Lucene4.3开发之第五步之融丹筑基(五)
排序是对于全文检索来言是一个必不可少的功能,在实际运行中,排序功能在某些时候给我们带来了很大的方便,比如在淘宝、京东等一些电商网站我们可能通过排序来快速找到价格最便宜的商品,或者通过排序来找到评价数最高或卖的最好的商品,再比如在iteye里的博客栏里,每天都会以降序的方式,来显示出最新发布的几篇博客,有了排序,我们就能在某些时候很方便快速的得到某些有效信息,所以说排序功能,无处不在。
本篇,就来看下我们在lucene中怎么使用其丰富的排序功能。
在此之前,我们先来熟悉下lucene中排序的基本知识,在默认情况下,lucene使用是以关联性降序的方式作为默认的排序方式,这样可以使得我们搜索的结果通常是最优的,因为它会尽可能使得首先出现的几个结果是与我们搜索的内容最相关的,而不不需要我们翻页寻找我们最想要的内容,这一点是与数据库相比,是全文检索一个很大的有点。当然,在实际开发中我们也需要根据业务的实际情况来个我们的客户提供多种不同的排序方式。我们先来看下载lucene中比较特殊的两种基本的排序方式。

我们再来看几个检索是需要用的方法
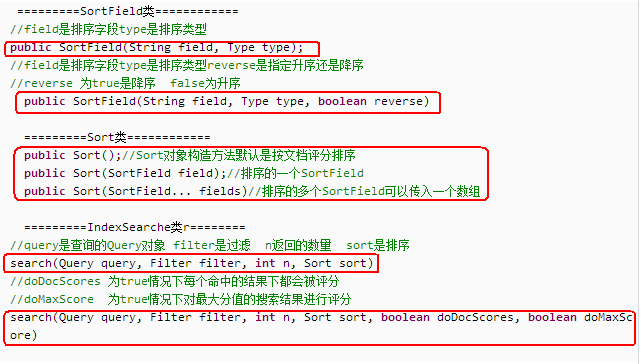
=========SortField类============ //field是排序字段type是排序类型 public SortField(String field, Type type); //field是排序字段type是排序类型reverse是指定升序还是降序 //reverse 为true是降序 false为升序 public SortField(String field, Type type, boolean reverse) =========Sort类============ public Sort();//Sort对象构造方法默认是按文档评分排序 public Sort(SortField field);//排序的一个SortField public Sort(SortField... fields)//排序的多个SortField可以传入一个数组 =========IndexSearche类r======== //query是查询的Query对象 filter是过滤 n返回的数量 sort是排序 search(Query query, Filter filter, int n, Sort sort) //doDocScores 为true情况下每个命中的结果下都会被评分 //doMaxScore 为true情况下对最大分值的搜索结果进行评分 search(Query query, Filter filter, int n, Sort sort, boolean doDocScores, boolean doMaxScore)
1、在还没有进行一点排序前我们先来看下索引里的内容,核心代码如下:
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),10000);

2、使用默认的关联性评分后,核心代码和运行效果图如下:
Sort sort=new Sort();//默认使用关联性评分 TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),10000,sort);
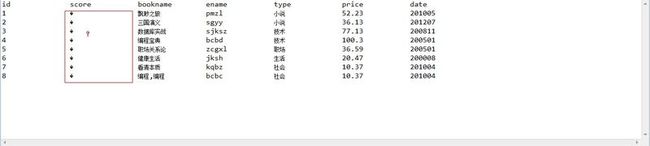
关于上图中乱码字符原因是因为默认排序情况下lucene是不会对搜索结果进行评分操作的,因为评分操作会降低性能,所以关于score的那一列返回的是NAN的字符串,处于格式的需要,散仙在使用DecimalFormat类给出其评分结果保留2为小数是,因为是一个特殊字符,所以就出现了上图情况。(转者注:原博主在上面代码中没有给出评分细则的代码)
3、按照日期降序排序,核心代码和运行效果图如下:
Sort sort=new Sort(new SortField("date", Type.INT,true));//true为降序排列
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),10000,sort);

4、按照价格升序排序,核心代码和运行结果效果图如下:
Sort sort=new Sort(new SortField("price", Type.DOUBLE,false));//false为升序排列
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),10000,sort);

5、多字段排序,按照日期降序的情况下,因为id为7和8的日期相同,所以我们就新增一个排序字段按ename升序排序,核心代码和运行结果如下:
// Sort sort=new Sort(new SortField("date", Type.INT, true),new SortField("ename", Type.STRING, false));
//这两段代码效果一样
Sort sort=new Sort(new SortField[]{new SortField("date", Type.INT, true),new SortField("ename", Type.STRING, false)});
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),10000,sort);

6、带评分的排序,注意后面两个布尔类型的变量可以控制是否评分,特别是在没有要求需要打分时,建议别开启,大数量时对性能影响较大,检索"编程"得到的结果,默认按评分降序排序,核心代码和运行结果如下:
=========IndexSearche类r======== //query是查询的Query对象 filter是过滤 n返回的数量 sort是排序 search(Query query, Filter filter, int n, Sort sort) //doDocScores 为true情况下每个命中的结果下都会被评分 //doMaxScore 为true情况下对最大分值的搜索结果进行评分 search(Query query, Filter filter, int n, Sort sort, boolean doDocScores, boolean doMaxScore)
Sort sort=Sort.RELEVANCE;
TopDocs topDocs=searcher.search(new TermQuery(new Term("bookname", "编程")),null,100,sort,true,true);

上面的编程,编程因为在切分时编程的tf出现了2次,所以在查询时有较高的得分,所以排在首位。
7、注意几点
(1)排序对一个文档里什么域都没有存储,使用字符串排序会排在首位;
(2)排序对一个文档里什么域都没有存储,使用数字类型排序会默认给其赋值为0进行排序;
(3)我们可以对数字类型的null值的文档进行代码控制,可以将其设置为最大,所以将会排在最后面,代码如下:
SortField sortField = new SortField("value", SortField.Type.INT);
sortField.setMissingValue(Integer.MAX_VALUE);