测试环境
写道
服务器A:192.168.0.219
服务器B:192.168.0.8
A,B已设置为互为主从备份,测试数据库为test-xf
现test-xf库有数据表tb_mobile
服务器B:192.168.0.8
A,B已设置为互为主从备份,测试数据库为test-xf
现test-xf库有数据表tb_mobile
测试一:停掉某台mysql服务
A:sudo /etc/init.d/mysql stop xiaofei@xiaofei-desktop:~$ sudo /etc/init.d/mysql stop [sudo] password for xiaofei: Shutting down MySQL .. * 我停掉A服务器的mysql服务. 接着我向B服务器的tb_mobile表中插入新数据,然后再开启A服务器看状态如何. B库中tb_mobile表现在如图B_old,插入一条88888888的数据之如B_new


写道
现在A服务器是mysql的服务是停止的.如A_old
写道
我们重新启动A服务器的mysql服务;
xiaofei@xiaofei-desktop:~$ sudo /etc/init.d/mysql start
Starting MySQL
.. *
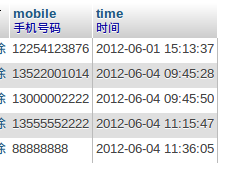
我们再进A服务器的test-xf库下的tb_mobile表中看看.如图:A_new
xiaofei@xiaofei-desktop:~$ sudo /etc/init.d/mysql start
Starting MySQL
.. *
我们再进A服务器的test-xf库下的tb_mobile表中看看.如图:A_new
写道
我们发现A服务器的数据已经自动同步了.同样,我停掉B的mysql服务后,往A插入数据,恢复B后,数据也已经自动同步了.
测试二:断网测试同时为测试表加上一个ID的自增字段
写道
有种预感,有了自增变量后,在双方不通的情况下,双方都有增加数据,恢复通讯后同步会出现问题.
我在断开本机网络之后.先在A(本机)插入一条数据,id=19
去到另一台机打开B查看此时还没有同步,我再B上插入一条数据,id就=20了,
这时放开网络后,二边都同步了,至于为什么B的自增ID已20开始,肯定是某些设置参数的原因.
刚才是插入奇数条数据(1条)测试,接着我插入偶数(2条)来测试一下.
断网之后,我先在B上插入二条数据,id=22,id=24
随后我去A上插入二条数据,id=21,id=23.
通讯之后,二边同步成功.
查找原因:
多次插入数据后发现.A自增id是奇数,step=1,B自增id是偶数,step=1.
比如:现在A,B二边数据一样,最大id=26.你在A插入一条数据后,id=27,再插入一条,id=29,以此类推...
当id=29后,你去B中插入数据,id=30,再插入id=32,以此类推....
是这么二个参数对自增字段起的作用..
A:
auto_increment_offset = 1
auto_increment_increment = 2
B:
auto_increment_offset = 2
auto_increment_increment = 2
auto_increment_offset和auto_increment_increment
auto_increment_increment和auto_increment_offset用于主-主服务器(master-to-master)复制,并可以用来控制AUTO_INCREMENT列的操作。两个变量均可以设置为全局或局部变量,并且假定每个值都可以为1到65,535之间的整数值。将其中一个变量设置为0会使该变量为1。
这两个变量影响AUTO_INCREMENT列的方式:auto_increment_increment控制列中的值的增量值,auto_increment_offset确定AUTO_INCREMENT列值的起点。
如果auto_increment_offset的值大于auto_increment_increment的值,则auto_increment_offset的值被忽略。例如:表内已有一些数据,就会用现在已有的最大的自增值做为初始值。
假如我们现在有四台机器那设置应该如下:
A:
auto_increment_offset = 1
auto_increment_increment = 4
B:
auto_increment_offset = 2
auto_increment_increment = 4
C:
auto_increment_offset = 3
auto_increment_increment = 4
D:
auto_increment_offset = 4
auto_increment_increment = 4
但是这样设置的话那id不是跳得很厉害 :)
我在断开本机网络之后.先在A(本机)插入一条数据,id=19
去到另一台机打开B查看此时还没有同步,我再B上插入一条数据,id就=20了,
这时放开网络后,二边都同步了,至于为什么B的自增ID已20开始,肯定是某些设置参数的原因.
刚才是插入奇数条数据(1条)测试,接着我插入偶数(2条)来测试一下.
断网之后,我先在B上插入二条数据,id=22,id=24
随后我去A上插入二条数据,id=21,id=23.
通讯之后,二边同步成功.
查找原因:
多次插入数据后发现.A自增id是奇数,step=1,B自增id是偶数,step=1.
比如:现在A,B二边数据一样,最大id=26.你在A插入一条数据后,id=27,再插入一条,id=29,以此类推...
当id=29后,你去B中插入数据,id=30,再插入id=32,以此类推....
是这么二个参数对自增字段起的作用..
A:
auto_increment_offset = 1
auto_increment_increment = 2
B:
auto_increment_offset = 2
auto_increment_increment = 2
auto_increment_offset和auto_increment_increment
auto_increment_increment和auto_increment_offset用于主-主服务器(master-to-master)复制,并可以用来控制AUTO_INCREMENT列的操作。两个变量均可以设置为全局或局部变量,并且假定每个值都可以为1到65,535之间的整数值。将其中一个变量设置为0会使该变量为1。
这两个变量影响AUTO_INCREMENT列的方式:auto_increment_increment控制列中的值的增量值,auto_increment_offset确定AUTO_INCREMENT列值的起点。
如果auto_increment_offset的值大于auto_increment_increment的值,则auto_increment_offset的值被忽略。例如:表内已有一些数据,就会用现在已有的最大的自增值做为初始值。
假如我们现在有四台机器那设置应该如下:
A:
auto_increment_offset = 1
auto_increment_increment = 4
B:
auto_increment_offset = 2
auto_increment_increment = 4
C:
auto_increment_offset = 3
auto_increment_increment = 4
D:
auto_increment_offset = 4
auto_increment_increment = 4
但是这样设置的话那id不是跳得很厉害 :)
测试三:当一台机器当掉后,另一台机器能否接任
写道
当掉A机,继续向A机写数据,会是什么情况?B机会不会接管,数据会不会写到B机?
**结果是不会,当掉一台机后,你继续往它写数据,只能是提示你不能连接.数据也无法写入.
**结果是不会,当掉一台机后,你继续往它写数据,只能是提示你不能连接.数据也无法写入.
写道
关于MySQL-HA,目前有多种解决方案,比如heartbeat、drbd、mmm、共享存储,但是它们各有优缺点。
heartbeat、drbd配置较为复杂,需要自己写脚本才能实现MySQL自动切换,对于不会脚本语言的人来说,这无疑是一种脑裂问题;
对于mmm,生产环境中很少有人用,且mmm 管理端需要单独运行一台服务器上,要是想实现高可用,就得对mmm管理端做HA,这样无疑又增加了硬件开支;
对于共享存储,个人觉得MySQL数据还是放在本地较为安全,存储设备毕竟存在单点隐患。
使用MySQL双master+keepalived是一种非常好的解决方案,在MySQL-HA环境中,MySQL互为主从关系,这样就保证了两台MySQL数据的一致性,
然后用keepalived实现虚拟IP,通过keepalived自带的服务监控功能来实现MySQL故障时自动切换。
heartbeat、drbd配置较为复杂,需要自己写脚本才能实现MySQL自动切换,对于不会脚本语言的人来说,这无疑是一种脑裂问题;
对于mmm,生产环境中很少有人用,且mmm 管理端需要单独运行一台服务器上,要是想实现高可用,就得对mmm管理端做HA,这样无疑又增加了硬件开支;
对于共享存储,个人觉得MySQL数据还是放在本地较为安全,存储设备毕竟存在单点隐患。
使用MySQL双master+keepalived是一种非常好的解决方案,在MySQL-HA环境中,MySQL互为主从关系,这样就保证了两台MySQL数据的一致性,
然后用keepalived实现虚拟IP,通过keepalived自带的服务监控功能来实现MySQL故障时自动切换。
参考:
http://kb.cnblogs.com/page/83944/
http://xiaolin0199.iteye.com/blog/2017997