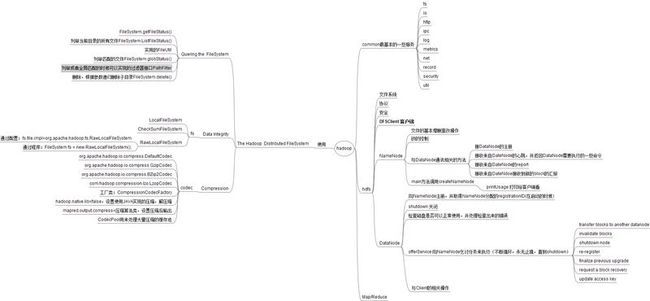
Hadoop读书笔记----(一)概览+访问HDFS
概览:
==================================== 邪恶的分割线 =======================
访问HDFS
一,通过JAVA的URL类直接访问HDFS
A,输入命令 bin/hadoop namenode -format
B,输入命令 bin/start-all.sh 启动单机模式
(前提是都配置好的情况下如果没有配置好可以参考http://hadoop.apache.org/common/docs/current/quickstart.html)
C,hdfs -copyFromLocal txy.txt /home/txy 拷贝一个文件进去
public class URLTest {
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[] args) throws MalformedURLException, IOException {
InputStream in = null;
try {
in = new URL("hdfs://localhost:9000/home/txy").openStream();
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
执行结果:
输出该拷贝进去的文件。
其中程序两个注意点:
1,
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
这个有个非常大的限制就是JVM只能调用一次这个,不能调用第二次来修改。
2,hdfs://localhost:9000 即 core-site.xml 这个配置文件配置的fs.default.name属性
3,自己遇到的一个小问题就是 客户端的jar包版本要和服务端的一样。 要不然会抛错
二,通过FileSystem访问(hadoop的API)
public class FileSystemCat {
public static void main(String[] args) throws Exception {
String uri = "hdfs://localhost:9000/home/txy";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
InputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
因为第一种方法有那么大的限制,所以基本是不可能使用的。所以可以采用第二种方案。
其中
Configuration conf = new Configuration();
会读取系统默认的配置conf/core-site.xml配置
而uri指定了schema是hdfs,如果不指定,将会读取默认的本地文件系统。
=========================== 善良的分割线 ======================
常见问题:
Exception in thread "main" java.io.IOException: Call to localhost/127.0.0.1:9000 failed on local exception: java.io.EOFException
报此错说明客户端hadoop版本和服务端hadoop版本不一致。