SolrJ
http://www.ibm.com/developerworks/cn/java/j-solr-update/
在系列文章 使用 Apache Solr 实现更加灵巧的搜索 中,我借用了一个简单的客户机,它通过 Java 平台使用 Apache HTTPClient 与 Solr 通信。现在,在 1.3 版本中,Solr 提供了一个易于使用的、基于 Java 的 API,它避免了 HTTP 链接和 XML 命令的所有弊端。这个称为 SolrJ 的新客户机使得通过 Java 代码处理 Solr 更加轻松。SolrJ API 通过良好定义的方法调用简化了索引创建、搜索、排序和分类。
同样,简单的例子或许是最好的老师。样例下载 包含一个名为 SolrJExample.java 的 Java 文件。(参见下载中的 README.txt,查看有关编译的说明)。它展示了如何为 Solr 创建一些文档的索引,然后再运行一个对结果进行分类的查询。它做的第一件事是建立一个到 Solr 实例的连接,就像在 SolrServer server = new CommonsHttpSolrServer("http://localhost:8983/solr/rss"); 中一样。这会创建一个 SolrServer 实例,该实例通过 HTTP 和 Solr 通信。接下来,我将创建一个 SolrInputDocument,用它将要创建索引的内容打包起来,如清单 16 所示:
清单 16. 使用 SolrJ 创建索引
Collection<SolrInputDocument> docs = new HashSet<SolrInputDocument>();
for (int i = 0; i < 10; i++) {
SolrInputDocument doc = new SolrInputDocument();
doc.addField("link", "http://non-existent-url.foo/" + i + ".html");
doc.addField("source", "Blog #" + i);
doc.addField("source-link", "http://non-existent-url.foo/index.html");
doc.addField("subject", "Subject: " + i);
doc.addField("title", "Title: " + i);
doc.addField("content", "This is the " + i + "(th|nd|rd) piece of content.");
doc.addField("category", CATEGORIES[rand.nextInt(CATEGORIES.length)]);
doc.addField("rating", i);
//System.out.println("Doc[" + i + "] is " + doc);
docs.add(doc);
}
|
清单 16 中的循环只是创建了 SolrInputDocument(实际是一个夸张的 Map),然后给它添加 Field。我将它添加到了一个集合中,这样一次就能将所有的文档发送到 Solr。借助这个功能可以极大地加索引的创??,并减少通过 HTTP 发送请求导致的开销。然后我调用了 UpdateResponse response = server.add(docs);,它负责序列化文档并将其提交到 Solr。UpdateResponse 返回的值包含处理文档所用的时间的信息。为了让这些文档能够被搜索到,我又发出一个提交命令:server.commit();。
当然,创建索引之后必须查询服务器,如清单 17 带注释的代码所示:
清单 17. 查询服务器
//create the query
SolrQuery query = new SolrQuery("content:piece");
//indicate we want facets
query.setFacet(true);
//indicate what field to facet on
query.addFacetField("category");
//we only want facets that have at least one entry
query.setFacetMinCount(1);
//run the query
QueryResponse results = server.query(query);
System.out.println("Query Results: " + results);
//print out the facets
List<FacetField> facets = results.getFacetFields();
for (FacetField facet : facets) {
System.out.println("Facet:" + facet);
}
|
在这个简单的查询例子中,我设置了一个带有 content:piece 请求的 SolrQuery 实例。接下来,我表明自己对至少一个条目的所有的分类的分类信息感兴趣。最后,我通过 server.query(query) 调用提交查询,然后把一些结果打印了出来。这的确是一个过于简单的例子,但是它展示使用 Solr 时常见的任务,因此使您想到可以实现什么功能(突出显示、排序等)。要学习更多有关用 SolrJ 查询的可用选项的知识,请参见 参考资料 中的 SolrJ 链接。
直到 1.3 版本,Solr 才能通过复制轻松进行扩展,以满足更大容量的查询需求。但是,如果没有应用程序帮助完成大部分工作,要提供超出单个机器的承载额度的索引还是很困难的。例如,通常可以在 Solr 中设置多个服务器,其中每一个服务器都有自己的索引,然后再让应用程序来管理搜索 — 但这需要大量的自定义代码。在 1.3 版本中,Solr 添加了分布式搜索功能。应用程序将文档分布到几个计算机上,Solr(和其他程序)通常称之为片(shard)。每一个片都包含自己的独立索引,而且 Solr 能够跨片协调索引查询。不幸的是,应用程序仍然需要将要创建索引的文档发送到每一个片,但这可能会添加到将来的 Solr 版本中。同时,可以使用一个简单的散列函数根据文档的唯一 ID 确定将文档发送到什么片。与此同时,我将关注搜索的等式方面。
|
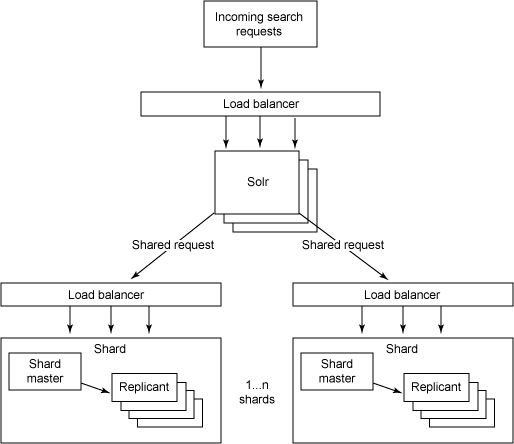
要开始使用分布式搜索,用户需要花些时间考虑架构。如果仅需要几个片,而且不考虑复制的话,那么可以在每个机器上放置一个片,并且每一个片都能够创建索引和提供搜索。但如果索引和查询量很大的话,就必须复制每一个片。设置这种系统的常用的方法就是将每一个片及其复制放到一个载入平衡器的后面。图 2 展示了这个架构:
图 2. 分布式和复制 Solr 架构
|
注意,图 2 中输入的请求可以进入任何一个复制的片中,因为它们是功能齐全的 Solr 实例。然后,检索节点会将请求发送到其他片。这些请求仅仅是普通的 Solr 请求。要将请求提交到 Solr 服务器并分发请求,需要将 shards 参数添加到请求,比如:
http://localhost:8983/solr/select? shards=localhost:8983/solr,localhost:7574/solr&q=ipod+solr |
在这个例子中,我假定在本地主机上运行了两个 Solr 服务器(它不是真正的分布式的;它适合于这里的论述,但不能用于您的设置),主服务器在端口 8983 上,从服务器在端口 7574 上。输入的请求进入端口 8983 上的实例,然后它将请求发送到片式服务器上。应用程序很可能将 shards 参数值设置成 solrconfig.xml 文件中的 SolrRequestHandler 的默认配置的一部分,这样就不需要在每次查询时都传入所有片式服务器的名称了。