sqoop的安装使用
散仙,在上篇文章中,简述了sqoop的的功能,作用,以及版本演进,那么本篇我们就来实战下,看下如下安装使用sqoop(注:散仙在这里部署的是sqoop1的环境搭建)。
首先,sqoop是基于Hadoop工作的,所以在这之前,确保你的Linux环境下,已经有可以正常工作的hadoop集群,当然伪分布式和完全分布式都可以。
其次,我们得下载一个sqoop的安全包,散仙在这里使用的是sqoop1,版本是sqoop1.4.4的版本。
最后,我们需要配置一些坏境变量,然后就可以以使用sqoop进行数据迁移了。
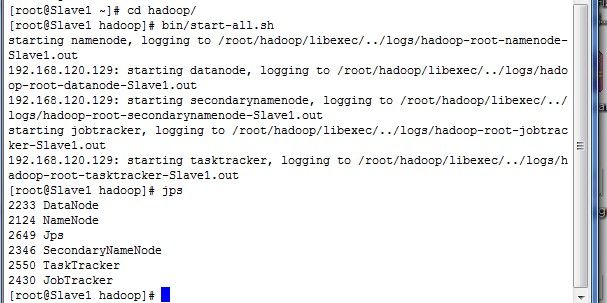
我们先启动hadoop集群,散仙的是伪分布式的截图如下:
接下来,我们需要配置sqoop的环境变量,拷贝sqoop-env-template.sh改名为sqoop-env.sh,需要注意的是在这个配置文件里面,hadoop的环境变量是必须要配置的,否则将会导致连接失败,并出现警告,其他的如Hbase,和Hive的环境变量,则不是必要的,虽然会出现警告信息,但是只要不向它们上面导入数据,就没问题。当然如果我们的应用,需要向Hbase,或Hive里导入数据,那么则需要配置此环境变量,另外一个关于zookeeper的zoo.cfg的配置目录,这个可以不用配置,使用sqoop内置的zookeeper即可,当然如果我们使用的是外置的zookeeper,则可能需要配置一下,散仙的配置文件如下:
此外,还有一点必须要做的是,拷贝的一份hadoop的核心包到sqoop的lib里面,和以及相对应的数据库的连接包,如果你是oracle,就拷贝一份oracle的JDBC连接包到sqoop的lib,同样如果你是sql server的则一样,散仙在这里使用的是mysql,所以需要拷贝mysql的JDBC包到sqoop的lib里面,截图如下:

然后,我们就可以输入命令,测试数据库连接了:
打印的信息如下:
1,将msyql中的数据导入HDFS命令如下
2,将msyql中的数据导入Hbase命令如下
3,将msyql中的数据导入Hive命令如下
关于将Hbase的数据导入到mysql里,sqoop并不是直接支持的,一般采用如下3种方法,将Hbase数据,扁平化成HDFS文件,然后再由sqoop导入,第二种,将Hbase数据导入Hive表中,然后再导入mysql,第三种直接使用Hbase的Java API读取表数据,直接向mysql导入,不需要使用sqoop。
首先,sqoop是基于Hadoop工作的,所以在这之前,确保你的Linux环境下,已经有可以正常工作的hadoop集群,当然伪分布式和完全分布式都可以。
其次,我们得下载一个sqoop的安全包,散仙在这里使用的是sqoop1,版本是sqoop1.4.4的版本。
最后,我们需要配置一些坏境变量,然后就可以以使用sqoop进行数据迁移了。
我们先启动hadoop集群,散仙的是伪分布式的截图如下:
接下来,我们需要配置sqoop的环境变量,拷贝sqoop-env-template.sh改名为sqoop-env.sh,需要注意的是在这个配置文件里面,hadoop的环境变量是必须要配置的,否则将会导致连接失败,并出现警告,其他的如Hbase,和Hive的环境变量,则不是必要的,虽然会出现警告信息,但是只要不向它们上面导入数据,就没问题。当然如果我们的应用,需要向Hbase,或Hive里导入数据,那么则需要配置此环境变量,另外一个关于zookeeper的zoo.cfg的配置目录,这个可以不用配置,使用sqoop内置的zookeeper即可,当然如果我们使用的是外置的zookeeper,则可能需要配置一下,散仙的配置文件如下:
# Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # included in all the hadoop scripts with source command # should not be executable directly # also should not be passed any arguments, since we need original $* # Set Hadoop-specific environment variables here. #Set path to where bin/hadoop is available #hadoop的环境信息必须 export HADOOP_COMMON_HOME=/root/hadoop #Set path to where hadoop-*-core.jar is available #hadoop的mr存放目录的配置信息必须 export HADOOP_MAPRED_HOME=/root/hadoop/tmp/mapred #set the path to where bin/hbase is available #hbase的配置信息非必须 export HBASE_HOME=/root/hbase #Set the path to where bin/hive is available #hive的配置信息非必须 export HIVE_HOME=/root/hive #Set the path for where zookeper config dir is #export ZOOCFGDIR=
此外,还有一点必须要做的是,拷贝的一份hadoop的核心包到sqoop的lib里面,和以及相对应的数据库的连接包,如果你是oracle,就拷贝一份oracle的JDBC连接包到sqoop的lib,同样如果你是sql server的则一样,散仙在这里使用的是mysql,所以需要拷贝mysql的JDBC包到sqoop的lib里面,截图如下:
然后,我们就可以输入命令,测试数据库连接了:
bin/sqoop list-databases --connect jdbc:mysql://192.168. 120.129 --username root --password root
打印的信息如下:
Warning: /usr/lib/hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: $HADOOP_HOME is deprecated. 13/12/30 06:58:40 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 13/12/30 06:58:40 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. information_schema hive mysql test
1,将msyql中的数据导入HDFS命令如下
bin/sqoop import --connect jdbc:mysql://192.168.120.129/test --table student //将HDFS上的数据导入到mysql中 bin/sqoop export --connect jdbc:mysql://192.168.120.129/test --username sqoop --password sqoop --table students --export-dir hdfs://masternode:9000/user/grid/students/part-m-00000
2,将msyql中的数据导入Hbase命令如下
bin/sqoop import --connect jdbc:mysql://192.168.120.129/test --table student --hbase-table qindongliang --hbase-create-table --hbase-row-key id --column-family dong
3,将msyql中的数据导入Hive命令如下
sqoop import --connect jdbc:mysql://192.168.120.129/test --table ST_Statistics --hive-import --create-hive-table //将Hive中的数据导出到mysql中 bin/sqoop export --connect jdbc:mysql://192.168.120.129/test --username root --password admin --table uv_info --export-dir /user/hive/warehouse/uv/dt=mytable
关于将Hbase的数据导入到mysql里,sqoop并不是直接支持的,一般采用如下3种方法,将Hbase数据,扁平化成HDFS文件,然后再由sqoop导入,第二种,将Hbase数据导入Hive表中,然后再导入mysql,第三种直接使用Hbase的Java API读取表数据,直接向mysql导入,不需要使用sqoop。