mysql内核分析--innodb动态数组内部实现(上) (摘自老杨)
1. 动态数组概述
动态数组涉及的文件是innodb存储引擎的三个文件:dyn0dyn.h、dyn0dyn.ic以及dyn0dyn.c。
这是一个基本的组件功能,是作为一个动态的虚拟线性数组。数组的基本元素是byte。动态数组dyn主要用来存放mtr的锁定信息以及log。Dyn在实现上,如果block需要分裂节点,则会使用一个内存堆。每个blok块存储数据的数据字段的长度是固定的(默认值是512),但是不一定会完全用完。假设需要存储的数据项的尺寸大于数据块时,该数据项被分拆,这种情况主要用于log的缓冲。
2. 数据结构
typedef struct dyn_block_struct dyn_block_t;
typedef dyn_block_t dyn_array_t;
#define DYN_ARRAY_DATA_SIZE 512
struct dyn_block_struct{
mem_heap_t* heap;
ulint used;
byte data[DYN_ARRAY_DATA_SIZE];
UT_LIST_BASE_NODE_T(dyn_block_t) base;
UT_LIST_NODE_T(dyn_block_t) list;
#ifdef UNIV_DEBUG
ulint buf_end;
ulint magic_n;
#endif
};
//下面两个是公共宏定义,见ut0lst.h
#define UT_LIST_BASE_NODE_T(TYPE)\
struct {\
ulint count; /* count of nodes in list */\
TYPE * start; /* pointer to list start, NULL if empty */\
TYPE * end; /* pointer to list end, NULL if empty */\
}\
#define UT_LIST_NODE_T(TYPE)\
struct {\
TYPE * prev; /* pointer to the previous node,\
NULL if start of list */\
TYPE * next; /* pointer to next node, NULL if end of list */\
}\
字段解释:
1) heap
从字面上理解,heap是内存堆的意思。从上面的结构体中,我们可以看出,dyn_array_t就是dyn_block_struct。这个结构体里面的字段date用来存放数据,used显示已经使用的字节数量,假设这时候还要存储一个长度为x的数据,这时候data里面已经存储不了,所以就需要再分配一个新的block节点。那么分配结构所需要的内存从哪里来了,就从第一个节点里面的heap里面分配。
这里面,我们还需要注意一点。虽然数据结构用的是同一个dyn_block_struct,但是我们称第一个节点为arr,表明这个是动态数组的头节点。其它的节点,我们称为block节点。
我们这里面先来看看,创立dyn的函数是怎么实现的:
UNIV_INLINE
dyn_array_t*
dyn_array_create(
/*=============*/
/* out: initialized dyn array */
dyn_array_t* arr) /* in: pointer to a memory buffer of
size sizeof(dyn_array_t) */
{
ut_ad(arr);
ut_ad(DYN_ARRAY_DATA_SIZE < DYN_BLOCK_FULL_FLAG);
arr->heap = NULL;
arr->used = 0;
#ifdef UNIV_DEBUG
arr->buf_end = 0;
arr->magic_n = DYN_BLOCK_MAGIC_N;
#endif
return(arr);
}
其中的ud_ad是属于宏判断,相当于assert。这个我们暂时不表。这个函数是在mtr创建的时候来调用的,在调用的时候已经分配了arr指针。
在dyn_array_create函数中,系统将heap字段设置为NULL,Used设置为0。Buf_end和magic_n是调试的时候使用的,每个结构体定义都会唯一的对应一个magic_n值。这样在调试的时候,就可以快速进行问题的跟踪。
下面一个问题是,既然heap在起初的设置为NULL,那么什么时候分配给它值?是第一次分配block成员的时候?还是每次分配block成员的时候?
我们这里暂不分析如何插入,我们先看看,当dyn数组已经数据不够用的时候,我们怎么给这个arr增加一个新的block。代码如下:
dyn_block_t*
dyn_array_add_block(
/*================*/
/* out: created block */
dyn_array_t* arr) /* in: dyn array */
{
mem_heap_t* heap;
dyn_block_t* block;
ut_ad(arr);
ut_ad(arr->magic_n == DYN_BLOCK_MAGIC_N);
if (arr->heap == NULL) {
UT_LIST_INIT(arr->base);
UT_LIST_ADD_FIRST(list, arr->base, arr);
arr->heap = mem_heap_create(sizeof(dyn_block_t));
}
block = dyn_array_get_last_block(arr);
block->used = block->used | DYN_BLOCK_FULL_FLAG;
heap = arr->heap;
block = mem_heap_alloc(heap, sizeof(dyn_block_t));
block->used = 0;
UT_LIST_ADD_LAST(list, arr->base, block);
return(block);
}
代码中,我们可以看出,第一次增加block的时候,因为“arr->heap == NULL”条件为真,就会创建一个heap堆,在以后的再增加block时,就会使用的该堆直接分配。所以,我们可以得知,对于dyn动态数组,只有首节点的heap才是有效的。
好,那我们通过图形来看下,增加新节点之后的图形变化。

|
|
|
used |
|
data |
|
base |
|
list |
|
…… |
|
图1.只有一个节点 |
|
NULL |
|
指示data字段被使用的字节数字。 |
|
这是个线性链表的头节点。此时该值为NULL。只在首节点中有效。存储指针。 |
|
指向前一个、下一个节点指针。此时为NULL。 |
图1表示的是只有一个节点时的情况,当节点分裂时的变化,见图2。
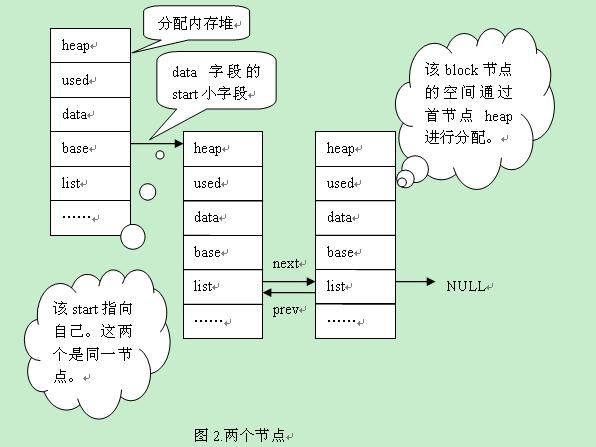
|
heap |
|
used |
|
data |
|
base |
|
list |
|
…… |
|
图2.两个节点 |
|
分配内存堆 |
|
heap |
|
used |
|
data |
|
base |
|
list |
|
…… |
|
data字段的start小字段 |
|
heap |
|
used |
|
data |
|
base |
|
list |
|
…… |
|
next |
|
prev |
|
NULL |
|
该start指向自己。这两个是同一节点。 |
|
该block节点的空间通过首节点heap进行分配。 |
通过图2,并集合前面的代码,我们可以发现,从第一个节点,变为两个节点的时候,首节点先把自己挂到base链表中,并分配一个新的节点,挂在base的最后一个节点。链表中的节点通过list进行互连。同样,如果还需要再增加一个节点,那么就在base链表的结尾再增加一个。因为是新增节点,所以设置该节点的used值为0。
我们在关注一下这一行代码:
block->used = block->used | DYN_BLOCK_FULL_FLAG;
从这一行代码,我们可以猜想一下该行代码的含义:
a) FULL表明该节点已经完全使用完,不可以再使用其中的空间。所以,链表只有最后一个节点才是可以使用的。每增加一个节点,总要设置前面一个节点的DYN_BLOCK_FULL_FLAG。
b) 每个块,data数组的预设值是DYN_ARRAY_DATA_SIZE(值为512),
#define DYN_BLOCK_FULL_FLAG 0x1000000UL
所以,use的值小于等于512,那么该节点为尾节点。因为非尾节点的值肯定大于512,它与DYN_BLOCK_FULL_FLAG进行了或操作。