JBoss节点的负载均衡与Mysql主从备份
1. 前言
做JavaEE企业级应用就离不开集群、分布式环境这些和运行时环境相关的相关配置。企业及应用很大程度上都是处理十分安全、可靠、完整的请求,能适应任何运行时环境异常情况下也能提供软件服务。如果把所有开发好的程序全部放在一个机器上,所有的请求全都访问这一台机器就可以的系统,自然没有那么多事情要考虑了。如果系统是时时刻刻有客户需要访问、需要为客户提供7*24的服务、并且用户访问量十分巨大的时候。恐怕一台再好的服务器也难免会力不从心。如果部署软件的服务器发生了地震、火灾、人为破坏等等事情,那么这个用户的损失量恐怕就难以估计了。所以像银行、医疗、电信、政府服务这种客户群十分巨大、访问十分频繁、而且在老百姓看来你得时时刻刻提供服务的软件系统来说,稳定性、安全性、实时性就提到了第一位。这个除了科学计算集群,科学计算的集群机器是需要每个机器都为某一种复杂的计算(比如多台机器共同破译敌方的密码),最后将这些机器计算的结果返回给使用者。所以来说一般企业级的软件都是分布式的、高可用的架构,而且一般提供服务的机器是多台机器,每台机器按照某种负载算法来分担大量用户的每个用户的请求。这样带来的一个结果就是:“用户再多我也不怕,无非就是加硬件机器呗,干活的人多了,分担到每个人的工作量就少了。”如果觉得分担的机器太多,并且做的系统访问量又不是很大,3~4台足够多了。好了~~~就像很多公司那样——裁员吧!!!托管维护一台Node服务器价格很高的!如果其中一个服务器挂了,没关系。你死了没关系,有别的员工呢!大家多分担一点本该属于你的工作量(对应着客户端的请求)就OK了。这就是负载均衡的基本意思。还有一点就是在企业级系统中,数据记录比什么都重要!某种行业,数据比软件值钱得多!!比如银行,咱们银行卡里面的数字不就是银行数据库那一条条的数据嘛。这个需求就要求银行的数据库记录一定要有多个拷贝。假如地震了,银行的其中一个数据库挂了。没关系,还有其他的和你一摸一样的兄弟顶着呢!(这使我想到了一部电影——美国的《月球》,利用一个真人的多个克隆人为一个公司服务了很多年,而克隆人自己之前被灌输了工作25年就能回地球和家人团聚的意识,一个克隆人死后,另一个克隆人被唤醒,继续重复……)。咱们这里先只讨论MySql的主从备份策略,回头再单独讨论Mysql的自动切换和Oracle的RAC配置。
这里主要总结了:
1):apache http server+负载均衡配置
2):负载均衡+JBoss节点配置
3):Mysql数据主从备份
2. 运行时环境
硬件:
2台电脑:在应用服务器方面,一台是既当主分发和Node1,另一台就是一个纯粹的Node2。在数据库方面,一台是主数据库master、另一台是从数据库slave。
网络:能让2台机器互相ping的通。
软件:
操作系统:Windows(回头在linux在配置一次,配置相似)
Node的应用服务器:jboss-5.1.0.GA
Http请求服务:apache http server 2.2.17
负载均衡模块:mod_jk-1.2.31-httpd-2.2.3.so
数据库:Mysql Server 5.1.46
整体的框架流程图如下: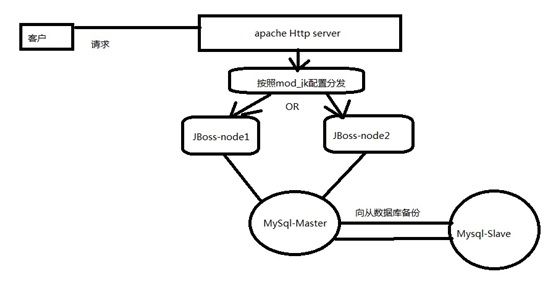
1):所有的用户HTTP请求都发送到apache server;
2):apache server通过加载的mod_jk模块的配置属性会负责将请求分发到不同的JBoss服务节点
3):Jboss节点就可以负责业务处理了
4):需要数据库的需求会请求主Mysql
5):Mysql自己可以通过自己的机制,向自己的从数据库同步数据,保证master和slave记录一致。
其实数据库这里还可以继续优化,通过Mysql代理Proxy实现数据库的读写分离,读记录直接从从数据库读取,写数据直接面向的是主数据库进行。这样主数据库只负责所有的记录更改、而从数据库只负责所有的查询操作,分担了不少主数据库的负担。但是这个不在我们这次的讨论范围。
另外要说的就是这里使用的负载均衡是借助了apache的一个模块来实现的。
1. 配置
1):安装apache http server:这个在windows上应该没什么问题,主要就是修改端口,将默认的端口80修改为8011,通过修改${apache_HOME}/conf/httpd.conf文件进行修改。以后在linux下安装配置apache server的时候再做总结。
2):安装mod_jk模块:从apache网站下载mod_jk-1.2.31-httpd-2.2.3.so文件(在Tomcat页面去下载),之后将它拷贝到${apache_HOME}/modules/下面,注意版本一定不要有任何差异。mod_jk和对应的apache版本要求比较严格,稍微不慎,集成就会出错。修改${apache_HOME}/conf/httpd.conf文件,让apache加载mod_jk模块
加入如下配置
LoadModule jk_module modules/mod_jk-1.2.31-httpd-2.2.3.so JkWorkersFile conf/workers.properties JkLogStampFormat "[%a %b %d %H:%M:%S %Y]" JkLogFile logs/mod_jk.log JkLogLevel debug JkMount /* loadbalancer
第一行代表加载模块,第二行代表有关mod_jk模块的相关配置文件在哪里,这个文件一会儿咱们会讨论,第三行是日志的格式,第四行是指定mod_jk模块相关的日志文件位置,第五行是日志的级别,debug输出的日志比较多。第六行代表所有对于/*的请求,mod_jk都会将这个请求分发到负载均衡器模块去处理、转发。
我们来看workers.properties配置
# Define list of workers that will be used # for mapping requests worker.list=loadbalancer,mystatus #defaine a worker for apache worker.node1.type=ajp13 worker.node1.host=192.168.1.100 worker.node1.port=8009 worker.node1.lbfactor=1 worker.node1.socket_timeout=30 worker.node1.socket_keepalive=1 worker.node2.type=ajp13 worker.node2.host=192.168.1.106 worker.node2.port=8009 worker.node2.lbfactor=1 worker.node2.socket_timeout=30000 worker.node2.socket_keepalive=1 worker.loadbalancer.type=lb worker.loadbalancer.balance_workers=node1,node2 worker.loadbalancer.sticky_session=1 worker.mystatus.type=status
这里需要说明的就是这个文件中很多的名称要对应上,worker.list=loadbalancer,mystatus和worker.loadbalancer.type中的loadbalancer以及worker.mystatus.type要对应上。worker.node1.type代表和第一个node节点的通讯协议是ajp13协议。worker.node1.host=192.168.1.100代表着第一个node节点的ip地址。worker.node1.lbfactor代表负载均衡分发到此node1节点的权重大小,越大,发的请求越多。worker.loadbalancer.balance_workers=node1,node2表示负载均衡上有2个node,名字一个是node1,另一个node2.这个名字首先和本文件的worker.nodeX要一致,第二就是和JBoss配置文件(稍后会提到)中的配置名一致。worker.loadbalancer.sticky_session=1代表HttpSession会共享。这个需求在本次配置中暂时没成功,先留一个问题,之后再讨论、总结。
到此算是apache配置完了负载均衡模块。
3):配置JBoss服务节点:我们采用JBoss的all目录为我们工作。JBoss配置相对简单,修改${JBOSS_HOME}\server\all\deploy\jbossweb.sar\server.xml文件。
<Server>
<Listener className="org.apache.catalina.core.AprLifecycleListener" SSLEngine="on" />
<Listener className="org.apache.catalina.core.JasperListener" />
<Service name="jboss.web">
<!-- A HTTP/1.1 Connector on port 8080 -->
<Connector protocol="HTTP/1.1" port="18181" address="0.0.0.0"
connectionTimeout="20000" redirectPort="8443" />
<!-- Add this option to the connector to avoid problems with
.NET clients that don't implement HTTP/1.1 correctly
restrictedUserAgents="^.*MS Web Services Client Protocol 1.1.4322.*$"
-->
<!-- A AJP 1.3 Connector on port 8009 -->
<Connector protocol="AJP/1.3" port="8009" address="0.0.0.0"
redirectPort="8443" />
<Engine name="jboss.web" defaultHost="localhost" jvmRoute="node1">
<Realm className="org.jboss.web.tomcat.security.JBossWebRealm"
certificatePrincipal="org.jboss.security.auth.certs.SubjectDNMapping"
allRolesMode="authOnly"
/>
<Host name="localhost">
<Valve className="org.jboss.web.tomcat.service.jca.CachedConnectionValve"
cachedConnectionManagerObjectName="jboss.jca:service=CachedConnectionManager"
transactionManagerObjectName="jboss:service=TransactionManager" />
</Host>
</Engine>
</Service>
</Server>
主要是修改了http的端口18181,将它的address换成了0.0.0.0,否则以ip+端口访问这个node是不起作用的。紧接着就是修改AJP/1.3协议相关的信息了,这个就是由apache负载均衡分发到这个node节点的桥梁。这个AJP/1.3协议的端口要和mod_jk中的配置一致。Ip也替换成可以让别的机器访问的方式。之后就是给这个Node加一个名称标识,在Engine标签加入jvmRoute="node1",用于node的标识。这个名称一定要和mod_jk中的配置的节点名称一致。另一个JBoss节点的配置类似,不再赘述。
另一台Node的配置和此Node的配置唯一一个不同的就是
| <Engine name="jboss.web" defaultHost="localhost" jvmRoute="node2"> |
标示它是不同的node。这样就算其中一台服务器挂了,只要通过apache http访问过来的请求,都不会影响用户的使用,负载均衡会将请求分发到另一个node节点上,等这一台恢复了,2台在一起分担工作。
4):配置Mysql数据库的主从实例:
其实网上有很多文章特别介绍如何配置主从备份,在这里也是将别人的经验分享出来。
首先停下主Mysql的服务,在${mysql} /下面增加一个配置文件起名字叫做my-master-slave.ini,内容和基本的配置差不多,主要是加上了一下这几行
server-id = 1 #主机标示,整数 log_bin = c:/mysql-bin.log #确保此文件可写 read-only =0 #主机,读写都可以 binlog-do-db =test #需要备份数据,多个写多行 binlog-ignore-db=mysql #不需要备份的数据库,多个写多行
上面配置中的注释已经比较明确了,就不解释了。主要就是那个server-id,在整个局域网中的数据库不要重复,否则主从备份会不正常。
在从数据库的mysql配置文件配置如下
server-id = 2 log_bin = c:/mysql-bin.log master-host =192.168.1. 100 master-user =liuyan master-pass =111111 master-port =3306 master-connect-retry=60 #如果从服务器发现主服务器断掉,重新连接的时间差(秒) replicate-do-db =test #只复制某个库 replicate-ignore-db=mysql #不复制某个库
不过要保证从数据库也要有test这个数据库哦,而且表结构、编码格式都要和主库丝毫不差,几乎在同步之前要做主库的镜像,恢复到从库。
先启动主库。在主库的mysql控制台输入如下命令
| mysql>GRANT REPLICATION SLAVE ON *.* TO ‘liuyan’@’192.168.1.106’ IDENTIFIED BY ‘111111’; |
让另一台机器106能够有权限访问主mysql服务。之后在开启从数据库。之后往主数据库插入一条记录试试,应该在从数据库也能看到刚插入的数据了。
总结
这几个配置是做集群、分布式最简单的配置了。还有很多的不足。总结不足有以下几点,以后再看相关资料改进吧!
1):负载均衡权重是在配置文件中写死的。不能根据实际的运行时机器的环境来决定负载均衡的策略,显得比较死板。
2):虽然在apache中配置了session共享,但是实际上session并没有在node上进行共享传递。如果一台机器挂了,那么这台机器的客户session也就消失了,容错性比较差。
3):apache http server和它的mod_jk模块是所有请求的总调度师,如果运行apache的机器歇菜了,那怎么办?
4):Mysql数据库的master负担了所有的请求,从服务器只是从它上面不停地同步本地的数据,这样对master机器要求太大了。如何使用有效地mysql-Proxy进行读写分离,让从mysql负担select的请求、主服务只负责数据的写入。
5):这里是有一个mysql-master,如果这个主数据库挂了怎么办?是否采用从数据暂时冒充一下主数据库,等主数据库恢复好后再切换成以前的主数据库,或者可以采用多个master策略?
6):这里使用的Mysql数据库,其他数据库——Oracle、MSSQL是否也有自己的数据库集群方案,如果每个数据库的集群方案都有各自的一套东西,那现在有没有开源的东西将这些差异性进行屏蔽或者统一呢?这样对于软件实施人员的要求就降低了很多。
7):这是一个单数据库的应用,如果在集群环境下一个系统需要不同类型的数据库一起为它服务,如何实现分布式环境下的异构数据源集成和数据备份?