讨论记录之哈希表与二叉树
Participants: ZY, LF, HZP, CPP
Date: <st1:chsdate isrocdate="False" month="9" w:st="on" day="23" islunardate="False" year="2008">08-9-23</st1:chsdate> 7:20 PM<o:p></o:p>
Recorder: LF, CPP<o:p></o:p>
<o:p> </o:p>
参考文献:
1、《算法导论》
2、《数据结构》严蔚敏 吴伟民 编著,清华大学出版社——经典的数据结构教材
<o:p> </o:p>
本次讨论的重点是 二叉排序树的插入删除(由此引入查找一般二叉树中结点的中序直接前驱和后继) 与一般二叉树的非递归遍历,对Hash查找(有冲突时)的平均长度也进行了深入的分析。
1 哈希表(散列)
在基于“比较”的一系列查找方法中,记录的关键字和记录的相对位置之间没有确定的关系,查找效率依赖于比较次数。而哈希表查找是利用记录的关键字与它的存储位置之间的关系f(即Hash函数) ,不需比较便可直接取得所查记录,显然,哈希表存取比较方便,但是存储时容易产生冲突(collision): 即不同的关键字可以对应统一个地址。因此,如何确定hash函数和解决冲突是哈希表查找的关键。
1.1 Hash函数的构造方法
直接定址法: H(k)=key 或H(k)=a*key+b(线形函数) 例如
人口数字统计表(年龄作为关键字,哈希函数取关键字自身)
地址 1 2 3 ………… 100
年龄 1 2 3 ………… 100
人数 67 35 33 ………… 244
数字分析法:取关键字的若干数位组成哈希地址
如:关键字如下:若哈希表长为100则可取中间两位十进制数作为哈希地址。
81346532 81372242 81387422 …… 81354157 (划横线部分为地址)
平方取中法:关键字平方后取中间几位数组成哈希地址
除留余数法:取关键字被某个不大于表长m的数p除后所得的余数为哈希地址。
H(k) = k mod p p<=m
折叠法,随机数法等
1.2 处理冲突的方法
假设地址集为0..n-1,由关键字得到的哈希地址为j(0<=j<=n-1)的位置已存有记录,处理冲突就是为该关键字的记录找到另一个"空"的哈希地址。在处理中可能得到一个地址序列Hi i=1,2,...k 0<=Hi<=n-1),即在处理冲突时若得到的另一个哈希地址H1仍发生冲突,再求下一地址H2,若仍冲突,再求H3...。怎样得到Hi呢?<o:p></o:p>
开放定址法:Hi=(H(k)+di) mod m (H(k)为哈希函数;m为哈希表长;di为增量序列)<o:p></o:p>
当di=1,2,3,... m-1 时叫线性探测再散列。<o:p></o:p>
当di=12,-12,22,-22,32,-32,...,k2,-k2时叫二次探测再散列。<o:p></o:p>
当di=random(m)时叫伪随机探测序列。<o:p></o:p>
例如:长度为11的哈希表关键字分别为17,60,29,哈希函数为H(k)=k mod 11,第四个记录的关键字为38,分别按上述方法添入哈希表的地址为8,4,3(随机数=9)。<o:p></o:p>
再哈希法:Hi=RHi(key) i=1,2,...,k,其中RHi均为不同的哈希函数。<o:p></o:p>
链地址法:这种方法很象基数排序,相同的地址的关键字值均链入对应的链表中。<o:p></o:p>
建立公益区法:另设一个溢出表,不管得到的哈希地址如何,一旦发生冲突,都填入溢出表。<o:p></o:p>
1.3查找分析
一般情况下,处理冲突方法相同的哈希表,其平均查找长度依赖于哈希表的装填因子a<!---->
a=表中填入记录数 / 哈希表的长度,
a标志哈希表的装满程度。直观地看,a越小,发生冲突的可能性就越小;反之,a越大,表中已填入的记录越多,再填记录是,发生冲突的可能性就越大,则查找时,给定值需与之进行比较的关键字的个数也就越多。
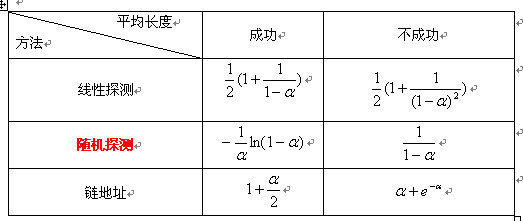
以随机探测的一组公式进行分析推导:
长度为m的哈希表中装有n个记录时查找不成功的平均查找长度(相当于要在这张表中填入第n+1个记录时所需要的比较次数的期望值)
假定:哈希函数均匀(即产生表中各个地址的概率相等),处理冲突后产生的地址也是随机的。
pi:表示前i个哈希地址均发生冲突的概率
qi:表示需进行i次比较才能找到一个“空位”的哈希地址(即前i-1次发生冲突,第i次不冲突),那么:
<o:p>  </o:p>
</o:p>
2 二叉树
我们将讨论的二叉树分成三类:判定树,二叉排序树(搜索树),一般二叉树。
判定树:在折半查找时,我们依次比较的关键字的位置构成一个判定树,其节点的值就是记录在表中的位置。中序遍历判定树,就得到一个递增的有序序列。
二叉排序树:或者是一棵空树,或者是具有一下性质的二叉树:(1)若左子树不空,则左子树上所有节点的值均小于它的跟节点的值;(2)若右子树不空,则右子树上所有节点的值均大于他的跟节点的值;(3)它的左右子树分别也是二叉排序树
判定树与二叉排序树的联系是:中序都能得到有序序列,但是前者的节点值是位置,而后者的是关键字,并且,前者只是用于在折半查找是用于分析平均查找长度,并不是一个实实在在的树。
2.1二叉排序树的插入与删除
1、插入算法描述:
<o:p> </o:p>
插入一个新的节点时,需要进行关键的比较,并且维护二叉排序树的性质。
- int InsertBS ( BiTree T, Binode * x)
- {
- /*在一棵已知二叉排序树中插入一个新的节点x*/
- if (T= = NULL) T = x;; /* 一直二叉排序树为空时 */
- return 1;
- else Binode* p = T,q;
- while(p!=NULL&&p.key!=x.key) /*只有在待插的节点关键字和树中某节点关键字不相等时,才进行相应的插入操作*/
- {
- if (p.key>x.key)
- {q = p;
- p = q->right;}
- else
- {q = p;
- p = q->left;}
- }
- if(q.key= =x.key) ERROR(“The same key has existed!”);
- else
- if (q.key>x.key) {q->left = x; return 1;} /*插入节点为左节点*/
- else {q->right = x; return 1;} /*插入节点为右节点*/
- }
2、删除
删除操作分三种情况讨论:
(1) 删除节点p 为 叶子节点,则直接删除节点即可,不会破坏整棵树的结构。
(2) 删除节点p 不是叶子节点,只有左子树或者右子树,此时也可以直接修改其双亲节点的左子树或者右子树即可,作此修改也不会破坏二叉排序树的特性。
(3) 删除节点p的左右子树均不为空,此时,情况比较复杂一些,为保证二叉树的中序序列,可以有两种做法:其一是 令p的左子树为p的父亲节点的左子树,p的右子树为p的直接前驱的右子树。其二(我们讨论的)是令p的直接前驱(或者直接后继)替代p,然后从二叉树中删除它的直接前驱(或者直接后继)。
算法如下:
<o:p>
- Void Delete ( BiTree &p)
- {
- If (!p->right) /*右子树为空则重接左子树*/
- {q = p; p = p ->left; free (q);}
- Else if (!p->left) /*左子树为空则重接右子树*/
- {q = p; p = p ->right; free (q);}
- Else /* 左右子树均不为空*/
- {q = p;
- s = p->left;
- while (s->right) /* 左拐,然后向右走到尽头 */
- {
- q = s;
- s = s->right;
- }
- p.key = s.key; /* s 指向被删除节点的前驱*/
- if(q!=p) q->right = s->left; /*重接q的右子树 */
- else q->left = s->left; /*重接q的左子树 */
- }
2.2 二叉树的中序直接前驱和直接后继
本来是讨论二叉排序树的删除操作的,结果经HZP一提醒,大家就进一步分析了如何找到给定节点的中序直接前驱和直接后继,不错不错,由深而广。
算法如下:
- BiTree* findSuccssor( BiTree &p)
- {
- If (p->right!=NULL) /*如果右子树,则其右子树的根节点就是其后继*/
- {return p->right;}
- /*如右子树为空,则向上往左拐,到尽头节点为某个节点的左孩子,该节点就是后继*/
- q = p->parent;
- While(q!=NULL&&p = = q->right)
- {
- p = q;
- q = q->parent;
- }
- Return q;
- }
- BiTree* findPredecessor( BiTree &p)
- {
- If(p->left != NULL) /*如果左子树不为空,向左拐,向右走到尽头那个节点就是其前驱*/
- {
- q = p->left;
- While(q->right)
- { q = q->right; }
- Return q;
- }
- Else /*如左子树为空,则向上往右拐,到尽头节点为某个节点的右孩子,该节点就是前驱*/
- {
- q = p->parent;
- while(q!=NULL && p= = q->left)
- {
- p = q;
- q = q->parent;
- }
- Return q;
- }
- }
2.3 一般二叉树的非递归遍历
二叉树的非递归遍历有两种思路:一种是用直接实现递归遍历,即递归遍历中的那些栈都显示实现;二是用比较自然的遍历思想,也用栈实现。
1 先序遍历<o:p></o:p>
preOrder1每次都将遇到的节点压入栈,当左子树遍历完毕后才从栈中弹出最后一个访问的节点,访问其右子树。在同一层中,不可能同时有两个节点压入栈,因此栈的大小空间为O(h),h为二叉树高度。时间方面,每个节点都被压入栈一次,弹出栈一次,访问一次,复杂度为O(n) (LF原创)
<o:p>
- Void preOrder1(BiTree* root)
- {
- Stack S;
- While(root!=NULL || !S.empty())
- {
- If(root!=NULL)
- {
- Visit(root); /*访问根节点*/
- Push(root); /*将根节点入栈,目的是为了找右子树*/
- root=root->left; /*依次访问左子树*/
- }
- Else
- {
- root = S.pop(); /*回到父节点,*/
- root = root->right; /*要开始访问右子树*/
- }
- }
- }
- Void preOrder2(BiTree* root)
- {
- If(root!=NULL)
- {
- Stack S;
- Push(root);
- While(!S.empty())
- {
- BiTree * node = s.pop();
- Visit(node); /*先访问根节点,无需压栈*/
- S.push(node->right);
- S.push(node->left);
- }
- . }
- }
preOrder2每次将节点压入栈,然后弹出,压右子树,再压入左子树,在遍历过程中,遍历序列的右节点依次被存入栈,左节点逐次被访问。同一时刻,栈中元素为m-1个右节点和1个最左节点,最高为h。所以空间也为O(h);每个节点同样被压栈一次,弹栈一次,访问一次,时间复杂度O(n) (LF原创)
2 中序遍历<o:p></o:p>
- void InOrder1(TNode* root)
- {
- Stack S;
- if( root != NULL )
- {
- S.push(root);
- }
- while ( !S.empty() )
- {
- TNode* node = S.pop();
- if ( node->bPushed )
- { // 如果标识位为true,则表示其左右子树都已经入栈,那么现在就需要访问该节点了
- Visit(node);
- }
- else
- { // 左右子树尚未入栈,则依次将 右节点,根节点,左节点 入栈
- if ( node->right != NULL )
- {
- node->right->bPushed = false; // 左右子树均设置为false
- S.push(node->right);
- }
- node->bPushed = true; // 根节点标志位为true
- S.push(node);
- if ( node->left != NULL )
- {
- node->left->bPushed = false;
- S.push(node->left);
- }
- }
- }
- }
对比先序遍历,这个算法需要额外的增加O(n)的标志位空间。另外,栈空间也扩大,因为每次压栈的时候都压入根节点与左右节点,因此栈空间为O(n)。时间复杂度方面,每个节点压栈两次,作为子节点压栈一次,作为根节点压栈一次,弹栈也是两次,时间复杂度较高。
<o:p>
- Void InOrder2(BiTree* root)
- {
- Stack S;
- While(root!=NULL || !S.empty())
- {
- If(root!=NULL)
- {
- Push(root);
- root=root->left; /*左子树入栈*/
- }
- Else
- {
- root = S.pop();
- Visit(root); /*访问根节点*/
- root = root->right; /*通过下一次想循环实现右子树遍历*/
- }
- }
- }
Inorde2类似于Preorder1,只是调换了一下节点的访问顺序。先序是先访问,再入栈,而中序是先入栈,弹栈后再访问。时空复杂度同先序一致。<o:p></o:p>
3 后序遍历<o:p></o:p>
- void PostOrder(TNode* root)
- {
- Stack S;
- if( root != NULL )
- {
- S.push(root);
- }
- while ( !S.empty() )
- {
- TNode* node = S.pop();
- if ( node->bPushed )
- { // 如果标识位为true,则表示其左右子树都已经入栈,那么现在就需要访问该节点了
- Visit(node);
- }
- else
- { // 左右子树尚未入栈,则依次将 右节点,左节点,根节点 入栈
- if ( node->right != NULL )
- {
- node->right->bPushed = false; // 左右子树均设置为false
- S.push(node->right);
- }
- if ( node->left != NULL )
- {
- node->left->bPushed = false;
- S.push(node->left);
- }
- node->bPushed = true; // 根节点标志位为true
- S.push(node);
- }
- }
- }
后序遍历只采用了我们讨论的非递归的第一种思想,即直接模拟递归调用的思想来完成。与中序类似,就是顺序调换一下,时间空间复杂度也一致。
<o:p> </o:p>
以前的非递归遍历都没写过算法,多亏了LF&HZP两个,那个直接模拟的思想给我和Z两个共讲了三遍,总算明白了!真是两个大笨蛋!呵呵!(Z不要介意哈!)