Ganglia安装配置与监控Solr
Ganglia的安装,可以使用yum和rpm来进行,对于刚装的系统需要分别执行以下几个命令,来完成初始化安装:
安装完成后,即可配置。
1, 修改ganglia的conf配置,
修改 /etc/ganglia/gmetad.conf,数据源的配置
data_source "solr cluster" 127.0.0.1
集群IP,可以设置多个IP地址,也可以设置多个数据源。
2,修改 /etc/ganglia/gmond.conf的配置,把name对应起来
cluster {
name = "solr cluster"
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
}
3,修改/etc/httpd/conf.d/ganglia.conf,Apache的配置,不拦截ganglia的数据包
Alias /ganglia /usr/share/ganglia
<Location /ganglia>
Order deny,allow
Allow from all
Allow from 192.168.46.21
Allow from ::1
# Allow from .example.com
</Location>
4,cd /var/lib/jmxtrans
配置jmxtrans
添加solr.json
solr.json的配置如下:
配置完成后,需要依次,启动如下服务:
注意,solr启动的jetty的jar需要加上JMX的监控参数,内容如下:
最后需要注意一点,为了防止访问apache服务出错,
如果出现:There was an error collecting ganglia data (127.0.0.1:8652): fsockopen error: Permission denied . 错误,我们需要进行以下的设置:
一切完成后,我们就是访问我们本机的ip地址,看到的界面如下所示:
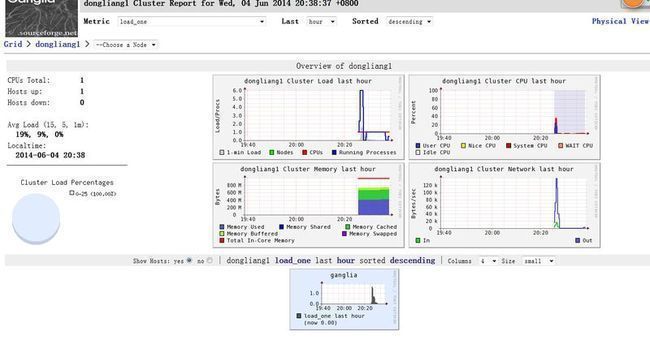
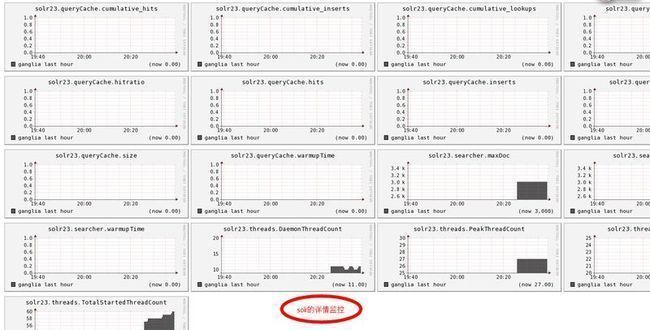
到此,我们的单机监控solr的demo,就部署成功了,以同样的方式,我们还可以对hadoop进行监控,另外我们还可以配置多个datasource来监控多个应用。
yum install –y wget apr-devel apr-util check-devel cairo-devel pango-devel libxml2-devel rpmbuild glib2-devel dbus-devel freetype-devel fontconfig-devel gcc-c++ expat-devel python-devel libXrender-devel rrdtool* rpm -ivh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm rpm -ivh http://rpms.famillecollet.com/enterprise/remi-release-6.rpm rpm -ivh http://github.com/downloads/jmxtrans/jmxtrans/jmxtrans-20121016.145842.6a28c97fbb-0.noarch.rpm yum install ganglia*
安装完成后,即可配置。
1, 修改ganglia的conf配置,
修改 /etc/ganglia/gmetad.conf,数据源的配置
data_source "solr cluster" 127.0.0.1
集群IP,可以设置多个IP地址,也可以设置多个数据源。
2,修改 /etc/ganglia/gmond.conf的配置,把name对应起来
cluster {
name = "solr cluster"
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
}
3,修改/etc/httpd/conf.d/ganglia.conf,Apache的配置,不拦截ganglia的数据包
Alias /ganglia /usr/share/ganglia
<Location /ganglia>
Order deny,allow
Allow from all
Allow from 192.168.46.21
Allow from ::1
# Allow from .example.com
</Location>
4,cd /var/lib/jmxtrans
配置jmxtrans
添加solr.json
solr.json的配置如下:
{
"servers" : [
{
"host" : "192.168.46.23",
"alias" : "solr23",
"port" : "3000",
"queries" : [
{
"obj" : "java.lang:type=Memory",
"resultAlias": "solr23.heap",
"attr" : [ "HeapMemoryUsage", "NonHeapMemoryUsage" ],
"outputWriters" : [
{
"@class" : "com.googlecode.jmxtrans.model.output.GangliaWriter",
"settings" : {
"groupName" : "Solr-JVM",
"host" : "239.2.11.71",
"port" : "8649"
}
}]
},
{
"obj" : "java.lang:name=CMS Old Gen,type=MemoryPool",
"resultAlias": "solr23.cmsoldgen",
"attr" : [ "Usage" ],
"outputWriters" : [
{
"@class" : "com.googlecode.jmxtrans.model.output.GangliaWriter",
"settings" : {
"groupName" : "Solr-JVM",
"host" : "239.2.11.71",
"port" : "8649"
}
}]
},
{
"obj" : "java.lang:type=GarbageCollector,name=*",
"resultAlias": "solr23.gc",
"attr" : [ "CollectionCount", "CollectionTime" ],
"outputWriters" : [
{
"@class" : "com.googlecode.jmxtrans.model.output.GangliaWriter",
"settings" : {
"groupName" : "Solr-JVM",
"host" : "239.2.11.71",
"port" : "8649"
}
}]
},
{
"obj" : "java.lang:type=Threading",
"resultAlias": "solr23.threads",
"attr" : [ "DaemonThreadCount", "PeakThreadCount", "ThreadCount", "TotalStartedThreadCount" ],
"outputWriters" : [
{
"@class" : "com.googlecode.jmxtrans.model.output.GangliaWriter",
"settings" : {
"groupName" : "Solr-JVM",
"host" : "239.2.11.71",
"port" : "8649"
}
}]
},
{
"obj" : "solr/collection1:type=queryResultCache,id=org.apache.solr.search.LRUCache",
"resultAlias": "solr23.queryCache",
"attr" : [ "warmupTime","size","lookups","evictions","hits","hitratio","inserts","cumulative_lookups","cumulative_hits","cumulative_hits","cumulative_hitratio","cumulative_inserts","cumulative_evictions" ],
"outputWriters" : [
{
"@class" : "com.googlecode.jmxtrans.model.output.GangliaWriter",
"settings" : {
"groupName" : "Solr-JVM",
"host" : "239.2.11.71",
"port" : "8649"
}
}]
},
{
"obj" : "solr/collection1:type=searcher,id=org.apache.solr.search.SolrIndexSearcher",
"resultAlias": "solr23.searcher",
"attr" : [ "maxDoc","numDocs","warmupTime" ],
"outputWriters" : [
{
"@class" : "com.googlecode.jmxtrans.model.output.GangliaWriter",
"settings" : {
"groupName" : "Solr-JVM",
"host" : "239.2.11.71",
"port" : "8649"
}
}]
}]
}]
}
配置完成后,需要依次,启动如下服务:
service httpd start //启动apache服务 /etc/init.d/gmetad start //启动绘图服务 /etc/init.d/gmond start //启动数据收集服务 这个放在solr前执行 jmx /etc/init.d/jmxtrans start //启动jmx /home/solr/start-solr.sh //启动solr
注意,solr启动的jetty的jar需要加上JMX的监控参数,内容如下:
java -Djava.rmi.server.hostname=192.168.46.23 -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=3000 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -jar start.jar
最后需要注意一点,为了防止访问apache服务出错,
如果出现:There was an error collecting ganglia data (127.0.0.1:8652): fsockopen error: Permission denied . 错误,我们需要进行以下的设置:
(1):临时可以使用命令setenforce 0来关闭selinux而不需要重启,刷新页面,即可访问! (2):永久的使用,需要关闭selinux:vi /etc/selinux/config,把SELINUX=enforcing改成SELINUX=disable;需要重启机器。
一切完成后,我们就是访问我们本机的ip地址,看到的界面如下所示:
到此,我们的单机监控solr的demo,就部署成功了,以同样的方式,我们还可以对hadoop进行监控,另外我们还可以配置多个datasource来监控多个应用。