在Java中高效操作大型字符串
Java™ 语言默认的String和StringBuilder类很难支撑起操纵大量字符串的系统。rope 数据结构可能是更好的替代品。这篇文章介绍 Ropes for Java,这是针对 Java 平台的 rope 实现;本文还将研究性能问题,并提供一些有效使用 rope 库的指导。
rope 数据结构 表示不能修改的字符序列,与 Java 的 String 非常像。但是 ropes 效率奇高的字符串变换操作使得它与 String 及其同一体系的可修改的 StringBuffer 和 StringBuilder 大不相同,非常适合那些执行繁重字符串操纵的应用程序,尤其在多线程环境下更是如此。
简要概括过 rope 数据结构之后,本文将介绍 rope 在 Java 平台上的实现 —— Ropes for Java。然后将在 Java 平台上对 String、StringBuffer 和 Ropes for Java Rope 类进行测评;考察一些特殊的性能问题;并讨论什么时候应该以及什么时候不应该在应用程序中使用 rope。
一个 rope 代表一个不能修改的字符序列。rope 的长度 就是序列中字符的个数。多数字符串表示都将字符串连续地保存在内存中。rope 的关键特点就是它突破了这个限制,允许一个 rope 的各个片断离散地存放,并通过连接节点(concatenation node)连接它们。这种设计使得 rope 节点的连接操作比 Java String 的连接操作更快。String 版本的连接操作要求将需要连接的两个字符串复制到新位置,这是一种 O(n)操作。rope 版本的连接操作则只是创建一个新的连接节点,这是个 O(1)操作。(如果不熟悉 “大 O” 符号,请参阅 参考资料 获得相关说明的链接。)
图 1 演示了两种字符串的表示方法。在左侧的表示方法中,字符放在连续的内存位置内。Java 的字符串使用这种表示方式。在右侧的表示方式中,离散的字符串通过连接节点组合在一起。
Rope 实现通常也将延迟对大型子串操作的求值,它的作法是引入子串节点。使用子串节点能够将获取长度为 n 的子串的时间从 O(n)降低到 O(log n),通常会减到 O(1)。需要指出的是,Java 的 String 由于是不可修改的,所以子串操作的时间是恒定的,但 StringBuilder 并不是这样。
扁平 rope(flat rope) — 没有连接节点或子串节点 — 的深度(depth)为 1。有连接和子串的 rope 的深度比它们所拥有的最深节点的深度大 1。
Rope 有两项开销是使用连续字符的字符串表达方式所没有的。第一个开销就是必须遍历子串和连接节点的上层结构(superstructure)才能到达指定的字符。而且,这个树形上层结构必须尽可能保持均衡,以便将遍历的次数降到最少,这意味着 rope 需要偶而进行重新均衡的操作,以保持良好的读取性能。即使 rope 的均衡很好,获取指定位置的字符也是个 O(log n)操作,其中 n 是 rope 包含的连接和子串节点的个数。(为了方便,可以用 rope 的长度代替 n,因为长度总是比 rope 中的子串和连接节点的个数大。)
幸运的是,rope 的重新均衡操作非常迅速,至于应该何时进行重新均衡的决策也能够自动制定,例如通过比较 rope 的长度和深度来决定。而且,在多数数据处理例程中,都需要对 rope 字符进行顺序访问,在这种情况下,rope 的迭代器能够提供分摊的 O(1) 访问速度。
表 1 比较了一些常见的字符串操作在 rope 和 Java String 上预计的运行时间。
| 连接 | O(1) | O(n) |
| 子串 | O(1) | O(1) |
| 检索字符 | O(log n) | O(1) |
| 顺序检索所有字符(每个字符的开销) | O(1) | O(1) |
|
Ropes for Java 是 rope 数据结构在 java 平台上的高质量实现(请参阅 参考资料)。它进行了广泛的优化,有助于提供全面的优秀性能和内存使用。这一节将解释如何将 rope 集成进 Java 应用程序,并比较 rope 与 String 和 StringBuffer 的性能。
Ropes for Java 实现只向客户机公开了一个类:Rope。Rope 实例可以用 Rope.BUILDER 工厂构建器从任意 CharSequence 上创建。
清单 1 显示了如何创建 rope。
Rope r = Rope.BUILDER.build("Hello World");
|
Rope 公开了一组操作方法,包括执行以下操作的方法:
- 附加另一个字符序列
- 删除子序列
- 将另一个字符序列插入 rope
请记住,同 String 一样,上面的每种变换都返回一个新 rope;原来的 rope 保持不变。清单 2 演示了其中一些操作。
Rope r = Rope.BUILDER.build("Hello World");
r = r.append("!"); // r is now "Hello World!"
r = r.delete(0,6); // r is now "World!"
|
rope 上的迭代需要稍加注意。在查看了清单 3 的两个代码块之后,可以看出哪块代码执行得更好。
//Technique 1
final Rope r=some initialization code;
for (int j=0; j<r.length(); ++j)
result+=r.charAt(j);
//Technique 2
final Rope r=some initialization code;
for (final char c: r)
result+=c;
|
返回 rope 内任意位置字符的操作是个 O(log n)操作。但是,由于每个字符上都使用 charAt,清单 3 中第一个代码块花了 n 倍的 O(log n)查询时间。第二个代码块使用的是 Iterator,应该比第一块执行得快一些。表 2 归纳了使用这两种方法在长度为 10,690,488 的 rope 上迭代的性能。为了比较,表 2 还包含了 String 和 StringBuffer 的时间。
String |
69,809,420 |
StringBuffer |
251,652,393 |
Rope.charAt |
79,441,772,895 |
Rope.iterator |
1,910,836,551 |
用来得到表 2 中符合预期的结果的 rope,是通过对初始字符串执行一系列复杂的变换之后创建的。但是,如果直接从字符序列创建这个 rope 而不进行变换,那么性能数字会产生较大的变化。表 3 比较了两种方法的性能。这次是在一个包含 182,029 个字符的 rope 上迭代,这次的 rope 是直接用包含 Project Gutenberg 版查理斯·狄更斯圣诞欢歌 的字符数组初始化的。
String |
602,162 |
StringBuffer |
2,259,917 |
Rope.charAt |
462,904 |
Rope.iterator |
3,466,047 |
如何用我前面的理论讨论解释这一性能逆转呢?rope 的构建是个关键因素:当直接使用底层的 CharacterSequence 或字符数组构建 rope 时,它只有一个简单的结构,里面包含一个扁平 rope。因为这个 rope 不包含连接或子串节点,所以字符查询操作要么直接委托给底层序列的 charAt 方法(在 CharacterSequence 的情况下),要么包含进行数组查询(在数组的情况下)。扁平 rope 的 Rope.charAt 性能与底层表示的 chatAt 性能匹配,通常是 O(1);所以性能是不同的。
聪明的读者可能想知道既然大家都提供 0(1)的访问时间,为什么 charAt 会比迭代器快 7 倍。这个区别是因为在 Java 语言中,Iterator 必须返回 Object。而 charAt 实现直接返回 char 原语,迭代器实现必须将每个 char 装箱为一个 Character 对象。自动装箱可能消除了原语装箱在语法上的麻烦,但是不能消除性能上的损失。
最后,非常明显的是:Rope.charAt 的性能比 String.charAt 的性能好。原因是 Rope 使用专门的类来表示延迟子串(lazy substring),因此使普通 rope 的 charAt 的实现保持简单。对比之下,Java SE 的 String 实现使用同一个类表示常规字符串和延迟子串,因此多多少少将 charAt 的逻辑弄得复杂起来,所以在迭代常规字符串期间增加了少量性能开支。
在讨论 rope 上的正则表达式搜索性能的优化时,还会提到 Rope 迭代。
在某种程度上,多数 rope 实例都必须写入到某些位置,通常写到一个流内。不幸的是,将对象写入流就要调用对象的 toString 方法。这种序列化方式强行在写入一个字符之前在内存中建立整个对象的字符串表示,对于大型对象来说,这是个非常大的性能拖累。Ropes for Java 设计的时候就考虑了大型的字符串对象,所以它提供了更好的方式。
为了提高性能,Rope 引入了一个 write 方法,接受一个 Writer 和一个范围说明,然后将 rope 的指定范围的字符写到 。这样就节省了用 rope 构建 String 的时间和内存开支,对于大型 rope 来说,这种开支是相当巨大的。清单 4 显示了 rope 输出的标准方式和增强方式。
out.write(rope); rope.write(out); |
表 4 包含的测评结果是将一个长度为 10,690,488、深度为 65 的 rope 写入一个由内存缓冲区支持的流的结果。请注意,只显示了节省的时间,但是在临时分配的堆空间上的节省也非常巨大。
out.write |
75,136,884 |
rope.write |
13,591,023 |
Rope 的变换从理论上要比使用连续字符的字符串表示方式快得多。但反过来,正如所看到的,rope 的迭代变慢了。在这一节,将看到 Ropes for Java 和 String、StringBuffer 进行变换操作的性能测评比较。
全部测试都用 Project Gutenberg 版本的电子书圣诞欢歌 初始化(182,029 个字节),并对其连续应用一系列变换。在多数情况下,变换的数量在 20 到 480 的范围内变动,以便演示数据结构缩放的效果。(图 2、3、4 将变换的数量称为计划长度(plan length)。)每个测试执行了七次,并使用中间结果。
在插入测评中,从前一次迭代的输出中随机选择一个子串,然后插入到字符串的随机位置。图 2 显示了测评的结果。

对 String 和 StringBuffer 来说,完成测评所需要的时间随着计划长度的增加呈指数级增长。相比之下,Rope 则执行得极好。
这个测评的方法是,从输入字符串中选取随机范围的字符附加到它本身。这个测试的有趣之处在于:StringBuffer 正是为了执行快速附加而优化的。图 3 显示了这个测评的结果。
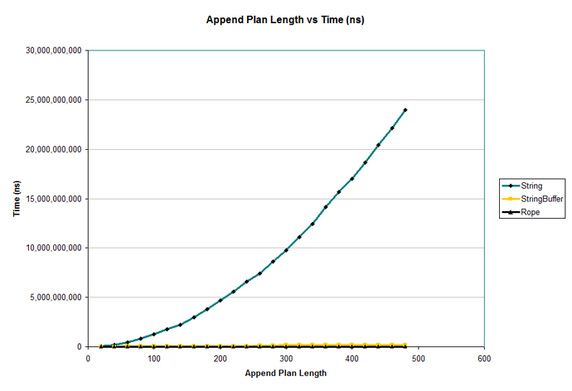
不幸的是,图 3 的视图显示 String 的性能非常糟糕。但是,如预期所料,StringBuffer 的性能非常好。
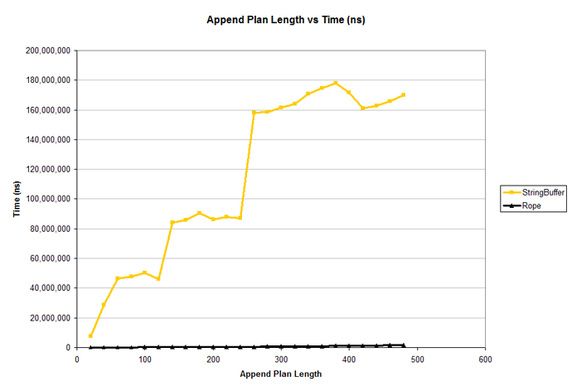
图 4 从比较中撤出 String 的结果,调整了图表的比例,更清楚地显示了 Rope 和 StringBuffer 性能的对比。
|
图 4 显示了图 3 中不太明显的 Rope 和 StringBuffer 之间的巨大区别。Rope 很少能突破 x 轴。但是真正有趣的是 StringBuffer 的图 — 骤然上升后保持稳定上升,而不是平滑地上升。(作为练习,在阅读下一段之前请试着解释一下原因。)
原因与 StringBuffer 的空间分配方式有关。它们在其内部数组的末尾分配额外的空间,以便有效地附加字符。但是在空间用尽之后,就必须分配全新的数组,并将所有数据复制到新数组。新数组一般根据当前长度调整大小。随着计划长度的增加,生成的 StringBuffer 的长度也会增加。随着逐渐到达重新设置大小的阈值,花费的时间也随着额外的重新设置大小和复制而骤升。然后下几个计划长度的性能稳定期(即缓慢提升的时间)也逐渐升高。因为每个计划项增加的字符串长度总数大体相同,所以随后的稳定期比例可以作为重新设置底层数组大小的参考指标。根据这些结果,可以准确地估算出这个 StringBuffer 实现大约在 1.5 左右。
迄今为止,已经用图表展示了 Rope、String 和 StringBuffer 之间的性能差异。表 5 提供了所有字符变换测评的计时结果,使用了 480 項计划长度。
| 插入 | |
String |
18,447,562,195 |
StringBuffer |
6,540,357,890 |
Rope |
31,571,989 |
| 在前部添加 | |
String |
22,730,410,698 |
StringBuffer |
6,251,045,63 |
Rope |
57,748,641 |
| 在后面添加 | |
String |
23,984,100,264 |
StringBuffer |
169,927,944 |
Rope |
1,532,799 |
| 删除(从初始文本中删除 230 个随机范围) | |
String |
162,563,010 |
StringBuffer |
10,422,938 |
Rope |
865,154 |
关于测评程序的链接请参阅 参考资料。我建议您在自己的平台上运行测评程序以检验本文给出的结果。
正则表达式在 JDK 1.4 版本中引入,是许多应用程序中广泛使用的一个功能。所以,正则表达式在 rope 中执行良好至关重要。在 Java 语言中,正则表达式用 Pattern 表示。要将 Pattern 与 CharSequence 的区域匹配,要使用模式实例构建 Matcher 对象,将 CharSequence 作为参数传递给 Matcher。
操纵 CharSequence 可为 Java 的正则表达式库提供极佳的灵活性,但也带来了一个严重的缺陷。CharSequence 只提供了一个方法来访问它的字符:charAt(x)。就像我在概述一节中提到过的,在拥有许多内部节点的 rope 上随机访问字符的时间大约为 O(log n),所以遍历时间为 O(n log n)。为了演示这个缺陷带来的问题,我测评了在长度为 10,690,488 的字符串中寻找模式 “Crachit*” 的所有实例所花费的时间。所用的 rope 是使用插入测评的同一个变换序列构建的,深度为 65。表 6 显示了测评的结果。
String |
75,286,078 |
StringBuffer |
86,083,830 |
Rope |
12,507,367,218 |
重新均衡后的 Rope |
2,628,889,679 |
显然,Rope 的匹配性能很差。(明确地讲,对有许多内部节点的 Rope 是这样。对于扁平 rope,性能几乎与底层字符表示的性能相同。)即使在显式地均衡过 Rope 之后,虽然匹配快了 3.5 倍,Rope 的性能还是没有达到与 String 或 StringBuffer 相同的水平。
为了改进这种情况,Matcher 应该而且能够利用 Rope 迭代器提供的更快的 O(1)访问时间。为了掌握这种方法,首先需要理解 Matcher 到其 CharSequence 的访问模式。
正则表达式匹配最常见的场景是从字符序列的某个点上开始,向前移动,直到找到所有匹配,并到达序列末尾为止。在这个场景中,匹配器主要是向前移动,一次通常移动不止一个字符。但在少数情况下,匹配器被迫向后移动。
很容易就能将 Rope 迭代器改成一次向前移动不止一个字符。但是向后移动要复杂些,因为迭代器内部执行的是深度优先算法,预先排好了 Rope 遍历的顺序,需要访问每个叶节点。遍历堆栈没有足够的信息能够前移到前一个叶节点,但是如果促使向后移动的信息量没有使迭代器离开当前叶节点,那么迭代器就有可能服务请求。为了说明这个作法,图 5 显示一个虚构的迭代器的状态,它能够向后移动一、二、三、四个位置,但不能移动更多位置,因为这要求访问前面访问的叶节点。

为了支持这一新功能,可以修改 Rope 的 charAt 方法,这样在第一次调用的时候,就在指定位置上构建一个迭代器。后续的调用会将迭代器前后移动指定的距离。如果迭代器不能后移指定的距离,那么就执行默认的 charAt 例程取得字符的值 — 这种情况很少发生。
因为这种优化无法做到普遍适用,而且要求引入新的成员变量,所以最好不要直接将它添加到 Rope 类。相反,可以根据需要用这个优化修饰 rope。为此,Ropes for Java 在 Rope 类中包含了一个方法,能够为指定的模式生成优化的匹配器。清单 5 演示了这种方法:
Pattern p = ... Matcher m = rope.matcher(p); |
清单 5 中第二行调用对 rope 进行修饰,优化正则表达式匹配。
表 7 提供了这种方法的测评结果,并包含了以前的结果(表 6)以便进行对照。
表 7. 使用 rope.matcher() 的正则表达式搜索时间
String |
75,286,078 |
StringBuffer |
86,083,830 |
Rope |
12,507,367,218 |
重新均衡后的 Rope |
2,628,889,679 |
Rope.matcher |
246,633,828 |
优化的结果比起重新均衡后的 rope 明显提高了 10.6 倍,使 rope 的性能与 String 性能的差距缩小到 3.2 倍之内。
|
现在对于 rope 的性能已经有了很好的理解,可以考虑 rope 的一些传统用法,以及在 Java EE 应用程序中吸引人但很可能 并不恰当的用法。
虽然 rope 可以作为一种通用方法替代字符串的连续内存表示法,但是只有在大量修改大型字符串的应用程序中才能看到明显的性能提升。这可能并不让人惊讶,因为最早的 rope 应用程序就是用来在文本编辑器中表示文档。不仅在特大的文档中能够以几乎恒定的时间执行文本插入和删除,rope 的不可修改性还使得 “撤消堆栈(undo stack)” 的实现非常容易:只要在每次修改时保存对前一个 rope 的引用即可。
另一个更加神奇的 rope 应用是表示虚拟机的状态。例如,ICFP 2007 编程竞赛中有一个比赛就是实现一个虚拟机,要求每个周期都修改它的状态,并针对某些输入运行数百万个周期(请参阅 参考资料)。在一个 Java 实现中,虚拟机的速度提高了三个数量级,从 ~50周期/秒提高到超过 50,000/秒,这是通过使用 Rope 代替专门的 StringBuffer 来表示状态而做到的。
虽然 Ropes for Java 是一种新库,但底层概念并不新鲜,该库看起来实现了 rope 的性能许诺。但是,该项目希望通过以下方面在未来的发行版中对库的某些方面进行改进: