| This topic illustrates the performance improvement techniques in String and StringBuffer with the following sections:
Overview of String and StringBuffer Immutable objects cannot be modified once they are created. Mutable objects can be modified after their creation. String objects are immutable where as StringBuffer objects are mutable.
You need to carefully choose between these two objects depending on the situation for better performance. The following topics illustrate in detail : Note: This section assumes that reader has some basic knowledge of Java Strings and StringBuffer. Better way of creating Strings You can create String objects in the following ways. 1.String s1 = "hello"; String s2 = "hello"; 2.String s3 = new String("hello"); String s4 = new String("hello"); Which of the above gives better performance? Here is a code snippet to measure the difference. StringTest1.java
| package com.performance.string; /** This class shows the time taken for creation of String literals and String objects. */ public class StringTest1 { public static void main(String[] args){ // create String literals long startTime = System.currentTimeMillis(); for(int i=0;i<50000;i++){ String s1 = "hello"; String s2 = "hello"; } long endTime = System.currentTimeMillis(); System.out.println("Time taken for creation of String literals : " + (endTime - startTime) + " milli seconds" ); // create String objects using 'new' keyword long startTime1 = System.currentTimeMillis(); for(int i=0;i<50000;i++){ String s3 = new String("hello"); String s4 = new String("hello"); } long endTime1 = System.currentTimeMillis(); System.out.println("Time taken for creation of String objects : " + (endTime1 - startTime1)+" milli seconds"); } } |
| |
The output of this code
| Time taken for creation of String literals : 0 milli seconds Time taken for creation of String objects : 170 milli seconds |
It clearly shows first type of creation is much more faster than second type of creation. Why? Because the content is same s1 and s2 refer to the same object where as s3 and s4 do not refer to the same object. The 'new' key word creates new objects for s3 and s4 which is expensive. How the JVM works with Strings: Java Virtual Machine maintains an internal list of references for interned Strings ( pool of unique Strings) to avoid duplicate String objects in heap memory. Whenever the JVM loads String literal from class file and executes, it checks whether that String exists in the internal list or not. If it already exists in the list, then it does not create a new String and it uses reference to the existing String Object. JVM does this type of checking internally for String literal but not for String object which it creates through 'new' keyword. You can explicitly force JVM to do this type of checking for String objects which are created through 'new' keyword using String.intern() method. This forces JVM to check the internal list and use the existing String object if it is already present. So the conclusion is, JVM maintains unique String objects for String literals internally. Programmers need not bother about String literals but they should bother about String objects that are created using 'new' keyword and they should use intern() method to avoid duplicate String objects in heap memory which in turn improves java performance. see the following section for more information. The following figure shows the creation of String Objects without using the intern() method.
You can test the above difference programmatically using == operator and String.equals() method. == operator returns true if the references point to the same object but it does not check the contents of the String object where as String.equals() method returns true if the contents of the String objects are equal. s1==s2 for the above code returns true because s1 and s2 references point to the same object. s3.equals(s4) for the above code returns true because both objects content is same which is "hello". You can see this mechanism in the above figure. Here, we have three separate objects which contain same content,"hello". Actually we don't need separate objects because they use memory and take time to execute. How do you make sure that the String objects are not duplicated? The next topic covers this interesting interning String mechanism. Optimization by Interning Stings In situations where String objects are duplicated unnecessarily, String.intern() method avoids duplicating String objects. The following figure shows how the String.intern() method works. The String.intern() method checks the object existence and if the object exists already, it changes point of reference to the original object rather than create a new object. The following figure shows the creation of String literal and String Object using intern 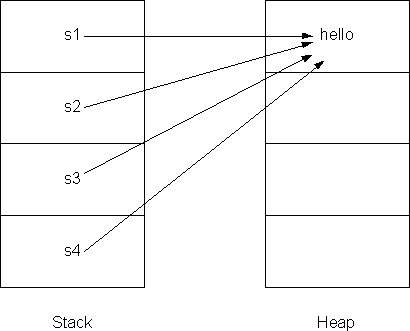
Here is the sample code to know the importance of String.intern() method.. StringTest2.java
| package com.performance.string; // This class shows the use of intern() method to improve performance public class StringTest2 { public static void main(String[] args){ // create String references like s1,s2,s3...so on.. String variables[] = new String[50000]; for( int i=0;i<variables.length;i++){ variables[i] = "s"+i; } // create String literals long startTime0 = System.currentTimeMillis(); for(int i=0;i<variables.length;i++){ variables[i] = "hello"; } long endTime0 = System.currentTimeMillis(); System.out.println("Time taken for creation of String literals : " + (endTime0 - startTime0) + " milli seconds" ); // create String objects using 'new' keyword long startTime1 = System.currentTimeMillis(); for(int i=0;i<variables.length;i++){ variables[i] = new String("hello"); } long endTime1 = System.currentTimeMillis(); System.out.println("Time taken for creation of String objects with 'new' key word : " + (endTime1 - startTime1)+" milli seconds"); // intern String objects with intern() method long startTime2 = System.currentTimeMillis(); for(int i=0;i<variables.length;i++){ variables[i] = new String("hello"); variables[i] = variables[i].intern(); } long endTime2 = System.currentTimeMillis(); System.out.println("Time taken for creation of String objects with intern(): " + (endTime2 - startTime2)+" milli seconds"); } } |
Here is the output of the above code
Time taken for creation of String literals : 0 milli seconds
Time taken for creation of String objects with 'new' key word : 160 milli seconds
Time taken for creation of String objects with intern(): 60 milli seconds |
Optimization techniques when Concatenating Strings You can concatenate multiple strings using either + operator or String.concat() or StringBuffer.append(). Which is the best one interms of performance? The choice depends on two scenarios,first scenario is compile time resolution versus run time resolution and second scenario is wether you are using StringBuffer or String. In general, programmers think that StringBuffer.append() is better than + operator or String.concat() method. But this assumption is not true under certain conditions. 1) First scenario: compile time resolution versus run time resolution Look at the following code StringTest3.java and the output.
| package com.performance.string; /** This class shows the time taken by string concatenation at compile time and run time.*/ public class StringTest3 { public static void main(String[] args){ //Test the String Concatination long startTime = System.currentTimeMillis(); for(int i=0;i<5000;i++){ String result = "This is"+ "testing the"+ "difference"+ "between"+ "String"+ "and"+ "StringBuffer"; } long endTime = System.currentTimeMillis(); System.out.println("Time taken for string concatenation using + operator : " + (endTime - startTime)+ " milli seconds"); //Test the StringBuffer Concatination long startTime1 = System.currentTimeMillis(); for(int i=0;i<5000;i++){ StringBuffer result = new StringBuffer(); result.append("This is"); result.append("testing the"); result.append("difference"); result.append("between"); result.append("String"); result.append("and"); result.append("StringBuffer"); } long endTime1 = System.currentTimeMillis(); System.out.println("Time taken for String concatenation using StringBuffer : " + (endTime1 - startTime1)+ " milli seconds"); } } |
| |
The output of this code
Time taken for String concatenation using + operator : 0 milli seconds
Time taken for String concatenation using StringBuffer : 50 milli seconds |
Interestingly the + operator is faster than StringBuffer.append() method. Let us see why? Here the compiler does a good job of optimization. Compiler simply concatenates at compile time as shown below. It does compile time resolution instead of runtime resolution, this happens when you create a String object using 'new' key word. before compilation: String result = "This is"+"testing the"+"difference"+"between"+"String"+"and"+"StringBuffer"; after compilation String result = "This is testing the difference between String and StringBuffer"; String object is resolved at compile time where as StringBuffer object is resolved at run time. Run time resolution takes place when the value of the string is not known in advance where as compile time resolution happens when the value of the string is known in advance. Here is an example. Before compilation: public String getString(String str1,String str2) { return str1+str2; } After compilation: return new StringBuffer().append(str1).append(str2).toString(); This resolves at run time and take much more time to execute. 2) Second scenario: Using StringBuffer instead of String If you look at the following code, you will find StringBuffer is faster than String for concatenation which is opposite to above scenario. StringTest4.java
| package com.performance.string; /** This class shows the time taken by string concatenation using + operator and StringBuffer */ public class StringTest4 { public static void main(String[] args){ //Test the String Concatenation using + operator long startTime = System.currentTimeMillis(); String result = "hello"; for(int i=0;i<1500;i++){ result += "hello"; } long endTime = System.currentTimeMillis(); System.out.println("Time taken for string concatenation using + operator : " + (endTime - startTime)+ " milli seconds"); //Test the String Concatenation using StringBuffer long startTime1 = System.currentTimeMillis(); StringBuffer result1 = new StringBuffer("hello"); for(int i=0;i<1500;i++){ result1.append("hello"); } long endTime1 = System.currentTimeMillis(); System.out.println("Time taken for string concatenation using StringBuffer : " + (endTime1 - startTime1)+ " milli seconds"); } } |
| |
the output of the code is
Time taken for string concatenation using + operator : 280 milli seconds
Time taken for String concatenation using StringBuffer : 0 milli seconds |
It shows StringBuffer.append() is much more faster than String. Why? The reason is both resolve at runtime but the + operator resolves in a different manner and uses String and StringBuffer to do this operation. Optimization by initializing StringBuffer You can set the initial capacity of StringBuffer using its constructor this improves performance significantly. The constructor is StringBuffer(int length), length shows the number of characters the StringBuffer can hold. You can even set the capacity using ensureCapacity(int minimumcapacity) after creation of StringBuffer object. Initially we will look at the default behavior and then the better approach later. The default behavior of StringBuffer: StringBuffer maintains a character array internally.When you create StringBuffer with default constructor StringBuffer() without setting initial length, then the StringBuffer is initialized with 16 characters. The default capacity is 16 characters. When the StringBuffer reaches its maximum capacity, it will increase its size by twice the size plus 2 ( 2*old size +2). If you use default size, initially and go on adding characters, then it increases its size by 34(2*16 +2) after it adds 16th character and it increases its size by 70(2*34+2) after it adds 34th character. Whenever it reaches its maximum capacity it has to create a new character array and recopy old and new characters. It is obviously expensive. So it is always good to initialize with proper size that gives very good performance. I tested the above StringTest4.java again with two StringBuffers, one without initial size and other with initial size. I added 50000 'hello' objects this time and did not use the + operator. I initialized the second StringBuffer with StringBuffer(250000). The output is
Time taken for String concatenation using StringBuffer with out setting size: 280 milli seconds
Time taken for String concatenation using StringBuffer with setting size: 0 milli seconds |
It shows how effective the initialization of StringBuffer is. So it is always best to initialize the StringBuffer with proper size. Key Points
- Create strings as literals instead of creating String objects using 'new' key word whenever possible
- Use String.intern() method if you want to add number of equal objects whenever you create String objects using 'new' key word.
- + operator gives best performance for String concatenation if Strings resolve at compile time
- StringBuffer with proper initial size gives best performance for String concatenation if Strings resolve at run time.
|
|