BigPipe学习研究
from: http://www.searchtb.com/2011/04/an-introduction-to-bigpipe.html
1. 技术背景 FaceBook页面加载技术
试想这样一个场景,一个经常访问的网站,每次打开它的页面都要要花费6 秒;同时另外一个网站提供了相似的服务,但响应时间只需3 秒,那么你会如何选择呢?数据表明,如果用户打开一个网站,等待3~4 秒还没有任何反应,他们会变得急躁,焦虑,抱怨,甚至关闭网页并且不再访问,这是非常糟糕的情况。所以,网页加载的速度十分重要,尤其对于拥有遍布全球的5亿用户的Facebook(全球最大的社交服务网站)这样的大型网站,有着大量并发请求、海量数据等客观情况,速度就成了必须攻克的难题之一。
2010 年初的时候,Facebook 的前端性能研究小组开始了他们的优化项目,经过了六个月的努力,成功的将个人空间主页面加载耗时由原来的5 秒减少为现在的2.5 秒。这是一个非常了不起的成就,也给用户来带来了很好的体验。在优化项目中,工程师提出了一种新的页面加载技术,称之为Bigpipe。目前淘宝和Facebook 面临的问题非常相似:海量数据和页面过大,如果可以在详情页、列表页中使用bigpipe,或者在webx中集成bigpipe,将会带来明显的页面加载速度提升。
2. 相关介绍
2.1 网站前端优化的重要性
《高性能网站建设指南》一书中指出,只有10%~20%的最终用户响应时间是花费在从Web 服务器获取HTML 文档并传送到浏览器中的。如果希望能够有效地减少页面的响应时间,就必须关注剩余的80%~90%的最终用户体验。做个比较,如果对后台业务逻辑进行优化,效率提高了50%,但最终的页面响应时间只减少了5%~10%,因为它所占的比重较少。如果对前端进行性能优化,效率提升50%,则会使最终页面响应时间减少40%~45%。这是多么可观的数字!另外,前端的性能优化一般比业务逻辑的优化更加容易。所以,前端优化投入小,见效快,性价比极高,需要投入更多的关注。
2.2 BigPipe与AJAX
Web2.0的重要特征是网页显示大量动态内容,即web2.0注重网页与用户的交互。其核心技术是AJAX,如今所有主流网站都或多或少使用AJAX。与AJAX类似,BigPipe 实现了分块儿的概念,使页面能够分步输出,即每次输出一部分网页内容。接下来讨论BigPipe 与AJAX 的区别。
简单的说,BigPipe 比AJAX 有三个好处:
1. AJAX 的核心是XMLHttpRequest,客户端需要异步的向服务器端发送请求,然后将传送过来的内容动态添加到网页上。如此实现存在一些缺陷,即发送往返请求需要耗费时间,而BigPipe 技术使浏览器并不需要发送XMLHttpRequest 请求,这样就节省时间损耗。
2. 使用AJAX时,浏览器和服务器的工作顺序执行。服务器必须等待浏览器的请求,这样就会造成服务器的空闲。浏览器工作时,服务器在等待,而服务器工作时,浏览器在等待,这也是一种性能的浪费。使用BigPipe,浏览器和服务器可以并行同时工作,服务器不需要等待浏览器的请求,而是一直处于加载页面内容的工作阶段,这就会使效率得到更大的提高。
3. 减少浏览器发送到请求。对一个5亿用户的网站来说,减少了使用AJAX额外带来的请求,会减少服务器的负载,同样会带来很大的性能提升。
基于以上三点,Facebook 在进行页面优化时采用了BigPipe 技术。目前淘宝主搜索结果页中,需要加载类目,相关搜索,宝贝列表,广告等内容,前端这里使用php 的curl 的批处理来并发的访问引擎获取相应的数据,并进行分步输出。这种模式还是与bigpipe有些不同,这点后面会讲到。一般来讲,在页面比较大,而且比较复杂,样式表和脚本比较多的情况下,使用BigPipe 来优化输出页面是比较合适的。另外非常重要的一点,BigPipe 并不改变浏览器的结构与网络协议,仅使用JS就可以实现,用户不需要做任何的设置,就会看到明显的访问时间缩短。
3 目前的问题
接下来讨论现有的瓶颈。面对网页越来越大的情况,尤其是大量的css 文件和js 文件需要加载,传统的页面加载模型很难满足这样的需求,直接结果就是页面加载速度变慢,这绝不是我们希望看到的。目前的技术实现中,用户提出页面访问请求后,页面的完整加载流程如下:
1. 用户访问网页,浏览器发送一个HTTP 请求到网络服务器
2. 服务器解析这个请求,然后从存储层去数据,接着生成一个html 文件内容,并在一个HTTP Response 中把它传送给客户端
3. HTTP response 在网络中传输
4. 浏览器解析这个Response ,创建一个DOM 树,然后下载所需的CSS 和JS文件
5. 下载完CSS 文件后,浏览器解析他们并且应用在相应的内容上
6. 下载完JS 后,浏览器解析和执行他们
图1.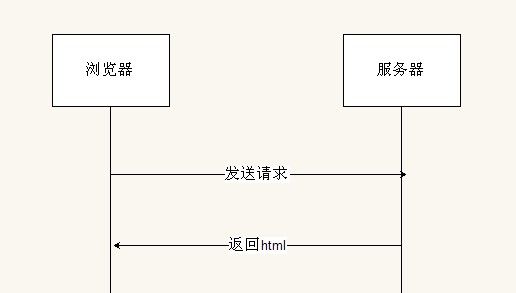
完整流程见图1.图中左侧表示服务器,右侧表示浏览器。浏览器先发送请求,然后服务器进行查找数据,生成页面,返回html 代码,最后浏览器进行渲染页面。这种模式有非常明显的缺陷:流程中的操作有着严格的顺序,如果前面的一个操作没有执行结束,后面的操作就不能执行,即操作之间是不能重叠。这样就造成性能的瓶颈:服务器生成一个页面的内容时,浏览器是空闲的,显示空白内容;而当浏览器加载渲染页面内容时,服务器又是空闲的,时间与性能的浪费由此产生。
图2.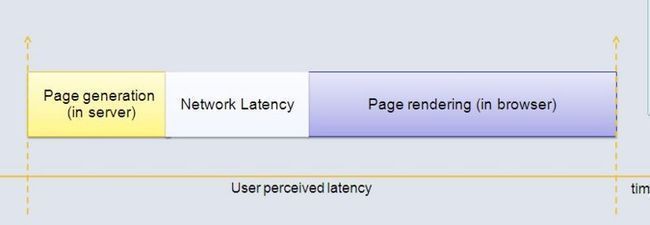
考虑图2 中现有的服务模型,横轴表示花费的时间。黄色表示在服务器的生成页面内容的时间,白色表示网络传输时间,蓝色表示在浏览器渲染页面的时间。可以看出,现有的模式造成很大的时间浪费。 考虑图3 中的情况,图中绿色表示服务器从春储层取查数据花费的时间,在海量数据下,当执行一条很费时的查询语句时(如下图右侧),服务器就就阻塞在那 里没有其他操作,而浏览器更是得不到任何反馈。这会造成非常不友好的用户体验,用户不知道什么原因使他们等待很长时间。
图3.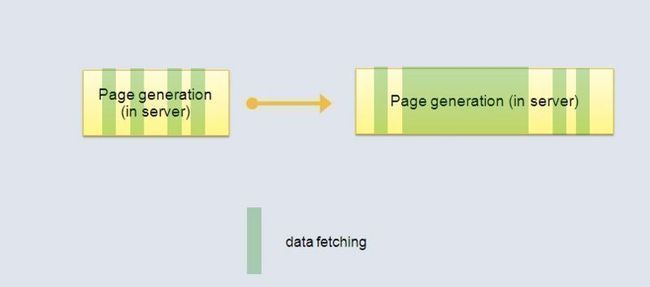
4 BigPipe思想与原理
面对上述问题,我们看下BigPipe的解决办法。BigPipe提出分块的概念,即根据页面内容位置的不同,将整个页面分成不同的块儿– 称为pagelet。该技术的设计者Changhao Jiang 是研究电子电路的博士,可能从微机上得到了启发,将众多pagelet加载的不同阶段像流水线一样在浏览器和服务器上执行,这样就做到了浏览器和服务器的并行化,从而达到重叠服务器端运行时间和浏览器端运行时间的目的。使用BigPipe 不仅可以节省时间,使加载的时间缩短,而且可以同过pagelet的分步输出,使一部分的页面内容更快的输出,从而获得更好的用户体验。BigPipe 中,用户提出页面访问请求后,页面的完整加载流程如下:
1. Request parsing:服务器解析和检查http request
2. Datafetching:服务器从存储层获取数据
3. Markup generation:服务器生成html 标记
4. Network transport : 网络传输response
5. CSS downloading:浏览器下载CSS
6. DOM tree construction and CSS styling:浏览器生成DOM 树,并且使用CSS
7. JavaScript downloading: 浏览器下载页面引用的JS 文件
8. JavaScript execution: 浏览器执行页面JS代码
这个8 个流程几乎与上文中提到现有的模式没有区别,但这整个流程只是一个pagelet 的完整流程,而多个pagelet 的不同操作阶段就可以像流水线一样进行执行了。
图4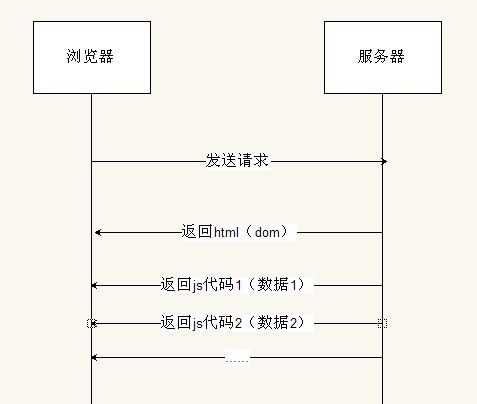
图4 中,可以看出BigPipe 对原有的模式进行的改进。浏览器发送访问请求,然后浏览器分步返回不同的pagelet的内容,具体实现将在后面介绍.考虑图5中的改进,BigPipe 打破了原有的顺序执行,将页面分成不同的pagelet ,如此一来,所有的pagelet 的执行时间累加起来还是原有的时间。但是, 通过叠加不同pagelet 的不同阶段的执行时间,使总的运行时间大大减少,这就是Bigpipe减少页面加载时间的秘密。
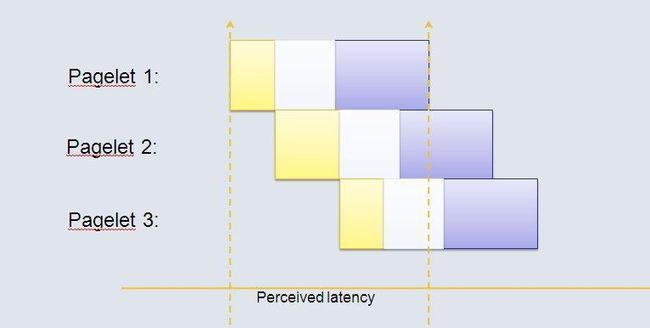
FaceBook的页面被分成了很多不同的pagelets,如图:
图5 
了解了BigPipe 的核心思想后,我们讨论它的实现原理。当浏览器访问服务器时,服务器接受请求并对其进行检查。如果请求有效,服务器端不做任何的查询,而是立刻返回一个http request 给浏览器,内容是一段html 代码,包括html<head> 标签和<body> 标签的一部分。<head>标签包括BigPipe 的js文件和css文件,这个js 文件用来解析后面接收的http response,因为后面传输的内容都为js脚本。未封闭的<body>标签中,是显示页面的逻辑结构和pagelet 的占位符的模板,例如:
<body>
<div></div>
<div></div>
<div></div>
<div>
<div>
<div id=”hotnews”></div>
<div id=”societynews”></div>
<div id=”financialnews”></div>
<div id=”ITnews”></div>
<div id=”sportsnews”></div>
</div>
<div></div>
</div>
<div></div>
上述模板使用css-div 描述了页面的结构,不同的div 标签对应不同的pagelet,id 对应了pagelet 的名称。将这个response 返回给浏览器后,服务器开始对每个pagelet 的内容进行查询,加载,生成。当一个pagelet的内容生成好,立刻调用flush()函数,将其返回给客户端,传输的数据是以json 格式的,包括这个pagelet 需要的CSS 和JS,以及html 内容和一些元数据。例如:
<script type=”text/javascript”>
big_pipe.onPageletArrive(
{id:”pagelet_composer”,
content:”<HTML>”,
css:”[..]“,
js:”[..]“,
…}
);
</script>
其中”content”表示这个pagelet 的内容,是html 源码,特殊字符如“”/需要进行转义;”id”表示content要显示的位置,即为对应的pagelet 的id标签;”css”表示需要下载的CSS 资源的路径;”js”表示需要下载的JS 脚本的路径。为了避免文件路径过长,所以在前面需要对css 和js 文件的路径进行转换,转换后为5 位字符串:不同的pagelet 可能会加载同一个css 或js 文件,所以要避免重复下载。
虽然每个pagelet 都有要加载的js 文件,但是所有的js 文件都是在最后加载,这样有利于加快页面加载速度。客户端,当通过调用“onPageletArrive(json)”函数,第一次影响传输的JS脚本中的函数解析了传入的json 数据,接着下载需要的CSS,然后把html 内容显示到响应的DIV 标签位置上。多个pagelets 的CSS文件可以同时下载,CSS 下载完成的pagelet 先显示。
在BigPipe 中,js 被给予了比CSS 和content 更低的优先级。这样, 只有当所有的pagelets 都显示了,BigPipe 才开始去下载JS 文件。所有的JS 文件都下载完成后,Pagelets的JS初始化代码开始执行,按照下载完成时间的先后顺序。在这个高度并行的系统中,几个的pagelet 所要执行的不同的阶段可以同时执行。例如,浏览器可以给两个pagelets 下载CSS 资源,同时浏览器可以渲染另外一个pagelet 的内容,同时服务器仍然在为另一个pagelet 生成html源码。从用户的角度看来,页面时逐步呈现的。初始的页面显示的更快,可以有效减短用户感觉到的延迟。
理想情况下,服务器端的实现是并行处理不同的pagelet 的内容,这样可以提升性能。服务器并发处理多个pagelet 的内容时,一个pagelet 内容生成好了,立刻将其flush 给浏览器。但是PHP 是不支持线程,所以服务器无法利用多线程的概念去并发的加载多个pagelet 的内容。对于小型网站来说,使用串行的加载pagelet 的内容就已经可以达到优化的要求了。对于大型网站,为了达到更快的速度,服务器端可以选择并发的独立不同的pagelet 的内容,具体实现有以下几种方式:
1.java 多线程。后台逻辑使用java,可以使用java 的多线程机制去同时加载不同的pagelet 的内容,加载完成后加页面内容返回给浏览器。在最后的引用部分可以看到网上用java多线程实现的例子。
2.使用PHP实现。PHP 不支持线程,无法像java 使用多线程的机制来并发处理不同pagelet 的内容。但是,Facebook 和淘宝主搜索的业务逻辑是用PHP 实现的,所以我们必须考虑如何在PHP下完成并发处理。PHP 扩展中有curl 模块,可以在该模块中curl_multi_fetch()函数进行批处理请求,把本来应该串行的请求访问并发的执行。可以这样写:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
do
{
$mrc
= curl_multi_exec(
$mh
,
$active
);
}
while
(
$mrc
==CURLM_CALL_MULTI_PERFORM);
while
(
$active
&&
$mrc
== CURLM_OK){
if
(curl_multi_select(
$mh
)!= -1){
do
{
$mrc
= curl_multi_exec(
$mh
,
$active
);
}
while
float: none ! important; height: a
|




评论