[转]LAMP 系统性能调优,第 1 部分: 理解 LAMP 架构
文章来源:http://www.ibm.com/developerworks/cn/linux/l-tune-lamp-1/index.html
LAMP 系统性能调优,第 1 部分: 理解 LAMP 架构LAMP 系统的工作原理、性能度量方法及底层操作系统的调优方法 |
级别: 中级 Sean A. Walberg ([email protected]), 高级网络工程师 2007 年 5 月 09 日 如今,使用 LAMP(Linux®、Apache、MySQL 和 PHP/Perl)架构的应用程序不断被开发和部署。 但是,服务器管理员对应用程序本身几乎没有控制能力,因为应用程序是别人编写的。这份共三部分的系列文章将讨论许多服务器配置问题,这些配置会影响应用程序的性能。第一篇文章讨论 LAMP 架构、一些性能度量技术以及一些基本的 Linux 内核、硬盘和文件系统调节。后续的文章将研究 Apache、MySQL 和 PHP 组件的调优。<!--START RESERVED FOR FUTURE USE INCLUDE FILES--><!-- include java script once we verify teams wants to use this and it will work on dbcs and cyrillic characters --><!--END RESERVED FOR FUTURE USE INCLUDE FILES--> Linux、Apache、MySQL 和 PHP(或 Perl)是许多 Web 应用程序的基础 —— 从 to-do 列表到 blog,再到电子商务站点。WordPress 和 Pligg 是两个支持大容量 Web 站点的常用软件包。这种架构简称为 LAMP。几乎每个 Linux 发布版都包含 Apache、MySQL、PHP 和 Perl,所以安装 LAMP 软件是非常容易的。 安装的简便性使人误以为这些软件会自行顺利地运行,但是实际情况并非如此。最终,应用程序的负载会超出后端服务器自带设置的处理能力,应用程序的性能会降低。LAMP 安装需要不断监控、调优和评估。 系统调优对于不同的人有不同的含义。本系列主要关注 LAMP 组件(Linux、Apache、MySQL 和 PHP)的调优。对应用程序本身进行调优是另一个复杂的问题。应用程序和后端服务器之间存在一种共生关系:未能适当调优的服务器甚至会使最好的应用程序在负载之下崩溃,而借助充分的调优,完全可以避免编写得很糟糕的应用程序使服务器缓慢如牛。幸运的是,正确的系统调优和监视可以指出应用程序中的问题。 对任何系统进行调优的第一步都是了解它的工作原理。按照最简单的形式,基于 LAMP 的应用程序是用 PHP 这样的脚本语言编写的,它们作为 Linux 主机上运行的 Apache Web 服务器的一部分运行。 PHP 应用程序通过请求的 URL、所有表单数据和已捕获的任意会话信息从客户机获得信息,从而确定应该执行什么操作。如有必要,服务器会从 MySQL 数据库(也在 Linux 上运行)获得信息,将这些信息与一些 Hypertext Markup Language(HTML)模板组合在一起,并将结果返回给客户机。当用户在应用程序中导航时,这个过程重复进行;当多个用户访问系统时,这个过程会并发进行。但是,数据流不是单向的,因为可以用来自用户的信息更新数据库,包括会话数据、统计数据(包括投票)和用户提交的内容(比如评论或站点更新)。除了动态元素之外,还有静态元素,比如图像、JavaScript 代码和层叠样式表(CSS)。
在研究 LAMP 系统中的请求流之后,就来看看可能出现性能瓶颈的地方。数据库提供许多动态信息,所以数据库对查询的响应延迟都会反映在客户机中。Web 服务器必须能够快速地执行脚本,还要能够处理多个并发请求。最后,底层操作系统必须处于良好的状态才能支持应用程序。通过网络在不同服务器之间共享文件的其他设置也可能成为瓶颈。 持续地对性能进行度量在两个方面有帮助。首先,度量可以帮助了解性能趋势,包括好坏两方面的趋势。作为一个简单的方法,查看一下 Web 服务器上的中央处理单元(CPU)使用率,就可以了解 CPU 是否负载过重。同样,查看过去使用的总带宽并推断未来的变化,可以帮助判断什么时候需要进行网络升级。这些度量最好与其他度量和观测结合考虑。例如,当用户抱怨应用程序太慢时,可以检查磁盘操作是否达到了最大容量。 性能度量的第二个用途是,判断调优是对系统性能有帮助,还是使它更糟糕了。方法是比较修改之前和之后的度量结果。但是,为了进行有效的比较,每次应该只修改一个设置,然后对适当的指标进行比较以判断修改的效果。每次只修改一个设置的原因应该是很明显的:同时做出的两个修改很可能会相互影响。选择用来进行比较的指标比较微妙。 选择的指标必须能够反映应用程序用户感觉到的响应。如果一项修改的目标是减少数据库的内存占用量,那么取消各种缓冲区肯定会有帮助,但是这会牺牲查询速度和应用程序性能。所以,应该选择应用程序响应时间这样的指标,这会使调优向着正确的方向发展,而不仅仅是针对数据库内存使用量。 可以以许多方式度量应用程序响应时间。最简单的方法可能是使用 清单 1. 使用 cURL 度量 Web 站点的响应时间
清单 1 给出对一个流行的新闻站点执行 表 1. curl 使用的计时器
这些计时器都相对于事务的起始时间,甚至要先于 Domain Name Service(DNS)查询。因此,在发出请求之后,Web 服务器处理请求并开始发回数据所用的时间是 0.272 - 0.081 = 0.191 秒。客户机从服务器下载数据所用的时间是 0.779 - 0.272 = 0.507 秒。 通过观察 当然,Web 站点不仅仅由页面组成。它还有图像、JavaScript 代码、CSS 和 cookie 要处理。 用于 Firefox 浏览器的 Tamper Data 扩展(参见 参考资料 一节中的链接)可以在日志中记录 Web 浏览器发出的每个请求,并显示每个请求所用的下载时间。使用这个扩展的方法是,选择 Tools > Tamper Data 来打开 Ongoing requests 窗口。装载要考察的页面,然后就会看到浏览器发出的每个请求的状态和装载每个元素所用的时间。图 1 给出装载 developerWorks 主页的结果。 图 1. 用于装载 developerWorks 主页的请求细目 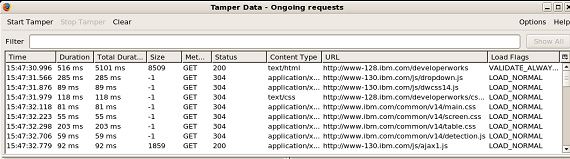 每一行描述一个元素的装载情况。显示的数据包括发出请求的时间、装载所用的时间、大小和结果。Duration 栏列出装载元素本身所用的时间,Total Duration 栏列出所有子元素所用的时间。在图 1 中,装载主要页面所用的时间是 516 毫秒(ms),但是装载所有东西并显示整个页面所用的时间是 5101 ms。 Tamper Data 扩展有一种有用的模式,将页面装载数据的输出绘制成图形。右击 Ongoing requests 窗口上半部分的任何地方,并选择 Graph all。图 2 显示图 1 中数据的图形化视图。 图 2. 用于装载 developerWorks 主页的请求的图形化视图 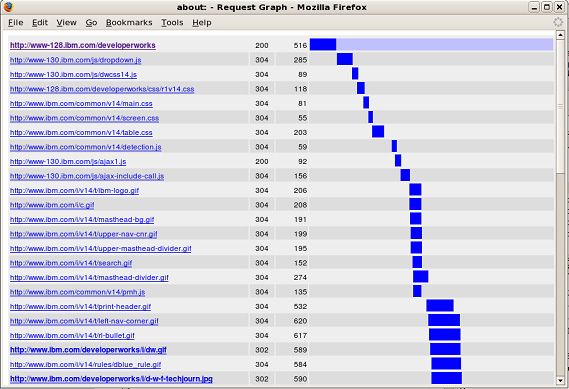 在图 2 中,每个请求的持续时间显示为深蓝色,并相对于页面装载的启始时间显示。所以,可以看出哪些请求使整个页面的装载变慢了。 尽管关注的重点是页面装载时间和用户体验,但是也不要忽视核心系统指标,比如磁盘、内存和网络。有许多实用程序可以捕获这些信息;其中最有帮助的可能是
在对系统的 Apache、PHP 和 MySQL 组件进行调优之前,应该花一些时间确保底层 Linux 组件的运行正常。还应该对正在运行的服务进行缩减,只运行需要的那些服务。这不但是一种良好的安全实践,而且可以节省内存和 CPU 时间。 大多数 Linux 发布版都定义了适当的缓冲区和其他 Transmission Control Protocol(TCP)参数。可以修改这些参数来分配更多的内存,从而改进网络性能。设置内核参数的方法是通过 清单 2. 包含较为激进的网络设置的 /etc/sysctl.conf
将这些设置添加到 启用 TCP 窗口伸缩使客户机能够以更高的速度下载数据。TCP 允许在未从远程端收到确认的情况下发送多个数据包,默认设置是最多 64 KB,在与延迟比较大的远程客户机进行通信时这个设置可能不够。窗口伸缩会在头中启用更多的位,从而增加窗口大小。 后面四个配置项增加 TCP 发送和接收缓冲区。这使应用程序可以更快地丢掉它的数据,从而为另一个请求服务。还可以强化远程客户机在服务器繁忙时发送数据的能力。 最后一个配置项增加可用的本地端口数量,这样就增加了可以同时服务的最大连接数量。 在下一次引导系统时,或者下一次运行 磁盘在 LAMP 架构中扮演着重要的角色。静态文件、模板和代码都来自磁盘,组成数据库的数据表和索引也来自磁盘。对磁盘的许多调优(尤其是对于数据库)集中于避免磁盘访问,因为磁盘访问的延迟相当高。因此,花一些时间对磁盘硬件进行优化是有意义的。 首先要做的是,确保在文件系统上禁用 清单 3. 演示如何启用 noatime 的 fstab 示例
在清单 3 中只修改了 ext3 文件系统,因为 有多种磁盘硬件组合,而且 Linux 不一定能够探测出访问磁盘的最佳方式。可以使用 清单 4. 在 /dev/hd 上执行的速度测试
这一测试说明,在这个磁盘上读取数据的速度是大约每秒 60 MB。 在尝试一些磁盘调优选项之前,必须注意一个问题。错误的设置可能损害文件系统。有时候会出现一个警告,指出这个选项与硬件不兼容;但是,有时候没有警告消息。因此,在将系统投入生产之前,必须对设置进行彻底的测试。在所有服务器上都采用标准的硬件也会有所帮助。 表 2 列出比较常用的一些选项。 表 2. hdparm 的常用选项
不幸的是,对于 Fiber Channel and Small Computer Systems Interface(SCSI)系统,调优依赖于具体的驱动器。 必须将有帮助的设置添加到启动脚本中,比如 网络文件系统(NFS)是一种通过网络共享磁盘的方法。NFS 可以帮助确保每个主机具有相同数据的拷贝,并确保修改反映在所有节点上。但是,在默认情况下,NFS 的配置不适合大容量磁盘。 每个客户机应该用
可以将这些设置放在 在服务器端,一定要确保有足够的 NFS 内核线程来处理所有客户机。在默认情况下,只启动一个线程,但是 Red Hat 和 Fedora 系统会启动 8 个线程。对于繁忙的 NFS 服务器,应该提高这个数字,比如 32 或 64。可以用 清单 5. 显示 NFS 客户机的 RPC 统计数据
第二列 关于 NFS,最后要注意一点:如果可能的话,应该避免使用 NFSv2,因为 NFSv2 的性能比 v3 和 v4 差得多。在现代的 Linux 发行版中这应该不是问题,但是可以在服务器上检查
本文讨论了 LAMP 的一些基本知识以及 LAMP 安装的一些简单 Linux 调优措施。除了 NFS 内核线程之外,可以设置本文中讨论的参数,然后就不用理会它们了。本系列中的后两篇文章主要关注 Apache、MySQL 和 PHP 调优。这些组件的调优与 Linux 的调优有很大的差异,因为随着通信量的增长、读写操作分布情况的变化和应用程序的演化,需要不断重新考察这些参数。 |