哈夫曼压缩
一、压缩
思路:一个文件中,都会出现重复的字节,有些字节出现的次数多,有些字节出现的次数少,这样我们就可以根据出现次数的多少,构造哈夫曼树,并进行编码,出现次数越多的编码长度越短,出现次数越少的编码长度越长。而我们有知道一个英文字母占用一个byte,一个中文占用两个byte。我们将文件中的字节化为对应的编码后,形成01串,每次取八个01串写入压缩后的文件。因为编码的长度大多情况下都比文件中数据占用bit数更少,所以就文件就压缩了。
具体步骤:
①、统计文件中字节出现的次数
②、根据次数构建哈弗曼树
③、获取每个结点的哈弗曼编码
④将字节用01字符数组表示
/**
* 压缩编码表元素
* @author hpw
*
*/
public class CodeTableNode {
private byte bt;
private Byte[] code;
/**
* 构造器,传入一个byte和代表这个byte的int数组code,code每个元素代表一个二进制位
* 只有0,1
* @param bt 传入的byte
* @param code2 对应byte的二进制编码
*/
public CodeTableNode(byte bt,Byte[] code2){
this.bt=bt;
this.code=code2;
}
public byte getByte() {
return bt;
}
public Byte[] getCode() {
return code;
}
}
/**
* 建立数组的方法(TreeNodeArray:类似优先队列的方法)
*
* @return 根据byte出现次数进行排序的数组
* @throws IOException
*/
private TreeNodeArray getList() throws IOException {
TreeNodeArray tList = new TreeNodeArray();
// 创建输入输出流
java.io.InputStream inputStr = new java.io.FileInputStream(file);
java.io.BufferedInputStream bus=new java.io.BufferedInputStream(inputStr,2048);
int bt=bus.read();
while(bt!=-1){
byte by=(byte)bt;
TreeNode node = new TreeNode(by);
tList.add(node);
bt=bus.read();
}
inputStr.close();// 关闭输入流
bus.close();
return tList;
}
/**
* 通过节点队列创建二叉树,取出前2个节点组成二叉树,将根节点排序插入到队列中,
* 如此循环,最后剩下的就是根节点
*
* @return 二叉树头节点
* @throws Exception
*/
public TreeNode getTree() throws Exception {
TreeNodeArray list = getList();
while (list.size() > 1) {
TreeNode LNode = list.remove(0);
TreeNode RNode = list.remove(0);
TreeNode NNode = new TreeNode(LNode, RNode);
list.insert(NNode);
}
TreeNode rootNode = list.get(0);
return rootNode;
}
/**
* 生成编码表方法
* @return CodeMap格式的编码表
* @throws Exception
*/
public CodeTable getMap() throws Exception{
TreeNode rootNode=this.getTree();
//遍历树
TreeStack<Byte> rootStack=new TreeStack<Byte>();//堆栈记录路径
CodeTable codes=new CodeTable();
scanTree(rootNode,rootStack,codes);
return codes;
}
/**
* 遍历树的方法,递归
* @param root 节点
* @param rootStk 堆栈记录,存储路径
* @param map 编码表
*/
private void scanTree(TreeNode root,TreeStack<Byte> rootStk,CodeTable map){
if(root.getType()==1){
//根节点
TreeNode LNode=root.getLNode();
rootStk.add((byte)0);
//递归遍历左节点
scanTree(LNode,rootStk,map);
TreeNode RNode=root.getRNode();
rootStk.add((byte)1);
//递归遍历右节点
scanTree(RNode,rootStk,map);
}
if(root.getType()==2){
//叶节点
Object[] cd=rootStk.getCode();
Byte[] code=new Byte[cd.length];
int ind=0;
for(Object o:cd){
byte ob=(Byte)o;
code[ind]=ob;
ind++;
}
byte bt=root.getB();
CodeTableNode nd=new CodeTableNode(bt,code);
map.add(nd);
}
rootStk.pop();//栈回溯
}
⑤、每个取一个长度为八的字节数组,写入文件,若最后剩下的数组不足八位,则添加码表中没有的元素知道够8位。并写入码表
/**
* 获取文件重新编码,并直接写入文件
*
* @param file
* 文件对象
* @param map
* 编码表
* @throws Exception
*/
private void getFileCode(File file, OutputStream op, CodeTable map)
throws Exception {
java.io.InputStream in = new java.io.FileInputStream(file);
Byte[] nBt = new Byte[8];// 储存字节的每位,8位
int emptyN = 8;// 剩余的空位,候补
int btn = in.read();
while (btn != -1) {
byte bn = (byte) btn;
Byte[] code = map.get(bn);// 获取b对应的编码
for (int t = 0; t < code.length; t++) {// 插入值到bit位数组中
nBt[8 - emptyN] = code[t];
emptyN--;
// 写满一个字节后加入队列
if (emptyN == 0) {
byte nByte = toByte(nBt);
// 写入文件
System.out.println("写入byte:"+nByte);
byte[] bt = { nByte };
op.write(bt);
emptyN = 8;// 空位重置
nBt = new Byte[8];// 数组重置
}
}
btn = in.read();
}
in.close();
// 写完后检测是否写满最后一个字节,如未满则填充一个map中不存在的值
if (emptyN > 0) {
Byte[] addCode = new Byte[emptyN];
// 检测到可行的结尾填充
if (scanUsableAddons(map, addCode, 0)) {
for (byte bi : addCode) {
nBt[8 - emptyN] = bi;
emptyN--;
}
byte endB = toByte(nBt);
// 添加到重新编码区结尾
byte[] bt = { endB };
op.write(bt);
}
}
}
/**
* 将CodeMap编码表对象转换成byte数组 规则:
* 每条编码为3部分,第一部分占1个byte,储存编码的, 第二部分占一个byte,存储原byte值
* 第三部分为一个byte[]数组,储存对应的编码,每个二进制位占一个byte,只为0或1
*
* @param map
* 传入一个CodeMap对象
* @return 转换完成的byte数组
*/
private byte[] getMapByte(CodeTable map) {
List<Byte> allBy = new ArrayList<Byte>();
for (CodeTableNode mNode : map.getAllNodes()) {
// 取得map中MapNode对象
byte bt = mNode.getByte();// 取得byte值
Byte[] co = mNode.getCode();// 取得编码
Byte len = (byte) co.length;// 取得编码长度
allBy.add(len);
allBy.add(bt);
for (byte b : co) {// 取得编码中每个二进制位值传入队列
allBy.add(b);
}
}
// 转换队列为byte[]数组
byte[] abts = new byte[allBy.size()];
int index = 0;
for (byte b : allBy) {
abts[index] = b;
index++;
}
return abts;
}
private void compress() {
String src = srcField.getText();
String tar = tarField.getText();
File srcFile = new File(src);
File tarFile = new File(tar);
lab.setText("开始压缩 O(∩_∩)O");
//lab.setText("正在压缩。。。 →_→");
ReadFile sf = new ReadFile(srcFile);
CodeTable map = null;// 获取编码表
try {
//得到码表
map = sf.getMap();
byte[] maptoByte = getMapByte(map);
tarFile.createNewFile();// 创建文件
// 建立输出流
java.io.OutputStream out = new java.io.FileOutputStream(tarFile);
// 建立对象输出流
int mapLen = maptoByte.length;
java.io.DataOutputStream dou = new java.io.DataOutputStream(out);
dou.writeInt(mapLen);
dou.flush();
// 输出编码表
out.write(maptoByte);
// 写入转码后的文件数据
// lab.setText("正在压缩。。。 →_→");
getFileCode(srcFile, out, map);// 直接队文件转码并写入
out.flush();
out.close();
//lab.setText("压缩成功! (^o^)");
} catch (Exception e1) {
e1.printStackTrace();
}
}
二、解压
思路:从压缩的文件中读取字节+码表,将每个字节转化为一个八位的字符数组,逐一对比码表,若有相同的则根据码表转化为相应的字节,若没有一致的,则继续读取字节化为八位的字数数组,如此循环,知道读取完文件。然后将获取的字节写入文件,这样解压就算完成了。其实解压是压缩的逆过程,关键就是写入码表与获取码表,这是压缩与解压万和城呢过的关键。
/**
* 解压方法,先获取编码表,再对文件进行解码
*
* @throws Exception
*/
private void inCompress() throws Exception {
File srcF = new File(srcField.getText());
File tarF = new File(tarField.getText());
// lab.setText("开始解压 O(∩_∩)O");
lab.setText("正在解压。。。 →_→");
tarF.createNewFile();
java.io.InputStream inStr = new java.io.FileInputStream(srcF);
java.io.DataInputStream daIns = new java.io.DataInputStream(inStr);
java.io.OutputStream ouStr = new java.io.FileOutputStream(tarF);
// 取得编码表的长度
int byteCount = daIns.readInt();
int readByte = inStr.read();
byteCount--;
CodeTable getMap = new CodeTable();// 编码表对象,备用
while (byteCount > 0) {
int readCount = readByte;// 读取时的计数变量,以确定当前读取的数据类型
// 获取本条编码的长度为readCount
Byte[] byteCode = new Byte[readCount];
readByte = inStr.read();
byteCount--;// 读取了一个字节,计数器减一
if (readByte == -1) {// 异常文件结尾,抛出
throw new Exception("Unexcepted End");
}
byte bt = (byte) readByte;// 当前编码对应的字节
for (int i = 0; i < readCount; i++) {
readByte = inStr.read();
byteCount--;// 读取了一个字节,计数器减一
if (readByte == -1) {// 异常文件结尾,抛出
throw new Exception("Unexcepted End");
}
byte tb = (byte) readByte;
byteCode[i] = tb;
}
// 一条编码读取完毕,建立一个编码表节点对象并导入了
CodeTableNode getNode = new CodeTableNode(bt, byteCode);
getMap.add(getNode);
readByte = inStr.read();
byteCount--;// 读取下一个数据
}
// lab.setText("正在解压。。。 →_→");
// 编码表建立完毕,开始读取文件正文并转码
// 转码方法:每次读取一位,在编码表中检索,如果存在则转码,不存在则增加一位并重新检测
List<Byte> bs = new java.util.ArrayList<Byte>();// 存储编码的byte队列
while (readByte != -1) {
byte b = (byte) readByte;
byte[] bArray = toByteArray(b);// 将字节每位提出转成数组
for (byte bn : bArray) {
bs.add(bn);
byte[] nNode = checkMapCode(getMap, bs);
if (nNode != null) {
ouStr.write(nNode);
ouStr.flush();
bs.clear();// 清空队列
}
if (bs.size() > getMap.getAllNodes().size()) {
// 队列长度已经大于Map中的编码条数
throw new Exception("Erro File,Not Found Code");
}
}
readByte = inStr.read();// 继续读取
}
// lab.setText("解压成功! (^o^)");
// 关闭输入输出流
inStr.close();
ouStr.close();
}
/**
* 递归检索编码表map中无对应值的结尾二进制位作为结尾
*
* @param map
* 编码表
* @param bits
* 剩余的二进制位
* @param index
* 目前的指向
* @return 找到了则返回true,检索完毕都未找到则返回false
*/
private boolean scanUsableAddons(CodeTable map, Byte[] bits, int index) {
if (index != bits.length - 1) {
bits[index] = 0;
if (scanUsableAddons(map, bits, index + 1)) {
return true;
}
bits[index] = 1;
if (scanUsableAddons(map, bits, index + 1)) {
return true;
}
}
if (index == bits.length - 1) {
bits[index] = 0;
if (map.get(bits) == null) {
return true;
}
bits[index] = 1;
if (map.get(bits) == null) {
return true;
}
}
return false;
}
三、感想
做完哈夫曼压缩后,感想最大的就是速度,速度太慢,就像蜗牛爬一样慢,相对于自己用地360压缩是简直没得比,压缩个7M多点的要16分钟,解压更是成倍增长。还有就是对于一些doc格式、ppt格式的等,压缩比也不大高,可能是文件大小的原因。
界面图:
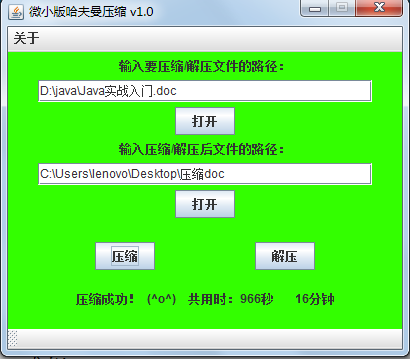
源文件、压缩后、解压后的对比图:
