Java序列化有两个重要的问题,第一个是冗余数据太多,也就是序列化之后的数据量太大,第二个就是序列化的速度慢,因此要搞那么多数据,所以慢,正常来说在java世界中,只要有有缺陷,就会被填上,而正常的任何一个rpc框架都少不了序列化内容的,但是由于mina基本没有做什么优化,默认用的是java序列化,没有比较的意义,因此我们看下hessian怎么做的。Hessian的下载地址: http://hessian.caucho.com/
Person p = new Person();
p.setAge(12); p.setName("wangshiji");
FileOutputStream fos = new FileOutputStream("d:\\hessianPerson.txt");
Hessian2Output out = new Hessian2Output(fos);
out.writeObject(p);out.flush();
首先是一个pojo,然后调用Hessian2Output进行序列化,用16进制打开

可以看到简单多了。复制出来
0X43 0Xe 0X68 0X65 0X73 0X73 0X69 0X61 0X6e 0X2e 0X50 0X65 0X72 0X73 0X6f 0X6e 0X92 0X3 0X61 0X67 0X65 0X4 0X6e 0X61 0X6d 0X65 0X60 0X9c 0X9 0X77 0X61 0X6e 0X67 0X73 0X68 0X69 0X6a 0X69
和ASCII对照分析上面的内容
0X43 大写的C 0Xe 14 类的全路径字符数
0X68 0X65 0X73 0X73 0X69 0X61 0X6e 0X2e 0X50 0X65 0X72 0X73 0X6f 0X6e hessian.Person
0X92 2+ 0x90 所有的int都会加上这个值 这个点做的很好,可以重点说下 此时的2代表2个属性
如果int的值 首先判断在-16和47之间,就会加上这个值0x90
然后在-2048和2047之间,则用两个字节存,第一个字节是(byte)(0xc8+value >> 8),第二个字节(byte) (value)
其次在-262144和262143之间,则用三个字节存,第一个字节(byte) (0xd4+(value >> 16)),第二个字节(byte) (value >> 8),第三个字节(byte) (value)
最后则用5个字节存储 第一个字节(byte) ('I'),第二个字节(byte) (value >> 24),第三个字节(byte) (value >> 16),第四个字节(byte) (value >> 8),第五个字节(byte) (value)
可以看到会跟进值的大小来确定字节数 ,正常来说,小数会比较多,因此就不会存放那么多字节,当然极端情况下,这种方法 有可能字节更多。
0X3 0X61 0X67 0X65 age 是3个字符
0X4 0X6e 0X61 0X6d 0X65 name是4个字符
0X60 这个是用来标示一个类的描述已经完结
0X9c 12+0x90 标示age的值
0X9 标示9个字符
0X77 0X61 0X6e 0X67 0X73 0X68 0X69 0X6a 0X69 标示wangshiji
好了,上面已经完了,下面看下 具体的代码实现
点击进入源码可以看到
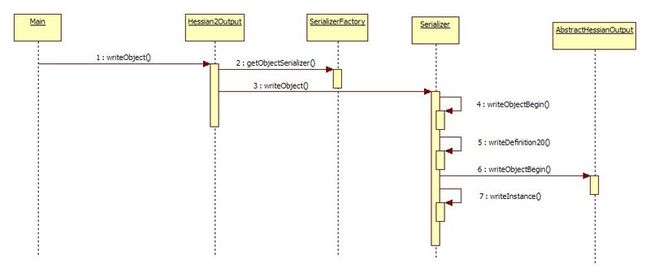
1、 Serializer serializer = findSerializerFactory().getObjectSerializer(object.getClass());
2、 serializer.writeObject(object, this);
首先是根据传进来的类类型,得到序列化器,然后用序列化器序列化类
而getObjectSerializer这个方法的内容也很简单
Serializer serializer = getSerializer(cl);
return serializer;
再进去就自己看了,需要说明的是,这里面提供了很多的序列化器,也就是说一些比较常见的类型,都有相应的序列化器,这样就会加快速度,并且减小序列化文件的大小。类型包含(HessianRemoteObject;BurlapRemoteObject;Map;Array;Throwable;InputStream;Iterator;Calendar;Enumeration;Enum;Annotation),当然如果 是自定义的类型,那么就会判断是否可以访问sun.misc.Unsafe包,如果可以的话,就创建UnsafeSerializer,不然就new一个默认序列化器JavaSerializer,这连个的却别是UnsafeSerializer可以通过包中的api快速的获得属性值,而JavaSerializer则只能通过反射获得属性值了。
需要说明的是,上面创建的序列化器,在序列化属性的时候,还会去找下相应属性类型的序列化器。
下面我们再看下反序列化
FileInputStream fis = new FileInputStream("d:\\hessianPerson.txt");
Hessian2Input hi =new Hessian2Input(fis);
Person p = (Person) hi.readObject();
和java序列化一样也是readObject方法,这里面有什么呢?
int tag = _offset < _length ? (_buffer[_offset++] & 0xff) : read(); //第一个字符,就是tag,此时C,也就是类
case 'C':
{
readObjectDefinition(null); //读取类型信息
return readObject(); //读取属性信息,并将属性信息设置到新建的对象中
}
读取类型信息也很简单
private void readObjectDefinition(Class<?> cl)
throws IOException
{
String type = readString();
int len = readInt();
SerializerFactory factory = findSerializerFactory();
Deserializer reader = factory.getObjectDeserializer(type, null);
Object []fields = reader.createFields(len);
String []fieldNames = new String[len];
for (int i = 0; i < len; i++) {
String name = readString();
fields[i] = reader.createField(name);
fieldNames[i] = name;
}
ObjectDefinition def = new ObjectDefinition(type, reader, fields, fieldNames);
}
1、 首先读取 类路径
2、 读取属性个数
3、 获得此种类型的反序列化类,此时是UnsafeDeserializer类
4、 读取属性的名称
5、 根据类路径(也就是类类型)和属性的名称,创建一个ObjectDefinition
上面基本上就是java和hessian的序列化和发序列化的过程,到这个地方的时候我们比较一下,一个重要的问题,继承的问题
1、 继承的类没有实现序列化接口
Java序列化 在序列化文件中,不存在任何父类的信息,即使已经设置了父类属性的值,也不会被序列化到,在反序列化的过程中,父类字段值就为相应属性的默认值。
Hessian序列化,在序列化文件中,存在的字段,如果设置了父类属性(和子类不重复)的值,会被序列化到文件中,作为子类的属性在用,因此在反序列化中,可以得到这些属性。
2、 继承的类实现了序列化接口
Java序列化 在序列化中,父类的字段和子类的字段是分开的,首先是子类的字段,及其值,然后是父类的类型,字段,值等,因此在反序列化的时候,可以分清父类和子类的值
而在hessian序列化中,可以看到实现和没有实现是没有区别的,还是一样的,忽略了父类的类型,仅仅是将父类的属性和值放到了序列化文件中,在反序列化的时候就分不清父类和子类的值了。这一点有可能造成一些比较麻烦的问题,参考http://jameswxx.iteye.com/blog/1071476 这个应该是我们公司的人遇到的,但是模拟了下,应该还算编码不规范导致的。
----------------------------------------------------------------------------------------hessian序列化完成--------------------------------------------------------------------------------------------
总结下 hessian序列化和java序列化的区别
1、 hessian序列化针对某些特定的类型进行优化,使得这些类型的序列化更快和更小
2、 hessian序列化不管父类有没有序列化,将其当做子类属性来处理。
3、 hessian序列化 在某些情况(编码不规范)下,会有一些小问题。
-----------------------------------------------------------------------------------------fastjson序列化--------------------------------------------------------------------------------------------------------
根据上面的思路,我们来看下fastjson,号称史上最快,序列化结果最小的工具
Person myPerson = new Person(); myPerson.setAge(10); myPerson.setName("wangshiji");
Object text = JSON.toJSONString(myPerson); System.out.println(text);
结果为{"age":10,"name":"wangshiji"}
下面分析下代码:
SerializeWriter out = new SerializeWriter();
try {
JSONSerializer serializer = new JSONSerializer(out);
for (com.alibaba.fastjson.serializer.SerializerFeature feature : features) {
serializer.config(feature, true);
}
serializer.write(object);
return out.toString();
} finally {
out.close();
}
根据温少的文章 http://www.iteye.com/topic/1113183 ,快的原因之一是自行编写类似StringBuilder的工具类SerializeWriter,仔细的看了下,没有发现提高性能的方式,不过这句话也是对的public void writeIntAndChar(int i, char c) {},这样的方法一次性把两个值写到buf中去,能够减少一次越界检查。呵呵。使用ThreadLocal来缓存buf。这个确实能提高性能,因为StringBuffer有synchronized标示符,而StringBuilder不是线程安全的,但是由于用的是软引用,有可能在GC的时候,将其回收也是一个问题。
下面我们来分析serializer.write(object); 这个代码结构
Class<?> clazz = object.getClass(); //得到当前类的类型
ObjectSerializer writer = getObjectWriter(clazz); //通过类型,得到相应的序列化器
writer.write(this, object, null, null); //通过相应的序列化器,将object进行序列化
跟进去就会发现 这里面会判断 clazz的类型,然后赋予已经定义好的序列化器,比如MapSerializer,ListSerializer。。。等,如果是自定义的pojo怎么办呢?因为不可能将所有的类型都写一遍的,这个地方就体现出fastjson高明的地方了,其实这个问题在hessian中也会遇到,hessian是不管当前类的类型,用类中属性的类型进行序列化,如果属性还是自定义pojo,则进行递归,这个方式是好的,但是fastjson更加高明,通过asm工具 直接根据当前类型,生成了一个序列化器,就是通过这个方法生成的
config.createJavaBeanSerializer(clazz)
至于asm,大家可以看下,还是比较简单的,但是这个生成的过程还是挺复杂的,可以将他那个反射类拿出来,然后在反编译就可以看到原貌了。
简单来说,就是首先得到所有属性类型,然后再调用相应的序列化器将其序列化,思想和hessian一致。如果属性还是自定义pojo,则进行递归。
反序列化的内容,就看下上面那篇文章吧,http://www.iteye.com/topic/1113183,有很多料的