它不仅记录metadata的修改记录,也充当了定义并发操作逻辑时间线的角色。Files和chunks,以及它们的versions,都是唯一的,并且是通过它们创建时的logic times来确定的。
因为operation log很重要,我们必须可靠的存储它,在metadata修改持久化之前对客户端是不可见的,否则我们可能丢失整个文件系统或者最近的client操作即使chunkserver正常。因此,我们在多个remote机器上(相对master本身)replicate 日志信息,并且只有在本地和remote机器时上相应的record持久存储之后才会把操作结果响应给客户端。master会批量flush一些日志记录,以降低因flushing和replication对整个系统的吞吐量的影响。
Master 通过回放(replay)operation log的方式恢复文件系统的状态,为了最小化启动时间,我们必须保持log文件尽量的小,当log文件增长到一定的尺寸后,master会对log设置一个检测点(checkpoint),master能够从本地磁盘加载log中最后(最近的)一个检测点之后的有限多个记录来恢复数据,检测点是一个紧凑型B-Tree的形式,可以被直接映射入内存中,通过namespace进行查找而无需解析,这就更进一步的提高了恢复速度和可用性。
因为构建一个checkpoint需要一定的时间,master内部状态在这种结构下,可以在创建chekpoit是无需拖延其他更改操作(client)。master切换到一个新的log文件中,在另一个线程中创建新的checkpoint(大概意思是,创建checkpoint和log文件切换有各自的线程,切换文件将会导致创建一个新的checkpoit)。新的checkpoint中包含了切换之前的所有变更操作。在拥有百万个文件的分布式环境中它(log file)可以在一分钟左右的时间内内创建,在创建结束后,将会被写入到本地磁盘和远程。
恢复数据时,只需要找到最后一个完成的checkpoint和其之后的log files。先前的(已经恢复或者持久到GFS中的)log files和checkpoint可以被删除,我们也会保留一些来防范灾难。检测点期间(创建或者恢复等)的失败不会影响数据的正确性,因为恢复代码能够检测和跳过不完整的检测点。
Consistency Model:
GFS具有较为宽松的一致性模型,良好的支撑较高的分布式应用,但是实现仍然相对的简单和高效。
File namespace的更改(包括修改)是原子性的,这些是有master独自去处理:namaspace锁定来确保原子性和正确定,master operation log定义了全局的这些操作的顺序。
数据变更之后file region的状态由变更的操作类型决定,file region是一致性的,所有的客户端将会得到一样的数据,无论客户端从哪个replicas读取。region中数据变更后处于defined状态,如果它是一致性的,客户端将看到变更后的数据,受影响的region是defined(由一致性实现):所有的客户端都能看到写入后的变更。并发的成功变更,会造成region处于undifiend但是一致性的状态:所有的客户端能看到相同的数据,但是它可能不是任何一个变更操作写入后的结果。通常它(region)由多个变更混合的片段构成。一个失败的变更会使region处于不一致状态(也是undifiend):不同的客户端在不同的时间或许会得到不同的数据。接下来我们介绍我们的应用是如何从undifined region中区别出defined regions。应用(客户端应用)无需进一步的再做区别。
Data变更可能是write操作或者record append(追加记录)。一个写操作将会导致数据被写入到应用指定的file offset中。一个record append操作会导致数据(the record)至少被自动append一次,即使存在并发的变更,但是需要在GFS选择的offset上。Offset返回给客户端并且给包含此record的这个defined region的头部打上标记。此外,GFS可能插入一些padding(填充)或者重复的record。它们占据的这些regions被认为是不一致性的, 通常这些数据和用户实际数据相比,是非常小的。
在一序列成功的数据变更之后,这个被变更的region确保处于defined状态并且包含每个写入操作的数据。GFS通过按照一致的顺序在所有的replicas上应用这些变更操作,使用chunk version来检测replica是否过时了(因为如果chunkserver宕机,就会导致region丢失数据的变更操作)。过时的replicas不会再接受数据变更操作,同时client询问replicas位置时master也不会将stale(过时的)replicas告知client。它们(过时的replicas)将会被垃圾回收。
因为client缓存chunk的位置信息,在这些信息刷新之前,它们或许会从一个过期的replicas中读取数据。这种局限性将会受到cache entity的过期时间和文件再次打开的限制,数据过期或者文件被再次打开,将会清空缓存中和这个文件有关的所有chuank 缓存。此外,大部分情况下文件是append-only,访问一个过期的replicas(stale replicas)往往会返回一个早期的(premature,或者是较早的)数据,而不是过期的(outdated,无效的)数据。当一个client reader重新连接master,它将立即获取当前最新的chunk locations。
变更成功后,组件故障仍然会导致数据的损坏和破坏。GFS能够通过定期的handshakes来识别故障的chunkservers。一旦出现问题,数据将会从有效的replicas中尽快恢复。只有当所有的replicas丢失(且在GFS尚未察觉和行动),那么此chunk的数据将会永久的丢失了。就是在这种极端情况下,它将不可用,而不是数据的冗余/损坏:即客户端应用将受到明确的错误而不是一些无效的数据。
Implications for Applications:(启发)
GFS应用(系统)能够容纳宽松的一致性模型,通过一些简单的技巧就能达到其他的目的:依赖append而不是overwrites,checkpointing,写入自校验,自我识别记录等。
实践中我们的应用对文件的变更都是通过append而不是overwriting。在一个典型的使用场景中,一个writer从始直终生成一个文件(生成文件的线程??),在数据全部写入结束后,它原子性的重命名文件并生成一个永久的名称,或者间歇性的对数据操作成功的多少设置checkpoint,checkpoints也许包含application-level的checksums(校验和),readers校验和处理跟进到最后一个checkpoit的那段file region,也就是大家所知的处于defined状态。忽略一致性和并发性,这种方式能够很好的为我们服务。appending是非常高效的,比起随即write,对于应用故障(GFS system)更加具有适应性。
另外一个典型的使用场景,In the other typical use, many writers concurrently append to a file for merged results or as a producer-consumer queue. readers处理这些偶然的padding和重复数据操作,按照如下方式。writer写入的每条record都包含一些额外的信息比如校验和,所以可以校验它们的有效性。reader能够通过校验和来识别和丢弃这些额外的padding和record片段。如果它不能容忍这些偶然的重复,它能够过滤这些信息,通过使用记录中的unique identifiers,经常是重命名相应的应用数据(即唯一性标示符来表示一个数据)。
系统交互:
我们设计这个系统来最小化所有的操作对master调用。在这个背景下,我们描述一下client,master,chunkserver之间是如何交互的,来实现数据变更/记录追加和快照功能。
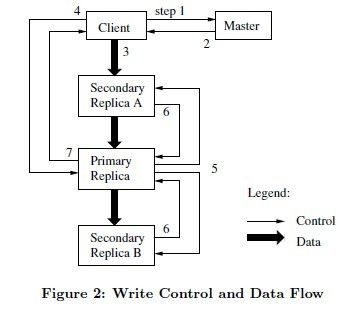
Leases和变更顺序:
一个变更,就是一个改变数据内容/chunk metadata的writer或者是一个数据追加的操作。每个变更都会在所有的replicas中运行。我们使用leases(契约,协约)来保持变更操作在各个replicas中的一致的顺序。master会给一个replicas授权leases,此replicas成为primary(主控)。primary选择一个序列顺序来应用这些变更。Global mutation顺序(全局变更顺序)首先被定义,通过master选择授权lease的顺序,在一个lease中,是通过primary来进行分配序列码的。(2个顺序,一个全局的,master选择lease,另一个是在一个lease中,是有primary分配)。
lease机制的设计使用来最小化master的开销(指责分担)。每个lease具有一个初始的过期时间,默认60秒。但是,只要chunk在被变更(有writer操作),primary可以无限期延长(当然是master告知其延长),继续接受请求。这些延期的请求和授权,都是在master和chunkserver通过heartBeat消息周期性交互是,“顺带”包含进去的。在lease过期之前,master会尝试revoke(撤销)primary的lease(当master想屏蔽在一文件上的变更操作,它将会被重命名)。即使当master失去了和priamry的通信,它(master)仍然能在旧的rlease过期之后,安全的给其他replicas授权lease。
1)client问询master,哪个chunkserver持有当前chunk的lease,以及其他replicas的位置。如果没有replicas持有leases,master会给其中一个授权lease。
2)master把primary的标示和其他replicas的位置信息响应给client。client缓存这些数据以便接下来的变更操作。当primary不可访问(离群)或者它不再持有lease时,client会再次问询master。
3)client把所有的数据push给replicas,可以按照任何顺序。每个chunkserver将会按照内部的LRU缓冲策略缓存这些数据,直到数据被使用(写入)或者过期。通过分离control flow和data flow(数据留和控制流),我们能够基于network拓扑结构,调度这个expensive data flow,以提高性能,无视哪个chunkserver是primary。(意思是data flow是利用网络拓扑的特点,无需primary做干扰,数据就可以在网络间有序传输。)
4)一旦所有的replicas都收到数据,client开始给primary发送一个write请求。这个请求能够出识别先前push给所有replicas的数据。primary会给接受的所有变更分配连续的序列号,这些变更可能来自多个客户端,所以有必要序列化。它(primary)会在本地按照序列号来应用这些变更。
5)primary会转发这个write请求给所有的二级replicas(secondary),每个二级replicas也会按照相同的序列应用这些变更。
6)二级replicas会响应给primary告知自己已经完成了变更。
7)primary响应给客户端。任何replicas发生的错误都会报告给客户端。错误的情况,可能是write在primary上执行成功,但是在任何一个二级replicas上执行失败(如果在primary上执行失败,它将不会分配序列码和转发write请求,primary是执行成功一个变更,就产生一个searial number)。此次client请求被认定为失败,已经修改的region处于在不一致性状态。Client code通过重试的方式来处理这种error,它会进行几次尝试3)~7)步骤。
如果一个write写入的数据很庞大,超越了一个chunk的界限,GFS client code将它差分成多个小的write操作。它们(拆分后的操作和数据)按照control flow进行,但是在多个客户端并发操作时,它们也许会被重写(overwritten)或者交叉。这个共用的file region或许会包含来自不同客户端的数据片段,不过所有的replicas最终都会一样,因为每个单独的操作都会以相同的顺序在所有的replicas中执行成功。这让file region处于一致性但是undifined状态。
Data Flow:
我们把数据流和控制流进行了分离,这样能够高效了利用网络。Control Flow从客户端开始,到primary,再到所有的二级replicas(到二级replicas就是一对多的转发)。data flow不同,它将线性的沿着严格的chunkserver链进行,pipeline形式。我们的目标是充分利用机器间的带宽,避免网络瓶颈和高延迟链接,最小化在它们之间push数据的延迟。
为了充分利用机器间的网络带宽,data通过线性方式沿着chunkserver链推进,而不是分布式或者其他的拓扑结果(例如tree)。
为了避免网络瓶颈和较高的链接延迟,每台机器把数据转发给网络拓扑结构中最近的那台还没有接收数据的机器。我们的网络拓扑足够简单,“距离”能够通过IP地址得到精确的估计。最后,我们最小化延迟,使用TCP链接管道传输数据。一旦一个chunkserver接收了数据,它就立即转发。pipelining对我们非常有用,因为我们使用了全双工链路交换网络。立即发送数据不会降低它的接收速率。没有网络阻塞的情况下,传输B 个bytes数据到R个replicas的理想的运行时间:B/T + RL ,T为网络吞吐量,L为两台机器见的传输延迟。我们的网络通常是100M(参数T),L远低于1毫秒。因此,1M数据理想的分发时间在80毫秒。
Atomic record appends:
GFS提供了一种原子性追加操作,成为record append。在传统的write,client指定数据应该被写入的offset。并发的对同一个region的write不是序列化的:region最终可能包含包含来自多个客户端的数据片段。在一次record append中,client仅仅指定了数据。在GFS选定的offset处 ,GFS把它(data)原子性的追加到文件中至少一次,然后把offset返回给客户端。
Record append在我们的分布式应用中被大量使用,并且应用中客户端位于不同的机器上,并发的append同一个文件。如果他们在传统的write中这么做 ,客户端将需要复杂而且开支较大的同步,例如通过分布式锁管理。在我们的workloads,这样的文件经常扮演multiple-producer/single-consumer队列,或者保存来自多个不同客户端的合并结果。
Record append是一种变更(a kind of mutation),并且遵循control flow方式,不过在primary上需要一点额外的逻辑。Client 把数据push给文件的最后一个chunk的所有的replicas,然后(注意是,最后一个chunk),向primary发送请求。primary检测此appending是否会导致chunk超出最大size(64M),如果是,它将把chunk填充到最大size,告诉二级replicas也这么做,然后相应给client此操作需要在下一个chunk中重试(record append被限制在chunk最大size的四分之一,以保持最坏情况下碎片在可接受的水平)。如果record 在这个最大size中适合,当然这是很常见的事情,primary把数据追加到自己的replicas中,然后告知二级replicas把数据追加到确切的offset,然后成功响应给client。
如果任何replicas追加失败,client会重试此操作。结果,同一个chunk的replicas或许包含不同的数据,或许包含同一个record的重复。GFS无法保证所有的replicas都是逐个字节相同。它近能保证数据会被作为原子单元,至少写入一次,数据必须被写入到同一个chunk的所有的replicas的相同offset。此外,在此之后,所有的replicas中接下来的record将会分配更高的offset或者是一个不同的chunk即使不同的replicas稍后会成为primary(意思大概是,接下追加record,在同一个chunk的replicas中必须分配一个更高的offset,或者产生一个新的chunk)。我们的一致性模型确保,成功操作(record append)的region是difined(因此是一致性的),而受到干扰的region则是不一致性的(因此也是undifined)。
GFS论文整理(一):[http://shift-alt-ctrl.iteye.com/blog/1842245]
GFS论文整理(三):[http://shift-alt-ctrl.iteye.com/blog/1842509]
GFS论文整理(四):[http://shift-alt-ctrl.iteye.com/blog/1842510]