公用表表达式
公用表表达式 (CTE) 具有一个重要的优点,那就是能够引用其自身,从而创建递归 CTE 。递归 CTE 是一个重复执行初始 CTE 以返回数据子集直到获取完整结果集的公用表表达式。
递归 CTE 可以极大地简化在 SELECT 、 INSERT 、 UPDATE 、 DELETE 或 CREATE VIEW 语句中运行递归查询所需的代码。
递归 CTE 的结构
递归 CTE 由下列三个元素组成:
1. 例程的调用。
递归 CTE 的第一个调用包括一个或多个由 UNION ALL 、 UNION 、 EXCEPT 或 INTERSECT 运算符联接的 CTE_query_definitions 。由于这些查询定义形成了 CTE 结构的基准结果集,所以它们被称为 “ 定位点成员 ” 。
CTE_query_definitions 被视为定位点成员,除非它们引用了 CTE 本身。所有定位点成员查询定义必须放置在第一个递归成员定义之前,而且必须使用 UNION ALL 运算符联接最后一个定位点成员和第一个递归成员。
2. 例程的递归调用。
递归调用包括一个或多个由引用 CTE 本身的 UNION ALL 运算符联接的 CTE_query_definitions 。这些查询定义被称为 “ 递归成员 ” 。
3. 终止检查。
终止检查是隐式的;当上一个调用中未返回行时,递归将停止。
| 注意: |
| 如果递归 CTE 组合不正确,可能会导致无限循环。例如,如果递归成员查询定义对父列和子列返回相同的值,则会造成无限循环。在测试递归查询的结果时,可以通过在 INSERT 、 UPDATE 、 DELETE 或 SELECT 语句的 OPTION 子句中使用 MAXRECURSION 提示和 0 到 32,767 之间的值,来限制特定语句允许的递归级数。 |
伪代码和语义
递归 CTE 结构必须至少包含一个定位点成员和一个递归成员。以下伪代码显示了包含一个定位点成员和一个递归成员的简单递归 CTE 的组件。
WITH cte_name ( column_name [ ,... n ] )
AS
(
CTE_query_definition -- Anchor member is defined.
UNION ALL
CTE_query_definition -- Recursive member is defined referencing cte_name.
)
-- Statement using the CTE
SELECT *
FROM cte_name
递归执行的语义如下:
1. 将 CTE 表达式拆分为定位点成员和递归成员。
2. 运行定位点成员,创建第一个调用或基准结果集 (T 0 ) 。
3. 运行递归成员,将 T i 作为输入,将 T i+1 作为输出。
4. 重复步骤 3 ,直到返回空集。
5. 返回结果集。这是对 T 0 到 T n 执行 UNION ALL 的结果。
下面举两个例子,
例子 1 :
CREATE TABLE Test ( Name VARCHAR ( 50 ), Parentname VARCHAR ( 50 ));
INSERT INTO Test values (' 仙桃 ',' 湖北 '),(' 湖北 ',' 中国 ')
INSERT INTO Test (name) values (' 中国 ')
需求:查询一个名称的所有,上级名称。如仙桃,则是 中国湖北仙桃,湖北,则是 中国湖北。
with city ( str , name , Parentname )
as ( select name , name , Parentname from test where name = ' 仙桃 '
UNION ALL
select a . str || b . name , b . name , b . Parentname from city a , test b
where a . Parentname = b . name
)
select * from city

可以看到,结果集是递归程序每一步的结果的并集。我们需要的结果是第三个。可以改一下select语句
select * from city where partentname is null
例子 2 :
CREATE TABLE Test ( User_Name VARCHAR ( 12 ), City VARCHAR ( 12 ));
INSERT INTO Test ( User_Name , City )
values (' 张三 ',' 杭州 '),(' 张三 ',' 郑州 '),(' 李四 ',' 杭州 '),
(' 张三 ',' 南昌 '),(' 李四 ',' 广州 '),(' 王五 ',' 北京 ');
表如下:
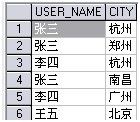
需求:查找每个人到过的所有城市。
这相当于一个字符串分组连接的例子。可以利用双重 FOR 循环来解决。第一个 FOR ,循环名字,第二个 FOR ,根据名字来循环城市。也可以利用 with 语句来实现。
这里使用两个 with ,第一个的记录如下:
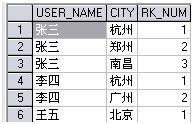
我们只要再构建一个结果集,控制 RK_NUM 的值为 1 , 2 , 3 ,然后两个表关联查询就可以得到结果。
第二个初始时有三个记录,如下 :
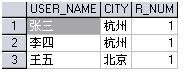
第二次 ,R_NUM = 1, 所以当 RK_NUM =R_NUM+1 时 , 是表一中 RK_NUM = 2 的记录
第三次 ,R_NUM = 2, 所以当 RK_NUM =R_NUM+1 时 , 是表一中 RK_NUM = 3 的记录
这样一直循环下去,直到找不到记录为止。
语句如下 :
WITH R1 ( User_Name , City , Rk_Num ) as (
SELECT User_Name , City , ROW_NUMBER () OVER ( PARTITION BY User_Name ) FROM test
),
R2 ( User_Name , City , R_Num ) as (
SELECT User_Name , CAST ( City AS VARCHAR ( 100 )), Rk_Num from R1 WHERE Rk_Num = 1
UNION ALL
SELECT R2 . User_Name , CAST ( R2 . City || '#' || R1 . City AS VARCHAR ( 100 )), R1 . RK_Num
from R2 , R1
WHERE R2 . User_Name = R1 . User_Name and R2 . R_Num + 1 = R1 . Rk_Num
)
SELECT * FROM R2
结果 :
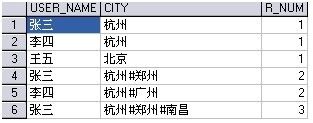
可以发现,根据名字分组后的每组 R_NUM 的最大值是需要的结果,那么可以这样写 WITH 后面的 select 语句 :
SELECT a . User_name , a . city
FROM R2 a ,( SELECT User_Name , max ( R_Num ) R_Num from R2 GROUP BY User_Name ) b
where a . User_name = b . User_name and a . R_Num = b . R_Num
结果如下 :
