日志同步线程 HLog$LogSyncer
hbase.regionserver.optionallogflushinterval默认1秒
配置log syncer线程扫描间隔
更新、增加、删除操作会触发一次WAL,而WAL是同步写入到hadoop的,也就是先写WAL,再做更新(或者删除)
这些操作是在handle线程中完成的
1.handle先创建一个WAL,放入队列中
2.之后检查标志位,是否是同步写WAL
3. a)如果是再从队列中获取WAL,写入到haddop中
b)此时,日志同步线程也会定期检查队列,将队列中的WAL获取后写入到hadoop中
所以这里是有两个地方可以写WAL,handle线程中不管有没有配置同步写标志, LogSyncer线程都会写WAL
LogSyncer默认是1秒同步一次WAL,所以如果配置了handle异步更新WAL,又出现了大量的更新操作
日志队列中的数据将会非常多(包含了很多KeyValue),所以这时应该把检查间隔时间调小
所有的HRegion会共用一个HLog对象,所有的WALEdit是写入到一个队列中
使用异步WAL写会提高整体性能,但LogSyncer的设计并不好,这个实现是wait()一段时间,如果检查队列中数据
则进行处理,由每次都是先wait()再检查队列
更新逻辑如下:
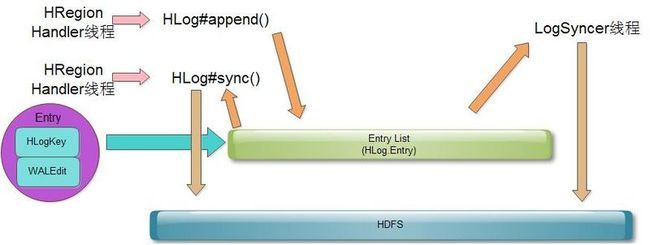
Entry List中存放的是HLog.Entry,Entry是由HLogKey和WALEdit组成的
HLog#append()和HLog#sync()是由handler线程触发的
append()时,不会将WALEdit写入到HDFS中,而是先写入到一个队列中,之后还是这个线程,会检查是否要 同步 更新到HDFS中,如果是异步则会跳过更新,如果是同步,则将WALEdit从队列中取出,然后更新到HDFS中
另外一个线程LogSyncer会定期检查这个队列,如果发现队列中WALEdit,则将其写入到HDFS中
日志回滚线程 LogRoller
hbase.server.thread.wakefrequency 默认1秒,线程sleep的时间
hbase.regionserver.logroll.period 默认3600秒,检查周期
hbase.regionserver.maxlogs 默认32,最大日志数量
hbase.regionserver.hlog.blocksize 默认64M,日志块大小
hbase.regionserver.logroll.multiplier 默认0.95,占用95%日志块空间时回滚
有两种情况会导致当前日志文件被关闭,生成新的日志文件:
1.当前文件size > logrollsize(HDFS文件块大小*0.95),会强制生成一个新文件
2.超过1小时 && HLog有过append()
日志是如何被清空的?(从.logs移动到.oldlogs目录)
1.当一个region的memstroe大小>指定size,就会触发清空,然后将HLog的cache中保存的对应region删除
2.LogRoller线程会定期查找cache中最小的值index,如果在output中有比index更小的值,则将
这些值关联的Path全部移动到.oldlogs中
3.如果定期检查到cache为空则将output中所有的Path移动到.oldlogs中
日志文件过多如何处理?
从output中获取一个最小的序列号index,如果cache中有比index更小的序列号,则将这些序列号。关联的region的memstore全部flush
回滚日志图如下:

序列号是一个原子递增的long类型值
上图中的output存放了的是<序列号,Path>的键值对
Path就是一个HLog文件的绝对路径(HDFS文件的路径)
每个HLog文件中包含了若干个Entry实体,一个实体会有一个序列号,每个序列号都是递增的,一个HLog文件关联的是这个文件中最大的序列号
cache(源码中不是叫这个名字)存放的是<region名称,第一次保存的序列号>
region名称是用于之后flush时使用的
HLog#append()时,会记录当前delete/put到哪个region上,而每次append()时候都会创建一个
递增的序列号,一个region上保存的Entry就会有多个递增序列号,cache中保存的是这个
region最小的序列号,也就是第一次保存时的序列号
cache中保存的序列号不像output那样,可能是无规律的,比如HLog文件aa中:
101是在region1上保存的,102在region2上,103在region3上
也有可能是100-105全都保存在region1上,110保存在region2上
cache是缓存region的,如果当前的region被flush了,就从cache中删除
而output保存的是具体hlog的HDFS路径,它会根据cache的内容,删除自身的hlog
日志回滚的详细步骤:
假设cache中的region1已经执行了flush,此时region1就从cache中移除了,那么cache中最小的值就是112,如果region2也被移除了,那么最小的值就是132
再从output中找到一个比112小的值,这个是105。105关联的Path是aa,所以将aa移动到.oldlogs中。如果cache中为空则将output中所有的Path都移动到.oldlogs中
日志文件过多处理的详细步骤:
从output中找到一个最小的值105,再从cache中找到比这个105小的值,也就是100,100关联了region1,所以将region1的memstore做刷新,之后日志回滚线程发现cache中最小的值就变成了112,output中小于112的是105,于是将105关联的Path aa移动到.oldlogs中
如果一个HLog中序列号对应的region是这样的:
region1->100, region2->101, region3->102,region4->103,region5->104
此时日志回滚线程的output中找到的是105,它找不到cache中比105更小的值了,所以无法回滚。
但是根据日志文件过多判断的逻辑:
output中找到的最小值是105,cache中比这个值小的就是5个region(region1到region5)于是将这
5个region的memstore全部刷新,这样日志回滚线程下次再判断的时候会能找到很多比105小的值了
所以日志过多处理逻辑最终是配合回滚逻辑一起做的,对应各种场景,最终是将无用的.logs文件清除
默认的最大日志文件数是32,但是也有可能出现超过32个日志文件的情况
master节点处理过程
一些配置:
hbase.splitlog.zk.retries 默认为3,连接到zk的重试次数
hbase.splitlog.max.resubmit 默认为3,最多重提交的次数
hbase.splitlog.manager.timeout 默认300秒
hbase.splitlog.manager.unassigned.timeout 默认180秒
hbase.splitlog.manager.timeoutmonitor.period 默认1秒
1.当有一台region server宕机后,zookeeper会将/hbase/rs中的region server删除,然后触发一个节
点被删除的事件,master收到这个事件之后会遍历调用多个监听类
2.最后由RegionServerTracker处理这个事件,获取这个region server名字,由
ServerManager#expireServer()处理
3.判断宕机的regioin server是否包含了META或ROOT表,如果是核心表则由
MetaServerShutdownHandler处理,否则
由ServerShutdownHandler处理,这个处理过程是由其他线程来做的
SplitLogManager过程
1.split manager将.logs目录重命名
/hbase/.logs/srv.example.com,60020,1254173957298-splitting
2.将所有的路径都注册到znode上,同时还会创建一个回调任务,之后zookeeper会触发这个回调函数
3.等待并监控/hbase/splitlog节点的任务完成
4.删除重命名的.logs目录
分配新的region
1.当日志切分完毕后ServerShutdownHandler调用AssignmentManager将获取所有宕机的RS
2.将这些RS的所有region都放到ZK的/hbase/unassigned目录下
3.随机找一些已经启动的RS,向这些RS发送openRegion的RPC请求
4.这些RS会获取/hbase/unassigned目录下未分配的region,然后启动他们
整个过程如下图:
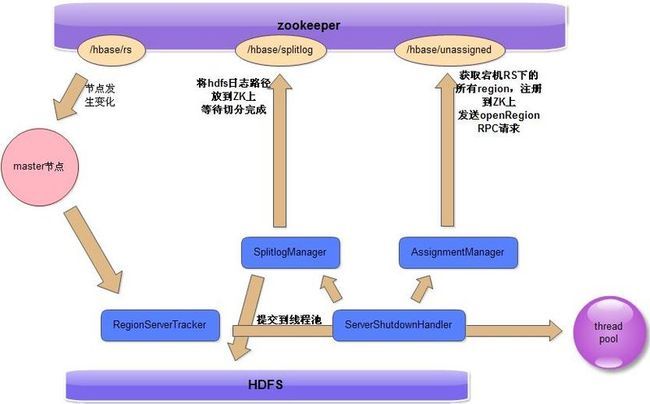
RS日志切分处理过程
SplitLogWorker 线程
1.检查znode: /hbase/splitlog 是否存在
2.从/hbase/splitlog获取zonde列表
3.对zonode列表遍历,获取当前的数据,检查是否是未分分配状态,如果是则赏识独占这个znode
4.调用HLogSplit#splitLogFile()对,对当前的HLog进行处理
znode中一个未处理的文件路径为:
/hbase/.logs/myhost,60020,1394445133232-splitting/myhost%2C60020%2C1394445133232.1394445137649
HLogSplit#splitLogFile()
hbase.splitlog.report.interval.loglines默认值为1024,达到这个值后,会回调一个处理逻辑
hbase.splitlog.report.openedfiles默认值为3,如果打开的文件数超过这个值,也也调用处理逻辑
1.创建 SequenceFileLogReader,然后遍历文件中的Entry
2.根据Entry的key,HLogKey,可以拿到region的名字,之后创建recovered.edits目录
3.检查这个region目录是否存在,如果不存在则返回null,返回为null就认为这个region不存在,记录一个错误
标志,之后所有在这个region上的Entry都会忽略掉,编辑日志的路径放在这个目录下:
比如/hbase/table-name/ca042068d2decd9dd5ec3f511b274d85/recovered.edits
4.创建一个格式化的临时文件,之后会将数据写入到这个临时文件中
文件为:0000000000000001000,文件长19位,不足19的前面补0
5.创建一个SequenceFileLogWriter,将读取到的Entry写入到之前创建的临时文件中
6.循环读取这个文件,直到读取完毕
7.之后是收尾,将所有的的的临时文件关闭,也就是将数据sync到文件中。如果有不存在的region则忽略
8.因为在向临时文件写Entry的时候,每写一次会生成一个递增序列号,此时获取写入这个文件的最大的序列号,并将
原先的临时文件文件改名
原先:recovered.edits/0000000000000001000.temp 改为:recovered.edits/0000000000000001099
整个处理过程如下:
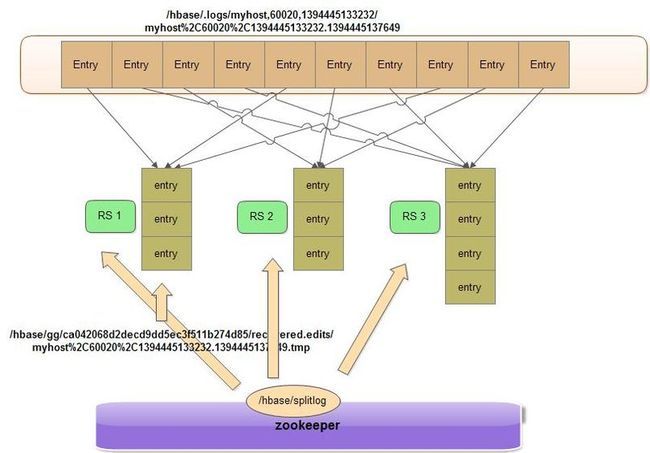
RS启动region
1.首先RS会收到一个RCP请求,这个请求是由master触发的
2.之后根据请求中的内容,得到regioin信息,WAL参数等提交到线程池中,由OpenRegionHandler处理
3.OpenRegionHandler首先会初始化,并行初始化多个Store(也就是多个column)提交到线程池执行
4.之后就开始做日志回放,如果没有回放日志则跳过
5.首先取得当前目录下的recovered.edits的所有HLog文件,然后依次遍历这些文件
6.读取一个HLog依次获取所有的Entry#WALEdit,然后将其中的kv存储到Store中
7.Sotre中又包含了一个memstore和若干个HFile,所以这里的kv是存到memstore中
7.memstore内部用KeyValueSkipListSet存储,如果保存时超过上限则会触发flush
8.回放完毕后会根据当前region策略创建split策略,并将recovered.edits目录删除
9.之后是更新meta表,由PostOpenDeployTaskThread处理(在新线程中执行)
10.更新时会判断是root表meta表还是普通表
11.最后删除ZK中的/hbase/unassigned下对应的region,并将此region上线
完整过程如下:
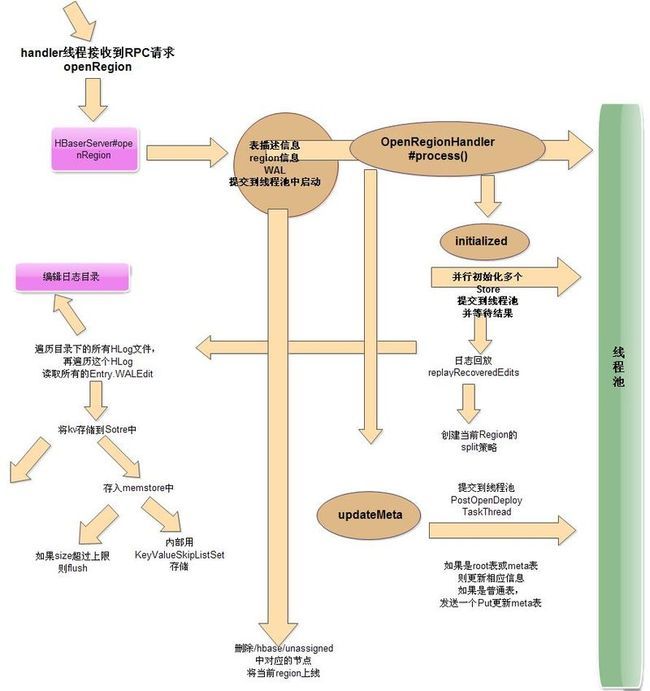
一些事件处理类:
Master将下面一些类注册到zookeeper时间监听中,当znode发生改变时,就会触发这些类,进行相应的处理
如节点数据更改,节点增加,节点删除,子节点发生变化等
这些类继承了ZooKeeperListener:
org.apache.hadoop.hbase.master.AssignmentManager
org.apache.hadoop.hbase.master.ActiveMasterManager
org.apache.hadoop.hbase.zookeeper.ClusterStatusTracker
org.apache.hadoop.hbase.master.SplitLogManager
org.apache.hadoop.hbase.zookeeper.RootRegionTracker
org.apache.hadoop.hbase.catalog.CatalogTracker$2
org.apache.hadoop.hbase.zookeeper.RegionServerTracker
org.apache.hadoop.hbase.zookeeper.DrainingServerTracker
org.apache.hadoop.hbase.procedure.ZKProcedureCoordinatorRpcs$1
region server的注册的zookeeper监听类
org.apache.hadoop.hbase.MasterAddressTracker
org.apache.hadoop.hbase.zookeeper.ClusterStatusTracker
org.apache.hadoop.hbase.zookeeper.RootRegionTracker
org.apache.hadoop.hbase.catalog.CatalogTracker$2
org.apache.hadoop.hbase.procedure.ZKProcedureMemberRpcs$1
org.apache.hadoop.hbase.regionserver.SplitLogWorker
RS宕机所有region转移的过程简介
1.master收到ZK的事件,发现/hbase/rs下的region server没有了,遍历所有的监听事件
由SplitlogManager将.log目录文件路径挂到zk的/hbase/splitlog下,
同时监控这个目录,如果发现有操作时间过长的文件则重新提交,如果发现/hbase/splitlog下的文件都处理
完了,则将hdfs://hbase/.log-spliting 目录删除
获取这个region server下的所有region,将这些region放到ZK的/hbase/unassigned下
2.RS收到ZK的事件,/hbase/splitlog有变化了,将SplitlogWorder线程唤醒,处理事件
开始做日志切分,将hdfs://hbase/.log-spliting目录下的文件按region切分放到
/hbase/table-name/encode/recovered.edits目录下
3.master发现整个日志切分过程完毕,找一台在线的RS,发送openRegion的RPC请求
RS收到RCP会开始做Region初始化,做日志重放操作,将/hbase/unassigned下的region encode删除,将这个region上线
move的过程就是先调用closeRegion RPC,然后再调用openRegion RPC