java 容器(持有对象)
java 容器,也是面试当中问的频率比较高的问题。下面贴一张 thinking in java中的集合类库的完备图。
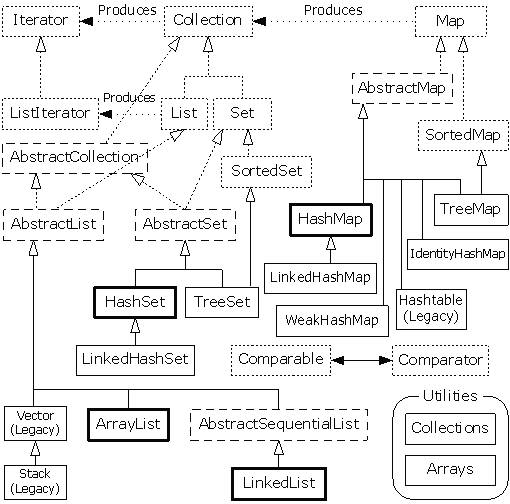
图中不包括queue的实现。虚线框表示abstract类,这些类可能看起来有些困惑,但是他们只是实现了特定接口的工具。如果你在创建自己的set,那么并不用从Set接口开始并实现其中的全部方法,只需要从AbstractSet继承,然后创建新类必须的的工作。事实上容器类库已经包含了足够多的功能,任何时候都可以满足我们的需求,因此,我们通常可以忽略那些Abstract的类。
下面介绍下,容器类当中这些接口,类各自的特性。
Collection:一个独立的元素的序列,这些元素都服从一条或者多条规则。
List 必须按照插入的顺序保存元素。
Set 不能有重复的元素。
Queue 按照排队规则来确定对象的产生的顺序(通常与他们的插入顺序相同,但有些实现是基于优先级的排序,priorityQueue实现的优先级是通过Comparator实现优先级规则)。
通常,Queue只允许在容器的一端插入对象, 在容器的另外一端移除对象。
Map :一组成对的“键值对”对象,允许通过键查找值。List的get方法允许我们通过数字,即索引,相当于数组的下标来获取对象,map映射表允许我们通过另一个对象来查找某个对象,也被称作“关联数组”,因为他是将某些对象关联在一起。也称“字典”,可以通过像字典中使用的目录来查找对象,Map是强大的编程工具。
List:承诺可以将元素维护在特定的序列中。list在collection的基础上添加了大量的方法。使得可以在list的中间插入和移除元素。
有两种类型的List :基本的ArrayList(非同步),擅长随机访问元素,但是在List 中插入,移除元素较慢。LInkedList,它是通过代价较低的List中间进行插入和删除操作,提供了优化的顺序访问。LinkedList在随机访问方面相对比较慢,但它的特性集较ArrayList更大。 LinkedList:(非同步)在拥有和List相同的特性外,还添加了可以使用其作为 栈,队列或双端队列的方法。 基于LinekedList 的数据结构是链表,因此也可以用来实现Stack,Queue。
Stack:(线程安全)实现了 LIFO 堆栈操作的更完整和更一致。stack是继承自Vector。
Vector:(线程安全)的可增长的对象数组。
Set : 是不允许重复元素。Set 中最常用的就是测试归属 性。可以很容易的询问某个元素是否存在某个Set中。所以查找就变成了Set中最重要的操作。因此你可以选择HashSet的实
现。它是通过散列函数,对快速查找做了优化。此外 Set接口和Collection接口是完全一样的方法。没有任何额外的功能,实际上Set就是Collection只是行为不同。
也有两种类型的Set:没有顺序的HashSet(非同步) ,也是上面提到的通过散列函数自己维护期内部的序列,所以让用户看起来是无序的。此外,HashSet的实现其实是一个HashMap的keyset。因此它允许有一个空的值,且不能重复。另外一种就是TreeSet(非同步)是将元素存储在红黑树数据结构中,如果你需要对Set排序就可以选择treeSet,treeSet对元素用自然顺序排序,或者根据创建set 时提供的 Comparator 进行排序,具体取决于使用的构造方法。LInkedHashSet:(非同步)保持了元素的插入顺序的Set,通过散列优化了访问速度。
Map: 已经实现的有类有:HashMap :非同步的。影响其性能 :初始容量 和加载因子。容量 是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。加载因子 是哈希表在其容量
自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
hashTable:同步的。 他的实例有两个参数影响其性能:初始容量 和加载因子。容量 是哈希表中桶 的数量,初始容量 就是哈希表创建时的容量。注意,哈希表的状态为 open:在发生“哈希冲突”的情况下,单个桶会存储多个条目,这些条目必须按顺序搜索。加载因子 是对哈希表在其容量自动增加之前可以达到多满的一个尺度。初始容量和加载因子这两个参数只是对该实现的提示。关于何时以及是否调用 rehash 方法的具体细节则依赖于该实现。
另外TreeMap:非同步的。排序的Map实现。
LInkedHashMap:(非同步)保持了元素的插入顺序,也是通过散列函数提供了快速的访问能力。
Queue:除了基本的 Collection 操作外,队列还提供其他的插入、提取和检查操作。每个方法都存在两种形式:一种抛出异常(操作失败时),另一种返回一个特殊值(null 或 false,具体取决于操作)。插入操作的后一种形式是用于专门为有容量限制的 Queue 实现设计的;在大多数实现中,插入操作不会失败。
PriorityQueue :非同步的优先级堆的无界优先级队列。优先级队列的元素按照其自然顺序进行排序,或者根据构造队列时提供的 Comparator 进行排序,具体取决于所使用的构造方法。优先级队列不允许使用 null 元素。依靠自然顺序的优先级队列还不允许插入不可比较的对象(这样做可能导致 ClassCastException)。另外一个实现了Queue接口的就是LinkedList .
上面基本上是常用到的集合类。以及各自的特点。具体的方法,功能,已经实现有兴趣的可以 看一下源代码,你会发现很多有趣的东西。 此外,在java容器里面还有两个接口是一定要
提的:Iterator 和 Comparable。
Iterator :对 collection 进行迭代的迭代器。该接口就三个方法:boolean hasNext(),E next() ,void remove()。
Comparable:此接口强行对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序,类的 compareTo 方法被称为它的自然比较方法。而且这个接口就只有唯一一个方法。
最后是对java 持有对象的一个小结:
1,数组将数字与对象关联起来,它保存明确类型的对象,查询时不需要对结果做转换,也可以是多维的,可以保存基本数据类型。但是数组一旦生成,其容量不能改变。
2,Collection保存单一元素,而map 保存关联的键值对。有了java泛型,也可以指定容器中的存放对象类型,获取的时候就不必转换。容器类可以在你向其中添加更多的数据的时候自动调整其尺寸。容器不能持有基本数据类型,但是自动包装机制会自动的对到容器中的基本类型自动拆装箱。
3,如果要进行大量的随机访问,就是用ArrayList ,如果要经常进行插入删除操作,则应该使用:LinkedList。
4, 除了TreeSet以外的Set都拥有和Collection完全一样的接口。List,Collection存在明显的不同,尽管List 要求的方法都在Collection中。Queue中的方法都是独立的。Map 和Collection接口是重叠的,Map可以使用entrySet方法,values()产生Collection.
图中不包括queue的实现。虚线框表示abstract类,这些类可能看起来有些困惑,但是他们只是实现了特定接口的工具。如果你在创建自己的set,那么并不用从Set接口开始并实现其中的全部方法,只需要从AbstractSet继承,然后创建新类必须的的工作。事实上容器类库已经包含了足够多的功能,任何时候都可以满足我们的需求,因此,我们通常可以忽略那些Abstract的类。
下面介绍下,容器类当中这些接口,类各自的特性。
Collection:一个独立的元素的序列,这些元素都服从一条或者多条规则。
List 必须按照插入的顺序保存元素。
Set 不能有重复的元素。
Queue 按照排队规则来确定对象的产生的顺序(通常与他们的插入顺序相同,但有些实现是基于优先级的排序,priorityQueue实现的优先级是通过Comparator实现优先级规则)。
通常,Queue只允许在容器的一端插入对象, 在容器的另外一端移除对象。
Map :一组成对的“键值对”对象,允许通过键查找值。List的get方法允许我们通过数字,即索引,相当于数组的下标来获取对象,map映射表允许我们通过另一个对象来查找某个对象,也被称作“关联数组”,因为他是将某些对象关联在一起。也称“字典”,可以通过像字典中使用的目录来查找对象,Map是强大的编程工具。
List:承诺可以将元素维护在特定的序列中。list在collection的基础上添加了大量的方法。使得可以在list的中间插入和移除元素。
有两种类型的List :基本的ArrayList(非同步),擅长随机访问元素,但是在List 中插入,移除元素较慢。LInkedList,它是通过代价较低的List中间进行插入和删除操作,提供了优化的顺序访问。LinkedList在随机访问方面相对比较慢,但它的特性集较ArrayList更大。 LinkedList:(非同步)在拥有和List相同的特性外,还添加了可以使用其作为 栈,队列或双端队列的方法。 基于LinekedList 的数据结构是链表,因此也可以用来实现Stack,Queue。
Stack:(线程安全)实现了 LIFO 堆栈操作的更完整和更一致。stack是继承自Vector。
Vector:(线程安全)的可增长的对象数组。
Set : 是不允许重复元素。Set 中最常用的就是测试归属 性。可以很容易的询问某个元素是否存在某个Set中。所以查找就变成了Set中最重要的操作。因此你可以选择HashSet的实
现。它是通过散列函数,对快速查找做了优化。此外 Set接口和Collection接口是完全一样的方法。没有任何额外的功能,实际上Set就是Collection只是行为不同。
也有两种类型的Set:没有顺序的HashSet(非同步) ,也是上面提到的通过散列函数自己维护期内部的序列,所以让用户看起来是无序的。此外,HashSet的实现其实是一个HashMap的keyset。因此它允许有一个空的值,且不能重复。另外一种就是TreeSet(非同步)是将元素存储在红黑树数据结构中,如果你需要对Set排序就可以选择treeSet,treeSet对元素用自然顺序排序,或者根据创建set 时提供的 Comparator 进行排序,具体取决于使用的构造方法。LInkedHashSet:(非同步)保持了元素的插入顺序的Set,通过散列优化了访问速度。
Map: 已经实现的有类有:HashMap :非同步的。影响其性能 :初始容量 和加载因子。容量 是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。加载因子 是哈希表在其容量
自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
hashTable:同步的。 他的实例有两个参数影响其性能:初始容量 和加载因子。容量 是哈希表中桶 的数量,初始容量 就是哈希表创建时的容量。注意,哈希表的状态为 open:在发生“哈希冲突”的情况下,单个桶会存储多个条目,这些条目必须按顺序搜索。加载因子 是对哈希表在其容量自动增加之前可以达到多满的一个尺度。初始容量和加载因子这两个参数只是对该实现的提示。关于何时以及是否调用 rehash 方法的具体细节则依赖于该实现。
另外TreeMap:非同步的。排序的Map实现。
LInkedHashMap:(非同步)保持了元素的插入顺序,也是通过散列函数提供了快速的访问能力。
Queue:除了基本的 Collection 操作外,队列还提供其他的插入、提取和检查操作。每个方法都存在两种形式:一种抛出异常(操作失败时),另一种返回一个特殊值(null 或 false,具体取决于操作)。插入操作的后一种形式是用于专门为有容量限制的 Queue 实现设计的;在大多数实现中,插入操作不会失败。
PriorityQueue :非同步的优先级堆的无界优先级队列。优先级队列的元素按照其自然顺序进行排序,或者根据构造队列时提供的 Comparator 进行排序,具体取决于所使用的构造方法。优先级队列不允许使用 null 元素。依靠自然顺序的优先级队列还不允许插入不可比较的对象(这样做可能导致 ClassCastException)。另外一个实现了Queue接口的就是LinkedList .
上面基本上是常用到的集合类。以及各自的特点。具体的方法,功能,已经实现有兴趣的可以 看一下源代码,你会发现很多有趣的东西。 此外,在java容器里面还有两个接口是一定要
提的:Iterator 和 Comparable。
Iterator :对 collection 进行迭代的迭代器。该接口就三个方法:boolean hasNext(),E next() ,void remove()。
Comparable:此接口强行对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序,类的 compareTo 方法被称为它的自然比较方法。而且这个接口就只有唯一一个方法。
最后是对java 持有对象的一个小结:
1,数组将数字与对象关联起来,它保存明确类型的对象,查询时不需要对结果做转换,也可以是多维的,可以保存基本数据类型。但是数组一旦生成,其容量不能改变。
2,Collection保存单一元素,而map 保存关联的键值对。有了java泛型,也可以指定容器中的存放对象类型,获取的时候就不必转换。容器类可以在你向其中添加更多的数据的时候自动调整其尺寸。容器不能持有基本数据类型,但是自动包装机制会自动的对到容器中的基本类型自动拆装箱。
3,如果要进行大量的随机访问,就是用ArrayList ,如果要经常进行插入删除操作,则应该使用:LinkedList。
4, 除了TreeSet以外的Set都拥有和Collection完全一样的接口。List,Collection存在明显的不同,尽管List 要求的方法都在Collection中。Queue中的方法都是独立的。Map 和Collection接口是重叠的,Map可以使用entrySet方法,values()产生Collection.