Drools 规则引擎-学习笔记(一)
Knowledge representation :人工智能领域的有关知识是如何表达与操作的。
Expert System : 专家系统也被称作 Knowledge-based System, 然而早期的专家系统是把逻辑硬编码的。
Drools是一个Rule Engine, 它使用rule-based的方法实现专家系统, 可以更正确的归类为Production Rule System-产生式规则系统.
Production Rule System 是一种Rule Engine, 也是一种Expert System.
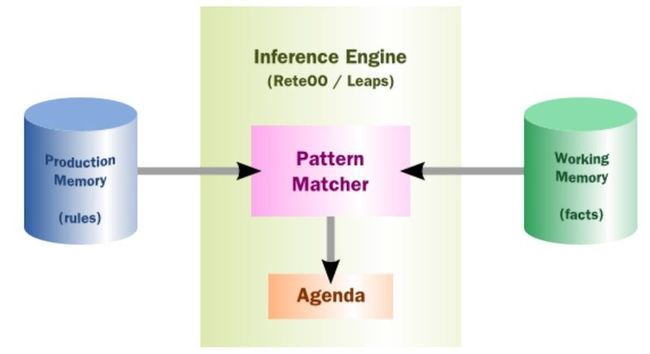
一个Production Rule System是Turing complete(图灵完全)的。The brain of a Production Rule System 是一个推理引擎(Inference Engine)。 推理引擎是用来匹配facts and data与Production Rules的, 这个过程可以叫做模式匹配(Pattern Matching). 用于推理引擎的模式匹配算法包括: Linear, Rete, Treat, Leaps.
Drools 实现并继承了Rete算法,Leaps过去也实现过但现在已经retired了,由于其变的unmaintained了。Drools的Rete实现称作ReteOO, 表示: the Rete algorithm for object oriented systems.
Rules 存储在Production Memory中,而对应的facts存储在Working Memory中。由于系统中可能包含很多规则与事实, 可能匹配的时候出现多个规则匹配成功,这样会出现执行冲突(Be in conflict). 这里就出现了Agenda 了, 这个用来保证冲突规则的执行顺序的, 当然要通过一些冲突解决策略(Conflict Resolution strategy)。
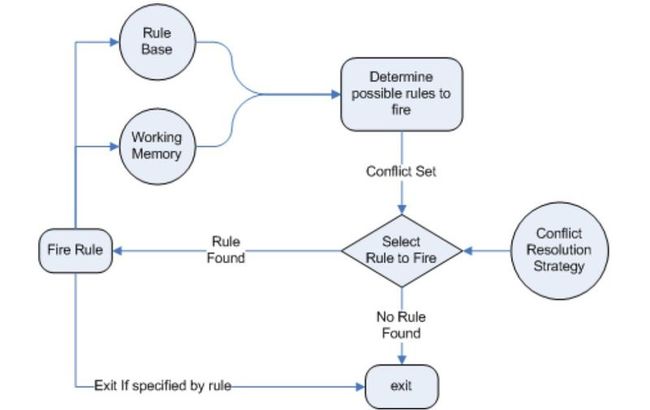
对于一个Rule System来说, 有两种执行方法:Forward Chaining 和 Backward Chaining。同时运用两种方法的可以称作混合规则系统(Hybrid Rule Systems).
Forward chaining 是“data-driven”的,简单地讲,就是以fact开始的,事实传播然后以一个conclusion结束。Drools就是一个forward chaining engine.
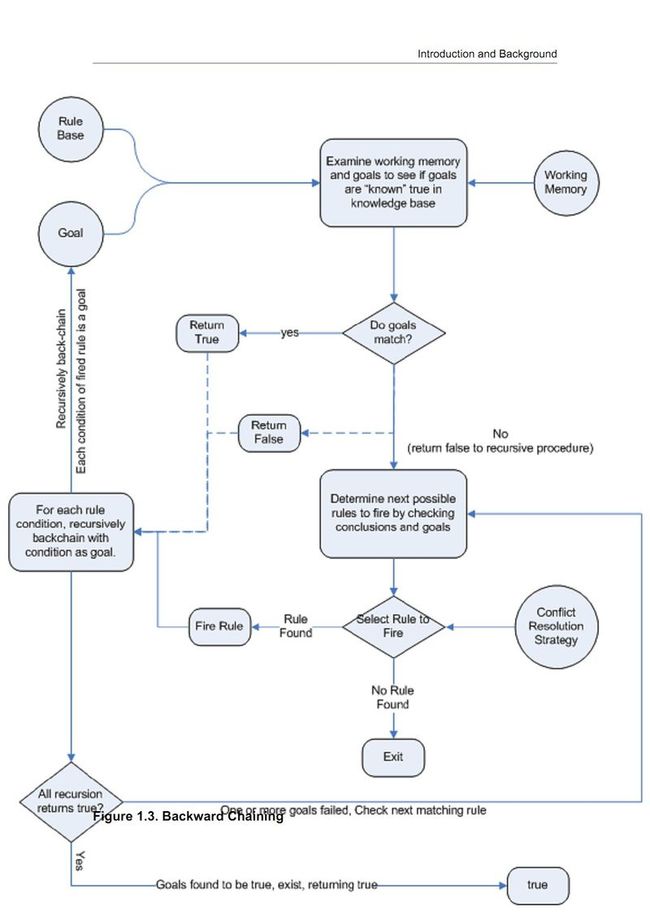
Backward Chaining是一个“goal-driven”的,简单地讲,就是一个以conclusion开始的, 然后引擎去尝试去satisfy这个结论。如果不能满足的话, 就又去查询其他能被satisfy的conclusions.Drools计划在未来的版本中提供对Backward Chaining的支持。
规则引擎的Advantages:
Declarative Programming: tell the Rule engines What to do , not How todo.
Logic and Data Separation(逻辑与数据分离):data is in your domain objects, and the logic is in the rules. 这个从根本上break了数据与逻辑的面向对象耦合。
Drools的规则引擎使用步骤:
用KnowledgeBuilder的实例去编译规则.drl文件;
然后获得一个KnowledgeBase 实例,把上步骤中builder实例获取的KnowledgePackage添加到 KnowledgeBase实例中;
建立一个Knowledge session,接着insert facts, 再fireAllRules.