weka中写Ensemble算法
前两次我们讲了数据挖掘中比较常见的两类方法。这次我来介绍一下 ensemble (集成技术),总的来说, ensemble 技术是归类在分类中的。它的主要原理是通过集成多个分类器的效果来达到提高分类效果的目的。简单我们可以通过两张图片来看看集成的效果
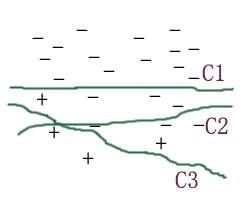
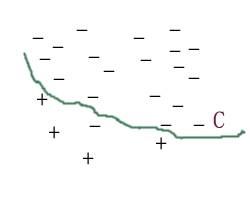
图一为多个基分类器单独工作时的分类效果图。图二为集成分类器的分类效果。我们可以看到集成分类器的分类曲线明显会平滑的多。来个比喻,在一件事情的表决上面,一个人的意见与多个人的意见相比,往往是多个人的意见来的准确一些。这是为什么我们要提倡民主决策的原因。
Ensemble 技术在数据挖掘方向主要在以下三个方向做工作:
1. 在样本上做文章,基分类器为同一个分类算法,主要的技术有 bagging , boosting ;
2. 在分类算法上做工作,即用于训练基分类器的样本相同,基分类器的算法不同,这是本文采用的方法;
3. 在样本属性集上做文章,即在不同的属性空间上构建基分类器,比较出名的是 randomforestTree 算法,这个在 weka 中也有实现。
现在我们来看看 ensemble 技术在 weka 中的实现过程。
package com.csdn;
import java.io.File;
import weka.classifiers.Classifier;
import weka.classifiers.Evaluation;
import weka.classifiers.meta.Vote;
import weka.core.Instance;
import weka.core.Instances;
import weka.core.SelectedTag;
import weka.core.converters.ArffLoader;
public class SimpleEnsemble {
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
Instances trainIns = null;
Instances testIns = null;
Classifier cfs1 = null;
Classifier cfs2 = null;
Classifier cfs3 = null;
Classifier[] cfsArray = new Classifier[3];
try{
/*
* 1. 读入训练、测试样本
* 在此我们将训练样本和测试样本是由 weka 提供的 segment 数据集构成的
*/
File file= new File("C:\\Program Files\\Weka-3-6\\data\\segment-challenge.arff");
ArffLoader loader = new ArffLoader();
loader.setFile(file);
trainIns = loader.getDataSet();
file = new File("C:\\Program Files\\Weka-3-6\\data\\segment-test.arff");
loader.setFile(file);
testIns = loader.getDataSet();
// 在使用样本之前一定要首先设置 instances 的 classIndex ,否则在使用 instances 对象是会抛出异常
trainIns.setClassIndex(trainIns.numAttributes()-1);
testIns.setClassIndex(testIns.numAttributes()-1);
/*
* 2. 初始化基分类器
* 具体使用哪一种特定的分类器可以选择,请将特定分类器的 class 名称放入 forName 函数
* 这样就构建了一个简单的分类器
*/
// 贝叶斯算法
cfs1 = (Classifier)Class.forName("weka.classifiers.bayes.NaiveBayes").newInstance();
// 决策树算法,是我们常听说的 C45 的 weka 版本,不过在我看代码的过程中发现有一些与原始算法有点区别的地方。
// 即在原始的 C45 算法中,我们规定没有一个属性节点在被使用(即被作为一个分裂节点以后,他将被从属性集合中去除掉)。
// 但是在 J48 中没有这样做,它依然在下次分裂点前,使用全部的属性集合来探测一个合适的分裂点。这样做好不好?
cfs2 = (Classifier)Class.forName("weka.classifiers.trees.J48").newInstance();
// 什么东东,不知道做什么用,平常很少用。本想要用 LibSVM 的,但是由于要加载一些包,比较麻烦。
cfs3 = (Classifier)Class.forName("weka.classifiers.rules.ZeroR").newInstance();
/*
* 3. 构建 ensemble 分类器
*/
cfsArray[0] = cfs1;
cfsArray[1] = cfs2;
cfsArray[2] = cfs3;
Vote ensemble = new Vote();
/*
* 订制 ensemble 分类器的决策方式主要有:
* AVERAGE_RULE
* PRODUCT_RULE
* MAJORITY_VOTING_RULE
* MIN_RULE
* MAX_RULE
* MEDIAN_RULE
* 它们具体的工作方式,大家可以参考 weka 的说明文档。
* 在这里我们选择的是多数投票的决策规则
*/
SelectedTag tag1 = new SelectedTag(
Vote.MAJORITY_VOTING_RULE, Vote.TAGS_RULES);
ensemble.setCombinationRule(tag1);
ensemble.setClassifiers(cfsArray);
// 设置随机数种子
ensemble.setSeed(2);
// 训练 ensemble 分类器
ensemble.buildClassifier(trainIns);
/*
* 4. 使用测试样本测试分类器的学习效果
* 在这里我们使用的训练样本和测试样本是同一个,在实际的工作中需要读入一个特定的测试样本
*/
Instance testInst;
/*
* Evaluation: Class for evaluating machine learning models
* 即它是用于检测分类模型的类
*/
Evaluation testingEvaluation = new Evaluation(testIns);
int length = testIns.numInstances();
for (int i =0; i < length; i++) {
testInst = testIns.instance(i);
// 通过这个方法来用每个测试样本测试分类器的效果
testingEvaluation.evaluateModelOnceAndRecordPrediction(
ensemble, testInst);
}
/*
* 5. 打印分类结果
* 在这里我们打印了分类器的正确率
* 其它的一些信息我们可以通过 Evaluation 对象的其它方法得到
*/
System.out.println( " 分类器的正确率: " + (1- testingEvaluation.errorRate()));
}catch(Exception e){
e.printStackTrace();
}
}
}
在 weka 中主要是通过 weka.classifiers.meta.Vote 来实现,基分类器是通过基分类器数组来设置的。同时我们可以自己设置集成分类器的决策方法,较为常用的是多数投票算法。
我在写下这篇文章是对 ensemble 分类器在 segment 数据集上的分类效果做了一个小小的测试,它对测试集 segement-test 的分类效果是 0.8309 的正确率。而我在使用单个分类器 NaiveBayes,J48, ZeroR 时它们的分类效果分别为 0.7704 、 0.9617 、 0.1106 这样我们可以看到, ensemble 分类器是可以矫正弱分类器的分类效果的。
总的来说,我在做实验的过程中,大部分的实验结果都表明 ensemble 技术确实是可以提高分类效果。当然这也是有国际上大牛的证明的,可不是我一个人这样说的。
转自:http://blog.csdn.net/anqiang1984/archive/2009/04/03/4045903.aspx