学习python之动手获取开心网超级大亨价格数据
最近一边学一边在做这个东西,起因是周围人都在玩开心网的超级大亨,里面价格数据是每10分钟更新一次,上网搜了搜,然后就开始做了。
1、网站登录
开始我也没搞清楚,在网上查的现成的例子,最近仔细看了看,把Firefox武装了一下,以前firebug不太会用,就弄了个httpfox,原来事情非常简单。很简单就是基本的网站登录用,urllib2的库,网上一搜一大把。
2、分析要完成的工作
进入超级大亨里面,随便选一个,比如春联,点击以后会出现一个价格的实时曲线,这说明这个请求可以返回所有的过去的价格,那么如何能够获取过去的价格和当前价格,把必要的内容存起来,就可以根据当前价格、过去的最高最低价格设置过滤条件,提醒买入卖出时间。
3、价格数据的获取
开始动手,打开httpfox,点start,就可以查看那些请求、返回的内容。还以春联为例,点购买的按钮,httpfox里面看到返回的content里面有个是很长的内容的,仔细看,内容如下:
<?xml version="1.0" encoding="UTF-8" ?> <result><item><hid>1705790</hid><iid>155</iid><price>14388</price><ctime>2010-02-22 21:50:01</ctime><ptime>2010-02-23 00:00:00</ptime><ctimestamp>1266854400</ctimestamp></item><item><hid>1705817</hid><iid>155</iid><price>12888</price><ctime>2010-02-22 22:00:02</ctime><ptime>2010-02-23 00:10:00</ptime><ctimestamp>1266855000</ctimestamp></item><item><hid>1705844</hid><iid>155</iid><price>9888</price><ctime>2010-02-22 22:10:02</ctime><ptime>2010-02-23 00:20:00</ptime><ctimestamp>1266855600</ctimestamp></item><item><hid>1706555</hid><iid>155</iid><price>14388</price><ctime>2010-02-22 22:20:01</ctime><ptime>2010-02-23 00:30:00</ptime><ctimestamp>1266856200</ctimestamp></item><item><hid>1706582</hid><iid>155</iid><price>11888</price><ctime>2010-02-22 22:30:02</ctime><ptime>2010-02-23 00:40:00</ptime><ctimestamp>1266856800</ctimestamp></item><item>
返回的是一个xml文件,相应的给出了请求的url:http://www.kaixin001.com/!rich/!api_item_price.php?rt=xml&iid=155。很简单,里面给出了rt=xml是指定返回格式,iid是什么,仔细看页面代码,里面有个js函数,purchase,其中iid就是物品代码。这样下面我们的事情就简单了
4、物品id的获取
查看源文件,里面很轻松就找到purchas函数,对应的还有中文的物品名称,物品id。
超级大亨里面的物品是分类的,诸如年货、商业什么的同一个页面,无非加一个循环,读取整个页面的每个分类,循环获取里面的物品id。这里就需要用到正则,我对正则用的很差,所以用了个笨办法,先取出来,再替换掉不用的东西,这样就拿到物品id和中文名称对照。
5、读取价格数据
根据分类、id、然后可以循环,分别向前面看到的价格地址请求,可以得到每个物品的价格数据,价格数据是从每天的0点开始。获取xml数据还是用urllib2,代码比登陆的还要简单。
def get_data(url):
"""取对应url下的页面数据"""
price_xml={}
for i in url.keys() :
xmlr = urllib2.Request(url[i])
price = urllib2.urlopen(xmlr)
price_xml[i]=price.read()
price.close()
#print i
return price_xml
这里url是字典,key是id,value是拼出来的地址。最后返回的price_xml同样是字典,value则是读取的整个xml数据。从xml数据中取出每个物品的价格有两种办法,一种用mindom,另一种就用正则,开始我试了试minidom,后来又改成正则,其实正则更简单,而且我们只关心价格这一个东西。
6、数据的处理和存储
如果不存储数据,那么每次拿到的仅仅是当天的数据,python数据库很方便,而且自带的有sqlite。所以所有的数据全部弄到库里面去,便于查询。刚开始走了点弯路,胃口太大,想把所有拿到的数据都存起来,结果发现下来一天上万的记录,而且每次都更新的话实在太慢,所以对数据做了简单的比较计算,最后只纪录关心的最高最低经常出现的值。
在这里写了个dealwith_data函数,比较计算了是最高最低和经常出现的值,
def dealwith_data(price):
"""正则处理页面获取有效数据"""
temp1={}
temp2={}
temp3={}
temp4={}
temp5={}
for iii in price.keys():
xmlprice=re.findall(re.compile(r"<price>(\d+)</price>"),price[iii])
#print xmlprice 中出现最多的价格
zuiduo={}
for i in xmlprice:
try:
zuiduo[i]+=1
except:
zuiduo[i]=1
for i in zuiduo.keys():
if zuiduo[i]==max(zuiduo.values()):
#print i,zuiduo[i]
temp4[iii]=i
temp5[iii]=zuiduo[i]
xmlprice=[int(i)for i in xmlprice]
temp1[iii]=min(xmlprice)
temp2[iii]=max(xmlprice)
temp3[iii]=xmlprice[-1]
#print temp3[iii]
return temp1,temp2,temp5,temp4,temp3
这里price就是上面函数的返回值。计算了最多出现的值的次数xmlprice[-1]这种表示方式指的是最后一个值,在这里就是当前价格。
zuiduo={}
for i in xmlprice:
try:
zuiduo[i]+=1
except:
zuiduo[i]=1
我到这里才真正喜欢了python的for循环。遍历价格数据,出现相同的就纪录一次。后面的循环是遍历字典找出最多次数对应的价格。至于最高最低价格,就更简单了,python的list有max、min函数,需要注意的是要转换下类型,字符串的比较是有问题的。下面的代码也是别人提供的,纪录下。
xmlprice=[int(i)for i in xmlprice]
dealwith_data最后是个return,return函数返回的是tuple,到这里我才第一次搞清楚tuple,返回值的同时其实构造了一个tuple,简单的讲就是把几个字典都丢一起。最开始我还傻傻的定义一个tuple,然后把几个dic都放进去才返回,其实直接就可以。
return temp1,temp2,temp5,temp4,temp3
数据存储用sqlite3,开始先检查数据库,没有就创建。
cx = sqlite.connect('chaojiv1.1.sqlite')
cu = cx.cursor()
#raw_input("Press ENTER to exit")
#0,1、2、3、4别为min/max/mostnum/mostprice/price/
cu.execute('''create table if not exists kaixin(
id text primary key,
name text,
min float,
max float,
mostpricenum text,
mostprice float,
price float,
rate float,
maxrate float,
categ text
)''')
各个字段从字面就很好理解。然后就是循环查询比较最高最低价格最经常出现的价格,我的做法是全比较完以后,一次repalce,这样的话一次插入的数据也就100多条。
7、后续的数据展示
最开始没想做界面,自己看数据用的Firefox的插件sqlite manager,后来发现还是不方便,就开始着手准备弄个界面,之前看过一阵wxpython、tkinter也看过,比较喜欢tk的简单。不过找来找去,发现tkinter的表格还真难找,发现了几个好东西,一个是别人用tk写的表格,看上去跟excel的效果差不多。后来为了省事,瞄准了ttk,tk8.5自带的treeview。
索性把自己的python从activepython的2.5.2换成了2.5.5,直接带的tk8.5。装完还得弄个pyttk的wrap,直接从python官网下载就好。最后形成的界面如下:
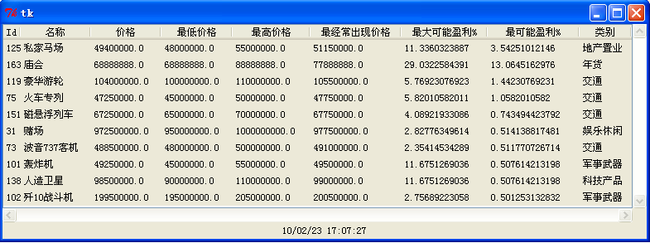
8、循环的问题
因为数据是每10分钟更新一次,那么程序需要10分钟定时转一次,没有界面好办,设置定时任务或者其他的都可以,tkinter我还是新手,只好借鉴了网上的用label显示时间的代码:
# def tick():
# global time1
# # get the current local time from the PC
# time2 = time.strftime('%H:%M:%S')
# # if time string has changed, update it
# if time2 != time1:
# time1 = time2
# clock.config(text=time2)
# # calls itself every 200 milliseconds
# # to update the time display as needed
# # could use >200 ms, but display gets jerky
# clock.after(200, tick)
稍加改造,加上判断时间,里面插入我们的登陆、处理比较以及刷新界面的函数,这样一个可以实时获取价格数据的程序基本完成。
9、后续改进
因为对python学的还不到家,所以很多地方错误处理还没做好,所以带宽差的话会假死,带宽足够的话,运行过几天,一直正常。
目前存在的问题:
1、获取数据的时候,label不会更新,因为没有开线程,看了些资料,准备把那一块改成线程,可能要用线程池。
2、希望能够改成web的方式,看看有没有可能弄到gae上去,毕竟gae已经有了cron,但是不清楚这么多请求,gae上能否实现。