流处理的特征与对比
——读The 8 Requirements of Real-Time Stream Processing笔记
这篇文章介绍了8条实时流处理所需要的要求与特征,然后对比了传统DBMS(或者是内存DBMS),Rule engine与SPE在处理流数据方面所能达到的上面8条特征中的几条。

1. Eight Rules for stream processing
Rule 1: Keep the data moving
The first requirement for a real-time stream processing system is to process messages “in-stream”, without any requirement to store them to perform any operation or sequence of operations. Ideally the system should also use an active (i.e., non-polling) processing model.
Rule 2: Query using SQL on Streams(StreamSQL)
The second requirement is to support a high-level “StreamSQL” language with built-in extensible stream-oriented primitives and operators.
Rule 3: Handle stream imperfections(delayed, missing, and out-of-order data)
The third requirement is to have built-in mechanisms to provide resiliency against stream “imperfections”, including missing and out-of-order data, which are commonly present in real-world data streams.
Rule 4: Generate Predictable Outcomes
The fourth requirement is that a stream processing engine must guarantee predictable and repeatable outcomes.
Rule 5: Integrate Stored and Streaming Data
The fifth requirement is to have the capability to efficiently store, access, and modify state information, and combine it with live streaming data. For seamless integration, the system should use a uniform language when dealing with either type of data.
Rule 6: Guarantee Data Safety and Availability
The sixth requirement is to ensure that the applications are up and available, and the integrity of the data maintained at all times, despite failures.
Rule 7: Partition and Scale Applications Automatically
The seventh requirement is to have the capability to distribute processing across multiple processors and machines to achieve incremental scalability. Ideally, the distribution should be automatic and transparent.
Rule 8: Process and Respond Instantaneously
The eighth requirement is that a stream processing system must have a highly-optimized, minimal-overhead execution engine to deliver real-time response for high-volume applications.
2. DBMS, Rule Engine, SPE对比
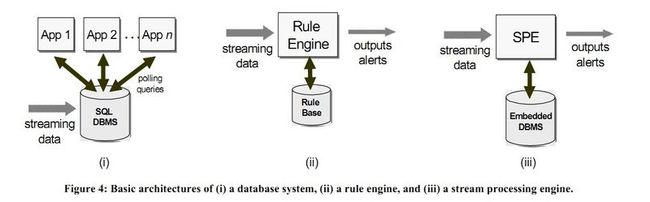
DBMS在处理数据上是先存储后处理的,即“process-after-store” model. 所以在处理实时数据流方面天生就不是适合,尽管可以利用内存数据库来缓和效率方面的弱势, 同时其也具备trigger的特性, 但所有这些都不显得不够可扩展。
Rule Engine 虽然某种程度上能够处理实时的数据流, 但其在Rule Language方面有欠缺, 不能够拥有类似SQL的表达能力。对数据流的处理操作有限。
只有SPE是专门为处理实时流数据定做的。有许多天生的特性,专门用来处理和操作流数据。
下面就是它们的一个对比:
|
|
DBMS |
Rule engine |
SPE |
| Keep the data moving |
No |
Yes |
Yes |
| SQL on streams |
No |
No |
Yes |
| Handle stream imperfections |
Difficult |
Possible |
Possible |
| Predictable outcome |
Difficult |
Possible |
Possible |
| High availability |
Possible |
Possible |
Possible |
| Stored and streamed data |
No |
No |
Yes |
| Distribution and scalability |
Possible |
Possible |
Possible |
| Instantaneous response |
Possible |
Possible |
Possible |