RedHat linux下安装hadoop 0.20.2, 并在windows下远程连接此hadoop,开发调试
1、hadoop 在 redhat linux下的安装过程
网上有很多讲授在windows下通过Cygwin安装hadoop的,笔者认为hadoop原始设计就是在linux下安装使用的,在windows下通过Cygwin安装也无非是模拟linux环境再在这个模拟的环境上装hadoop,既然要学hadoop就真枪实弹的在linux下安装来学习,但是要搞一台真正的linux系统对一般个人来说不容易,但是我们可以用虚拟机VMware Player,就是在windows下装一个虚拟机(VMware Player 就是个很好的虚拟机),然后在虚拟机上装一个linux系统,实现和本机windows的通信,具体的怎么安装虚拟机,怎么在虚拟机上安装linux,以及怎么实现和本机windows的通信,这里就不讲了,这个网上有很多资料。
2、在本机windows下,通过eclispe连接到linux虚拟机上安装好的haoop,进行开发调试
linux上装好hadoop之后,可以等陆到linux上通过hadoop的shell命令查看hadoop的 hdfs文件系统,执行写好的mapreduce程序,但是这样会很不方便,我们通常 的做法是在windows下开发程序,调试成功之后,再发布到linux上执行,这一部分就是来分享一下如何配置windows下的eclipse,可以链接到linux下的hadoop。
接下来就先说说第一部分的内容:
hadoop安装有三种模式:单机模式,伪分布式,完全分布式。
1、单机模式: 没意义,pass掉,不讨论。
2、 伪分布式: 就是在一台机器上模拟namenode、datanode、jobtracker、tasktracker、secondaryname。每一个存在的形式是一个java进程。
3、完全分布式:就是一个hadoop集群,有n台机器组成,一般组织方式是:一台机器作为master,上面 运行 namenode和jobtracker,另外的机器作为slave,上面运行datanode和tasktracker,至于secondaryname,可以运行在master上,也可以运行在另外一台机器上。secondaryname是namenode的一个备份里面同样保存了名字空间,和文件到文件块的map关系。建议运行在另外一台机器上,这样master死掉之后,还可以通过secondaryname所在的机器找回名字空间,和文件到文件块得map关系数据,恢复namenode。
这里条件有限,就只能实现伪分布式,就是在虚拟机上装一个linux。其实也可以在虚拟机上装n个linux,来实现完全分布式,但是我怕我的小本本,吃不消。就只能装伪分布式了。
首先确保windows下已经安装了虚拟机,并在虚拟机上安装了linux,且能和windows通信了(在windows的cmd里ping linux的ip能ping通说明可以通信了,ask:怎么知道linux的ip?,answer:进入linux终端,ifconfig即可看到)笔者window上已经安装了虚拟机并在虚拟机上装了linux系统,装linux的时候会有一个root用户,接下来我们就全部用这个root用户来操作,网上好多资料说新建一个用户比如hadoop,来安装hadoop,这里为了方便,就用root(其实是偷懒,不想弄得复杂,哇咔咔,(*^__^*) 嘻嘻……)。
安装hadoop步骤
1、实现linux的ssh无密码验证配置.
2、在linux下安装jdk,并配好环境变量
3、修改linux的机器名,并配置 /etc/hosts
4、在windows下下载hadoop 0.20.0,并修改hadoop-env.sh,core-site.xml,hdfs-site.xml,
mapred-site.xml,masters,slaves文件的配置
5、把修改好的hadoop整个文件夹传到linux下
6、把hadoop的bin加入到环境变量
7、格式化hadoop,启动hadoop
8、验证是否启动,并执行wordcount
#这个顺序并不是一个写死的顺序,就得按照这个来,如果你知道原理,可以打乱顺序来操作,比如1、2、3,先那个后那个,都没问题,但是有些步骤还是得依靠一些操作完成了才能进行,新手建议按照顺序来。#
一、实现linux的ssh无密码验证配置
ask:为什么要配置ssh无密码验证
answer:Hadoop需要使用SSH协议,namenode将使用SSH协议启动namenode和datanode进程,(datanode向namenode传递心跳信息可能也是使用SSH协议,这是我认为的,还没有做深入了解)。许多教程上介绍Hadoop集群配置时只说明了namenode上SSH无密码登录所有datanode,我在配置时发现必须使datanode上也能SSH无密码登录到namenode,Hadoop集群才能正常启动(也许这不是必须的,只是我的一个失误,但是这样能够正常启动Hadoop集群)。上述蓝色字体,是我粘的某个前辈的话,大概意思是,namenode 和datanode之间发命令是靠ssh来发的,发命令肯定是在运行的时候发,发的时候肯定不希望发一次就弹出个框说:有一台机器连接我,让他连吗。所以就要求后台namenode和datanode无障碍的进行通信,这个无障碍怎么实现呢?,就是配置ssh无密码验证.上述中前辈有个顾虑,说实现了namenode到datanode无障碍链接到,那还用实现datanode和namenode的无障碍连接吗?,这个我就不考虑了,我这里是伪分布的,就一台机器,namenode和datanode都在一个机器上,能实现自己连自己就行了。 不是自己的问题就不去伤脑筋了,哇咔咔~~,读者如果弄完全分布式的时候,碰到这个问题,可以自己试试,不行,也就实现datanode到namenode的无障碍的通信,试试又累不死~~~。
ask:实现无密码验证就能无障碍连接,这其中原理是神马捏?
answer:以namenode到datanode为例子:Namenode作为客户端,要实现无密码公钥认证,连接到服务端datanode上时,需要在namenode上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到datanode上。当namenode通过ssh连接datanode时,datanode就会生成一个随机数并用namenode的公钥对随机数进行加密,并发送给namenode。namenode收到加密数之后再用私钥进行解密,并将解密数回传给datanode,datanode确认解密数无误之后就允许namenode进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。重要过程是将客户端namenode公钥复制到datanode上。这也是我粘的某个前辈的话,啥也不说了,前辈说的很清楚,就是这么回事。
知道why了,现在就开始how吧
我这里就一台机器,所以操作很简单
在linux命令行里输入:ssh-keygen-trsa,然后一路回车。
root@hadoopName-desktop:~$ ssh-keygen -t rsa
Generatingpublic/privatersa key pair.
Enter fileinwhich to save the key (/home/zhangtao/.ssh/id_rsa)://密钥保存位置,直接回车保持默认;
Created directory'/home/zhangtao/.ssh'.
Enter passphrase (emptyforno passphrase)://设置密钥的密码,空密码直接回车即可;
Enter same passphrase again://确认上一步设置的密码。
然后进入 /root/.ssh/下面,会看到两个文件id_rsa.pub,id_rsa,
然后执行 cpid_rsa.pub authorized_keys
然后 ssh localhost 验证是否成功,第一次要你输入yes,以后就不需要了。
二、安装jdk,并配置环境变量
先在linux下面建一个目录用来安装jdk,我建的目录是 /usr/program,就是以后jdk安装到这个目录下面。
先去下载一个linux下面的jdk版本,我的是jdk-6u6-linux-i586.bin, 也有-rpm.bin 结尾的,这种结尾的安装不如直接.bin的简单,这个怎么下,就不说了,网上一大堆的,下载1.6包括1.6以上的哦~~,然后用工具传到linux的/usr/program这个目录下,就是刚才我新建的那个,上传工具好多,ftp也行,ssh 客户端也行,这个不多说,继续~~。
登录到linux下,进入 /usr/program 目录下,发现多了一个文件,就是jdk-6u6-linux-i586.bin,
然后开始安装。
1、执行chmod +xjdk-6u6-linux-i586.bin,(这是因为这个文件传过来不是可执行的文件,要把他变成可执行文件)。
2、执行./jdk-6u6-linux-i586.bin,(1、2步骤都是在 /usr/program 目录下执行的,2步骤,一路回车,遇到yes/no? 全部yes,最后会done,安装成功).
3、执行ls,会发现/usr/program 这个目录下有个文件,一个是jdk-6u6-linux-i586.bin就是我们上传上来的,另一个就是dk1.6.0_06,就是jdk的安装根目录.
开始配置环境变量
1、执行cd /etc,进入/etc 目录下。
2、执行vi profile, 修改profile文件
在里面加入以下四行
#set java environment export JAVA_HOME=/usr/program/jdk1.6.0_06 export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
3、执行chmod +x profile ,把profile变成可执行文件
4、执行source profile,把profile里的内容执行生效
5、执行,java、javac、java -version查看是否安装成功.
三、修改linux机器名
先说说怎么查看linux下的机器名
在命令行里输入hostname回车,展现的即当前linux系统的机器名如下
[root@hadoopName ~]# hostname
hadoopName
[root@hadoopName ~]#
读者也看到了,命令行的前缀 [root@hadoopName ~], @符号后面的就是机器名,前面的是当前用户名
下面说说怎么修改redhat linux下的机器名,下面的方法只适合修改redhat的,别的版本改机器名不是这样的
1、执行cd /etc/sysconfig,进入/etc/sysconfig 目录下
2、执行vi network,修改network文件,
NETWORKING=yes
HOSTNAME=hadoopName
四、在windows下下载hadoop 0.20.0,并修改hadoop-env.sh,core-site.xml,hdfs-site.xml,
mapred-site.xml,masters,slaves文件的配置
下面要做最重要的操作,下载hadoop,并修改配置文件
下载hadoop 0.20.0 版本 http://apache.etoak.com//hadoop/core/
下载后的文件是hadoop-0.20.2.tar.gz,然后解压出来
解压出来后的文件结构是这样的,进入conf目录里面,
修改hadoop-env.sh文件,加入如下一行
export JAVA_HOME=/usr/program/jdk1.6.0_06
其实hadoop-env.sh里面有这一行,默认是被注释的,你只需要把注释去掉,并且把JAVA_HOME 改成你的java安装目录即可。
需要说一下,在0.20.2版本之前,conf里面有一个 hadoop-site.xml文件,在0.20.0版本里面 conf下没有这个hadoop-site.xml文件,取而代之的是三个文件,core-site.xml,hdfs-site.xml,mapred.xml。下面要修改这三个文件
修改core-site.xml
默认的core-site.xml是如下这样的
<?xml version="1.0" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <!-- Put site-specific property overrides in this file. --> <configuration> </configuration>
现在要改成如下
<?xml version="1.0" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name> hadoop.tmp.dir </name> <value> /usr/local/hadoop/hadooptmp </value> <description> A base for other temporary directories. </description> </property> <property> <name> fs.default.name </name> <value> hdfs://192.168.133.128:9000 </value> <description> The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation. The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class. The uri's authority is used to determine the host, port, etc. for a filesystem. </description> </property> </configuration>
修改hdfs-site.xml
默认的hdfs-site.xml是如下这样的
<?xml version="1.0" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <!-- Put site-specific property overrides in this file. --> <configuration> </configuration>
要改成如下这样的
<?xml version="1.0" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name> dfs.replication </name> <value> 1 </value> <description> Default block replication. The actual number of replications can be specified when the file is created. The default is used if replication is not specified in create time. </description> </property> </configuration>
修改mapred-site.xml
默认的mapred-site.xml是如下这样的
<?xml version="1.0" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <!-- Put site-specific property overrides in this file. --> <configuration> </configuration>
要改成如下这样的
<?xml version="1.0" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name> mapred.job.tracker </name> <value> 192.168.133.128:9001 </value> <description> The host and port that the MapReduce job tracker runs at. If "local", then jobs are run in-process as a single map and reduce task. </description> </property> </configuration>
修改完这三个文件了,就一些注意的要点说一下
1、其实core-site.xml 对应有一个core-default.xml, hdfs-site.xml对应有一个hdfs-default.xml,
mapred-site.xml对应有一个mapred-default.xml。这三个defalult文件里面都有一些默认配置,现在我们修改这三个site文件,目的就覆盖default里面的一些配置,
2、hadoop分布式文件系统的两个重要的目录结构,一个是namenode上名字空间的存放地方,一个是datanode数据块的存放地方,还有一些其他的文件存放地方,这些存放地方都是基于hadoop.tmp.dir目录的,比如namenode的名字空间存放地方就是 ${hadoop.tmp.dir}/dfs/name, datanode数据块的存放地方就是 ${hadoop.tmp.dir}/dfs/data,所以设置好hadoop.tmp.dir目录后,其他的重要目录都是在这个目录下面,这是一个根目录。我设置的是 /usr/local/hadoop/hadooptmp,当然这个目录必须是存在的。
3、fs.default.name,这个是设置namenode位于哪个机器上,端口号是什么hdfs://192.168.133.128:9000,格式一定要这样写,网上很多资料说ip地址写localhost也行,笔者建议最好写ip,因为后期讲到windows下 eclipse连接hadoop 的时候,如果写localhost,就会连接不到。
4、mapred.job.tracker,这个是设置jobtracker位于哪个机器上,端口号是什么,192.168.133.128:9001,格式和上一个不一样,这个也必须这样写,同样localhost和ip的分别和上述一样
5、dfs.replication,这个是设置数据块的复制次数,默认是3,因为笔者这里就一台机器,所以只能存在一份,就改成了1
然后修改 masters和slaves文件
master文件里就把集群中的namenode所在的机器ip,这里就写 192.168.133.128, 不要写localhost,写了localhost,windows 下eclipse 连接不到hadoop
slaves文件里就把集群中所有的nodedata所在的机器ip,这里就写192.168.133.128,因为这里是单机,同样最好别写localhost
五、把修改好的hadoop整个文件夹传到linux下
上述文件修改好之后,把haoop整个目录copy草linux下,记得建个目录放这个,我建的目录是 /usr/local/hadoop,把hadoop的整个目录copy到这个下面,然后就是这样的形式
[root@hadoopName hadoop]# cd /usr/local/hadoop
[root@hadoopName hadoop]# ls
hadoop-0.20.2 hadooptmp
六、把hadoop的bin加入到环境变量
把hadoop的执行命令加到环境变量里,这样就能直接在命令行里执行hadoop的命令了
操作跟把java的bin加入环境变量一样
1、执行cd /etc,进入/etc 目录下。
2、执行vi profile, 修改profile文件
在里面加入以下四行
#set java environment export JAVA_HOME=/usr/program/jdk1.6.0_06 export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
3、执行chmod +x profile ,把profile变成可执行文件
4、执行source profile,把profile里的内容执行生效
7、格式化hadoop,启动hadoop
格式化hadoop
在命令行里执行,hadoop namenode -format,
笔者在格式化的时候出现了一个错误Invalid byte 2 of 2-byte UTF-8 sequence,经调查,是因为在修改那3个xml 的时候,用非utf-8 编码保存了,所以出错,用editplus打开从新以uft-8的形式保存,在上传到linux上,再执行 hadoop namenode -format 就行了,执行成功之后,去/usr/local/hadoop/hadooptmp 下会自动生成dfs文件夹,进去会有name文件夹,里面还有别的其他namenode上保存名字空间的文件
启动hadoop
在命令行里执行,start-all.sh,或者执行start-dfs.sh,再执行start-mapred.sh。
在命令行里输入 jps,如果出现一下内容,则说明启动成功。
[root@hadoopName ~]# jps
4505 NameNode
4692 SecondaryNameNode
4756 JobTracker
4905 Jps
4854 TaskTracker
4592 DataNode
执行 hadoop fs -ls命令,查看当前hdfs分布式文件系统的 文件目录结构,刚执行会说no such dictionary,
你要先建一个文件夹,用命令 haoop fs -mkdir testdir ,然后再执行hadoop fs -ls,就会展示/user/root/testdir
当前用户是root,所以hdfs的根目录就是 /user/root ,
8、执行wordcount
hadoop安装成功了,来执行一下自带的例子,
执行之前要有输入 输出目录,
建立输入目录: hadoop fs -mkdir input
在这个目录里放入文件:hadoop fs -put /usr/test_in/*.txt input(把本地/usr/test_in目录里的所有txt文件copy到 hdfs分布式文件系统的 /user/root/input 目录里面,因为当前目录就是root 所以 直接写input 就代表/user/root/input)
进入 /usr/local/hadoop/hadoop 0.20.0目录下,
执行 hadoop jarhadoop-0.20.2-examples.jar wordcount input ouput
执行完毕之后,执行hadoop fs -ls output,会发现如下
[root@hadoopName hadoop-0.20.2]# hadoop fs -ls output
Found 2 items
drwxr-xr-x - root supergroup 0 2011-05-08 05:20 /user/root/output/_logs
-rw-r--r-- 1 root supergroup 1688 2011-05-08 05:21 /user/root/output/part-r-00000
一、在eclipse下安装开发hadoop程序的插件
二、插件安装后,配置一下连接参数
插件装完了,就可以建一个连接了,就相当于eclipse里配置一个 weblogic的连接
第一步 如图所示,打开Map/Reduce Locations 视图,在右上角有个大象的标志点击
第二步,在点击大象后弹出的对话框进行进行参数的添加,如下图
location name: 这个随便填写,笔者填写的是:hadoop.
map/reduce master 这个框里
host:就是jobtracker 所在的集群机器,笔者这里是单机伪分布式,jobtracker就在这个机器上,所以填上这个机器的ip
port:就是jobtracker 的port,这里写的是9001
这两个参数就是 mapred-site.xml里面mapred.job.tracker里面的ip和port
DFS master这个框里
host:就是namenode所在的集群机器,笔者这里是单机伪分布式,namenode就在这个机器上,所以填上这个机器的ip。
port:就是namenode的port,这里写9000
这两个参数就是 core-site.xml里fs.default.name里面的ip和port(use M/R master host,这个复选框如果选上,就默认和map/reduce master 这个框里的 host一样,如果不选择,就可以自己定义输入,这里jobtracker 和namenode在一个机器上,所以是一样的,就勾选上)
username:这个是连接hadoop的用户名,因为笔者是在linux中用root用户安装的hadoop,而且没建立其他的用户,所以就用root。
下面的不用填写。
然后点击 finish按钮,此时,这个视图中就有多了一条记录,
第三步,重启eclipse,然后重启完毕之后,重新编辑刚才建立的那个连接记录,如图,第二步里面我们是填写的General,tab页,现在我们编辑advance parameters tab页。
读者可能问,为什么不在第二步里直接把这个tab页 也编辑了,这是因为,新建连接的时候,这个advance paramters tab页面的一些属性显示不出来,显示不出来也就没法设置,(这个有点 不好哇~~,应该显示出来,免得又重启一次,小小鄙视一下~ 哇咔咔~),必须重启一下eclipse 再进来编辑才能看到。
这里大部门属性都已经自动填写上了,读者可以看到,这里其实就是把core-defaulte.xml,hdfs-defaulte.xml,mapred-defaulte.xml里面的一些配置属性展示在这,因为我们安装hadoop的时候,还在site系列配置文件里有改动,所以这里也要弄成一样的设置。主要关注的有以下属性
fs.defualt.name:这个在General tab页已经设置了。
mapred.job.tracker:这个在General tab页也设置了。
dfs.replication:这个这里默认是3,因为我们再hdfs-site.xml里面设置成了1,所以这里也要设置成1
hadoop.tmp.dir:这个默认是/tmp/hadoop-{user.name},因为我们在ore-defaulte.xml 里hadoop.tmp.dir设置的是/usr/local/hadoop/hadooptmp,所以这里我们也改成/usr/local/hadoop/hadooptmp,其他基于这个目录属性也会自动改
hadoop.job.ugi:刚才说看不见的那个,就是这个属性,这里要填写:root,Tardis,逗号前面的是连接的hadoop的用户,逗号后面就写死Tardis。
然后点击finish,然后就连接上了,连接上的标志如图:
DFS Locations下面会有一只大象,下面会有一个文件夹(2) 这个就是 hdfs的根目录,这里就是展示的分布式文件系统的目录结构。
三、写一个wordcount的程序,在eclipse里执行
在这个eclipse里建一个map/reduce 工程,如图
叫exam,然后在这个工程下面建个java类如下
第一个,MyMap.java
package org;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MyMap extends Mapper < Object,
Text,
Text,
IntWritable > {
private final static IntWritable one = new IntWritable(1);
private Text word;
public void map(Object key, Text value, Context context) throws IOException,
InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word = new Text();
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
第二个,MyReduce.java
packageorg;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MyReduce extends Reducer < Text,
IntWritable,
Text,
IntWritable > {
public void reduce(Text key, Iterable < IntWritable > values, Context context) throws IOException,
InterruptedException {
int sum = 0;
for (IntWritable val: values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
第三个,MyDriver.java
package org;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class MyDriver {
public static void main(String[] args) throws Exception,
InterruptedException {
Configuration conf = new Configuration();
Job job = new Job(conf, "Hello Hadoop");
job.setJarByClass(MyDriver.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(MyMap.class);
job.setCombinerClass(MyReduce.class);
job.setReducerClass(MyReduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); // JobClient.runJob(conf); job.waitForCompletion(true); } }
这三个类都是基于最新的 hadoop0.20.0的,
注意了,这一步非常关键,笔者折腾了半天才想明白,是在windows下的一些设置,进入C:/Windows/System32/drivers/etc 目录,打开 hosts文件 加入:192.168.133.128 hadoopName
ip是我linux的机器ip,hadoopName是linux的机器名,这个一定要加,不然,会出错,这里其实就是把master的ip和机器名加上了
然后设置MyDriver类的 执行参数,也就是输入,输出参数,和在linux下的一样,要指定输入的文件夹,和输出的文件夹
如图:
input 就是文件存放路径,outchen就是mapReduce 之后处理的数据 输出文件夹
然后run on hadoop 如图
控制台打印如下信息:
11/05/14 19:08:07 WARN conf.Configuration: DEPRECATED: hadoop-site.xml found in the classpath. Usage of hadoop-site.xml is deprecated. Instead use core-site.xml, mapred-site.xml and hdfs-site.xml to override properties of core-default.xml, mapred-default.xml and hdfs-default.xml respectively 11/05/14 19:08:08 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same. 11/05/14 19:08:08 INFO input.FileInputFormat: Total input paths to process : 4 11/05/14 19:08:09 INFO mapred.JobClient: Running job: job_201105140203_0002 11/05/14 19:08:10 INFO mapred.JobClient: map 0% reduce 0% 11/05/14 19:08:35 INFO mapred.JobClient: map 50% reduce 0% 11/05/14 19:08:41 INFO mapred.JobClient: map 100% reduce 0% 11/05/14 19:08:53 INFO mapred.JobClient: map 100% reduce 100% 11/05/14 19:08:55 INFO mapred.JobClient: Job complete: job_201105140203_0002 11/05/14 19:08:55 INFO mapred.JobClient: Counters: 17 11/05/14 19:08:55 INFO mapred.JobClient: Job Counters 11/05/14 19:08:55 INFO mapred.JobClient: Launched reduce tasks=1 11/05/14 19:08:55 INFO mapred.JobClient: Launched map tasks=4 11/05/14 19:08:55 INFO mapred.JobClient: Data-local map tasks=4 11/05/14 19:08:55 INFO mapred.JobClient: FileSystemCounters 11/05/14 19:08:55 INFO mapred.JobClient: FILE_BYTES_READ=2557 11/05/14 19:08:55 INFO mapred.JobClient: HDFS_BYTES_READ=3361 11/05/14 19:08:55 INFO mapred.JobClient: FILE_BYTES_WRITTEN=5260 11/05/14 19:08:55 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=1688 11/05/14 19:08:55 INFO mapred.JobClient: Map-Reduce Framework 11/05/14 19:08:55 INFO mapred.JobClient: Reduce input groups=192 11/05/14 19:08:55 INFO mapred.JobClient: Combine output records=202 11/05/14 19:08:55 INFO mapred.JobClient: Map input records=43 11/05/14 19:08:55 INFO mapred.JobClient: Reduce shuffle bytes=2575 11/05/14 19:08:55 INFO mapred.JobClient: Reduce output records=192 11/05/14 19:08:55 INFO mapred.JobClient: Spilled Records=404 11/05/14 19:08:55 INFO mapred.JobClient: Map output bytes=5070 11/05/14 19:08:55 INFO mapred.JobClient: Combine input records=488 11/05/14 19:08:55 INFO mapred.JobClient: Map output records=488 11/05/14 19:08:55 INFO mapred.JobClient: Reduce input records=202
说明执行成功,去看一下,会多一个outchen目录,里面放着执行的结果,和在普通的linux上执行的一样。
四、聊聊注意事项
1、在安装hadoop的时候 core-site.xml 和 mapred.site.xml里面的 fs.defulate.name,和 mapred.job.tracker那个一定要写ip地址,不要写localhost,虽然是单机,也不能写localhost,要写本机的ip,不然eclipse连接不到。
2、masters 和 slaves文件里也要写ip,不要写localhost
五、一些错误分析
1、出现如图所示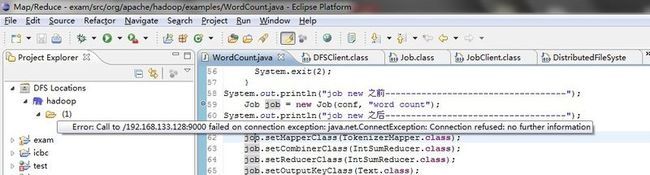
11/05/08 21:41:37 WARN conf.Configuration: DEPRECATED: hadoop-site.xml found in the classpath. Usage of hadoop-site.xml is deprecated. Instead use core-site.xml, mapred-site.xml and hdfs-site.xml to override properties of core-default.xml, mapred-default.xml and hdfs-default.xml respectively job new ֮ǰ----------------------------------- 11/05/08 21:41:40 INFO ipc.Client: Retrying connect to server: /192.168.133.128:9001. Already tried 0 time(s). 11/05/08 21:41:42 INFO ipc.Client: Retrying connect to server: /192.168.133.128:9001. Already tried 1 time(s). 11/05/08 21:41:44 INFO ipc.Client: Retrying connect to server: /192.168.133.128:9001. Already tried 2 time(s). 11/05/08 21:41:46 INFO ipc.Client: Retrying connect to server: /192.168.133.128:9001. Already tried 3 time(s). 11/05/08 21:41:48 INFO ipc.Client: Retrying connect to server: /192.168.133.128:9001. Already tried 4 time(s). 11/05/08 21:41:50 INFO ipc.Client: Retrying connect to server: /192.168.133.128:9001. Already tried 5 time(s). 11/05/08 21:41:52 INFO ipc.Client: Retrying connect to server: /192.168.133.128:9001. Already tried 6 time(s). 11/05/08 21:41:54 INFO ipc.Client: Retrying connect to server: /192.168.133.128:9001. Already tried 7 time(s). 11/05/08 21:41:56 INFO ipc.Client: Retrying connect to server: /192.168.133.128:9001. Already tried 8 time(s). 11/05/08 21:41:58 INFO ipc.Client: Retrying connect to server: /192.168.133.128:9001. Already tried 9 time(s). Exception in thread "main" java.net.ConnectException: Call to /192.168.133.128:9001 failed on connection exception: java.net.ConnectException: Connection refused: no further information at org.apache.hadoop.ipc.Client.wrapException(Client.java:767) at org.apache.hadoop.ipc.Client.call(Client.java:743) at org.apache.hadoop.ipc.RPC$Invoker.invoke(RPC.java:220) at org.apache.hadoop.mapred.$Proxy0.getProtocolVersion(Unknown Source) at org.apache.hadoop.ipc.RPC.getProxy(RPC.java:359) at org.apache.hadoop.mapred.JobClient.createRPCProxy(JobClient.java:429) at org.apache.hadoop.mapred.JobClient.init(JobClient.java:423) at org.apache.hadoop.mapred.JobClient.<init>(JobClient.java:410) at org.apache.hadoop.mapreduce.Job.<init>(Job.java:50) at org.apache.hadoop.mapreduce.Job.<init>(Job.java:54) at org.apache.hadoop.examples.WordCount.main(WordCount.java:59) Caused by: java.net.ConnectException: Connection refused: no further information at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method) at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:567) at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206) at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:404) at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:304) at org.apache.hadoop.ipc.Client$Connection.access$1700(Client.java:176) at org.apache.hadoop.ipc.Client.getConnection(Client.java:860) at org.apache.hadoop.ipc.Client.call(Client.java:720) ... 9 more
11/05/14 20:08:26 WARN conf.Configuration: DEPRECATED: hadoop-site.xml found in the classpath. Usage of hadoop-site.xml is deprecated. Instead use core-site.xml, mapred-site.xml and hdfs-site.xml to override properties of core-default.xml, mapred-default.xml and hdfs-default.xml respectively 11/05/14 20:08:46 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same. Exception in thread "main" java.net.UnknownHostException: unknown host: hadoopName at org.apache.hadoop.ipc.Client$Connection.<init>(Client.java:195) at org.apache.hadoop.ipc.Client.getConnection(Client.java:850) at org.apache.hadoop.ipc.Client.call(Client.java:720) at org.apache.hadoop.ipc.RPC$Invoker.invoke(RPC.java:220) at $Proxy1.getProtocolVersion(Unknown Source) at org.apache.hadoop.ipc.RPC.getProxy(RPC.java:359) at org.apache.hadoop.hdfs.DFSClient.createRPCNamenode(DFSClient.java:106) at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:207) at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:170) at org.apache.hadoop.hdfs.DistributedFileSystem.initialize(DistributedFileSystem.java:82) at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:1378) at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:66) at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:1390) at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:196) at org.apache.hadoop.fs.Path.getFileSystem(Path.java:175) at org.apache.hadoop.mapred.JobClient.getFs(JobClient.java:463) at org.apache.hadoop.mapred.JobClient.configureCommandLineOptions(JobClient.java:567) at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:761) at org.apache.hadoop.mapreduce.Job.submit(Job.java:432) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:447) at org.MyDriver.main(MyDriver.java:40)