客户端相关参数
| 参数 | 默认值 | 含义 |
| hbase.htable.threads.max | 2147483647 | 线程池中的线程数量 |
| hbase.htable.threads.keepalivetime | 60秒 | keepalive时间 |
| hbase.client.pause | 1秒 | 重试的休眠时间 |
| hbase.client.retries.number | 10 | 重试次数 |
| hbase.client.rpc.maxattempts | 1 | |
| hbase.rpc.timeout | 60秒 | |
| hbase.client.prefetch.limit | 10 | |
| hbase.client.write.buffer | 2097152 | |
| hbase.client.scanner.caching | 1 | 一次从服务端抓取的数量 |
| hbase.client.keyvalue.maxsize | -1 | |
| hbase.meta.scanner.caching | 100 |
在连接之前会创建如下信息
ZooKeeperWatcher
ClusterId获取/hbase/hbaseid
MasterAddressTracker获取/hbase/master
RootRegionTracker获取/hbase/root-region-server(也是-ROOT-表所在的机器)
RCP Engineorg.apache.hadoop.hbase.ipc.WritableRpcEngine
查询过程

org.apache.hadoop.hbase.client.HConnectionManager#locateRegion()函数主要逻辑如下
//假设此时请求一个test表
locateRegion() {
ensureZookeeperTrackers(); //创建zookeeper相关连接并获取相关数据
if(当前表示root表) {
//返回root表的连接
ServerName servername = this.rootRegionTracker.waitRootRegionLocation(this.rpcTimeout);
return new HRegionLocation(HRegionInfo.ROOT_REGIONINFO,
servername.getHostname(), servername.getPort());
}
else if(当前表是meta表) {
locateRegion("-ROOT-")
}
else {
locateRegionInMeta(".META.")
}
}
调用的堆栈图如下

堆栈执行过程
6.waitRootRegionLocation() 检查/hbase的znode节点是否存在
|
|
5.locateRegion()
|
|
4.locateRegionInMeta() 在查找META表之前需要先找到ROOT表
|
|
3.locateRegion()
|
|
2.locateRegionInMeta() 在查找test表之前首先需要找到META表
|
|
1.locateRegion()
ROOT表和META表内容
root表
| row | column | value |
| .META.,,1 | info:regioninfo | NAME => '.META.,,1', STARTKEY => '', ENDKEY => '', ENCODED => 1028785192, |
| .META.,,1 | info:server | myRegionServerA:60020 |
| .META.,,1 | info:serverstartcode | 1423222810704 |
| .META.,,1 | info:v | \x00\x00 |
meta表
| row | column | value |
| test,,1396452445291.79608271 b40352162a9f255817ce44bf. |
info:regioninfo | NAME => 'test,,1396452445291.79608271b 40352162a9f255817ce44bf.', STARTKEY => '', ENDKEY => 'bbb_mykey98', ENCODED => 79608271b40352 162a9f255817ce44bf, |
| test,,1396452445291.79608271 b40352162a9f255817ce44bf. |
info:server | myRegionServerF:60020 |
| test,,1396452445291.79608271 b40352162a9f255817ce44bf. |
info:serverstartcode | 1410425110025 |
| test,bbb_mykey99,1396452445 291.00f93d1c191a66031ece7a 4ce0eac493. |
info:regioninfo | NAME => 'kvdb,bbb_mykey99,13964524 45291.00f93d1c191a66031ece7a4ce0eac 493.', STARTKEY => 'bbb_mykey99', END KEY => 'fff_mykey', ENCODED => 00f93d 1c191a66031ece7a4ce0eac493, |
| test,bbb_mykey99,1396452445 291.00f93d1c191a66031ece7a 4ce0eac493. |
info:server | myRegionServerC:60020 |
| test,bbb_mykey99,1396452445 291.00f93d1c191a66031ece7a 4ce0eac493. |
info:serverstartcode | 1410425110025 |
| zeroTable,,1423538052180.31 dd24d20f348098f3bf05313478177f. |
info:regioninfo | NAME => 'zeroTable,,142353805218 0.31dd24d20f348098f3bf0531347817 7f.', STARTKEY => '', ENDKEY => 'zz_99', ENCODED => 31dd24d20f348098f3bf05313478177f, |
| zeroTable,,1423538052180.31 dd24d20f348098f3bf05313478177f. |
info:server | myRegionServerB:60020 |
| zeroTable,,1423538052180.31 dd24d20f348098f3bf05313478177f. |
info:serverstartcode | 1423222810704 |
root表的定位和查询过程
waitRootRegionLocation()
1.这里首先检查/hbase这个根节点是否存在,如果不存在直接返回false
if (ZKUtil.checkExists(watcher, watcher.baseZNode) == -1) {
return false;
}
2.之后获取root表所在的机器信息(也就是/hbase/root-region-server节点信息)
return dataToServerName(super.blockUntilAvailable(timeout, true));
3.之后会触发一次RPC连接
HRegionInterface server =
getHRegionConnection(metaLocation.getHostname(), metaLocation.getPort());
最终会创建一个代理类,也就是一个RPC类,连接到-ROOT-表所在的机器
这个连接也会放到缓存中
4.之后会触发一次RPC请求,连接到ROOT表所在的机器,然后确定待查询的META信息在哪个机器上,这次会生成一个key为,可以看出这里的格式为 .META.,[表名],[第一个key这里是空着的],99999,99999
.META.,test,,99999999999999,99999999999999(也就是META表中关于test的第一条记录,两个9999都是固定加上的没有任何意义做)
如果线上环境数据量不是特别大的话,META表就只有一个region,反映到ROOT中就只有一个key(一个key有四个keyvalue,所以会有四条记录)
之后会返回这些跟META相关的数据
META表和一次get查询的定位过程

执行的主要逻辑如下:
1.根据ROOT表查到的META相关信息,比如通过ROOT获取到的信息如下
keyvalues={.META.,,1/info:regioninfo/1373105037550/Put/vlen=34/ts=0, .META.,,1/info:server/1410417243783/Put/vlen=15/ts=0, .META.,,1/info:serverstartcode/1410417243783/Put/vlen=8/ts=0, .META.,,1/info:v/1373105037550/Put/vlen=2/ts=0}
2.然后解析这个数据获取机器相关信息,再创建一个RPC连接到META机器上
3.执行一个MetaScanner#metaScan()查询
4.将获取的META主机信息缓存起来并返还
5.执行get查询
6.触发一次PRC查询,查询的key为zzzz_mykey,此时会先查询META表,key被封装为
test,zzzz_mykey,99999999999999这样的格式
7.再执行一次MetaScanner#metaScan()查询
8.像regionserver机器发起一次PRC查询并返还get查询的结果
MetaScanner#metaScan()逻辑
1.根据startRow(比如test,zzzz_mykey,99999999999999)获取一个结果集Result
这里的zzzz_mykey可以为空,这就相当于查询第一个key所在的region,返回的Result中就包含了这个
region的元信息(region的启动时间,ecode编码,机器名称等。当把key通过RPC发到服务端后,
服务端自动做前缀定位查询这个时间是固定的(第一个key和最后一个key定位时间相同)
2.解析结果并生成一个RegionInfo
3.创建Scan(默认获取10条结果) 这里的startRow就是刚刚Result中返回的信息
Scan scan = new Scan(startRow).addFamily("info")
4.遍历结果并将获取到的结果(主机信息)缓存起来
如果只是get查询的话,最后会返回这个机器的信息,然后向这个机器发起一次RPC请求,并返回最终结果。
get的执行过程
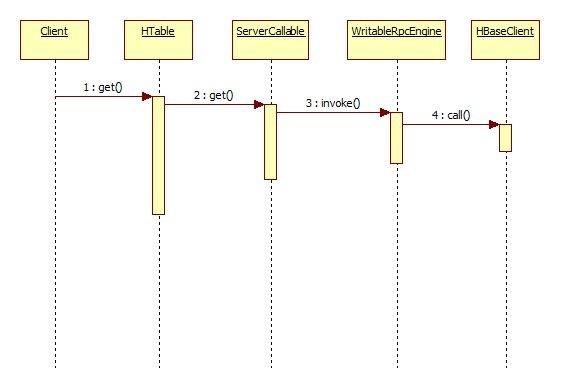
在代码中并不是调用ServerCallable,而是实现它的匿名内部类
HTable#get()函数如下
public Result get(final Get get) throws IOException {
return new ServerCallable<Result>(connection, tableName, get.getRow(), operationTimeout) {
public Result call() throws IOException {
return server.get(location.getRegionInfo().getRegionName(), get);
}
}.withRetries();
}
ServerCallable#withRetries()函数简化内容
这里有一个重试的逻辑(默认10次),最后回调call()函数
当出现异常的时候,可能是因为region下线,分割等原因会尝试再次访问meta表并清空缓存中的内容
for (int tries = 0; tries < numRetries; tries++) {
try {
beforeCall();
connect(tries != 0);
return call();
} catch (Throwable t) {
shouldRetry(t);
t = translateException(t);
if (t instanceof SocketTimeoutException ||
t instanceof ConnectException ||
t instanceof RetriesExhaustedException) {
// if thrown these exceptions, we clear all the cache entries that
// map to that slow/dead server; otherwise, let cache miss and ask
// .META. again to find the new location
HRegionLocation hrl = location;
if (hrl != null) {
getConnection().clearCaches(hrl.getHostnamePort());
}
} else if (t instanceof NotServingRegionException && numRetries == 1) {
// Purge cache entries for this specific region from META cache
// since we don't call connect(true) when number of retries is 1.
getConnection().deleteCachedRegionLocation(location);
}
RetriesExhaustedException.ThrowableWithExtraContext qt =
new RetriesExhaustedException.ThrowableWithExtraContext(t,
System.currentTimeMillis(), toString());
exceptions.add(qt);
if (tries == numRetries - 1) {
throw new RetriesExhaustedException(tries, exceptions);
}
} finally {
afterCall();
}
try {
Thread.sleep(ConnectionUtils.getPauseTime(pause, tries));
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new IOException("Giving up after tries=" + tries, e);
}
}
return null;
}
}
WritableRpcEngine#invoke()函数如下
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
final boolean logDebug = LOG.isDebugEnabled();
long startTime = 0;
if (logDebug) {
startTime = System.currentTimeMillis();
}
HbaseObjectWritable value = (HbaseObjectWritable)
client.call(new Invocation(method, protocol, args), address,
protocol, ticket, rpcTimeout);
return value.get();
}
}
最终会调用到HBaseClient,然后发送一个socket请求
HBaseClient#call()函数如下
public Writable call(Writable param, InetSocketAddress addr,
Class<? extends VersionedProtocol> protocol,
User ticket, int rpcTimeout)
throws InterruptedException, IOException {
Call call = new Call(param);
Connection connection = getConnection(addr, protocol, ticket, rpcTimeout, call);
connection.sendParam(call); // send the parameter
boolean interrupted = false;
//noinspection SynchronizationOnLocalVariableOrMethodParameter
synchronized (call) {
while (!call.done) {
try {
call.wait(); // wait for the result
} catch (InterruptedException ignored) {
// save the fact that we were interrupted
interrupted = true;
}
}
if (interrupted) {
// set the interrupt flag now that we are done waiting
Thread.currentThread().interrupt();
}
if (call.error != null) {
if (call.error instanceof RemoteException) {
call.error.fillInStackTrace();
throw call.error;
}
// local exception
throw wrapException(addr, call.error);
}
return call.value;
}
}
HBaseClient#sendParam()函数如下
同步块中的 out.write(data, 0, dataLength);
是调用 org.apache.hadoop.net.SocketOutputStream底层是用NIO实现的
这里的call是HbaseClient的内部类Call,其发送的对象是Writable实现类,也就是可序列化的
Call中发送的参数是org.apache.hadoop.hbase.ipc.Invocation
发送的参数中包含两个值,一个是id,一个是对象(比如这里就是Get对象)
protected void sendParam(Call call) {
if (shouldCloseConnection.get()) {
return;
}
// For serializing the data to be written.
final DataOutputBuffer d = new DataOutputBuffer();
try {
d.writeInt(0xdeadbeef); // placeholder for data length
d.writeInt(call.id);
call.param.write(d);
byte[] data = d.getData();
int dataLength = d.getLength();
// fill in the placeholder
Bytes.putInt(data, 0, dataLength - 4);
//noinspection SynchronizeOnNonFinalField
synchronized (this.out) { // FindBugs IS2_INCONSISTENT_SYNC
out.write(data, 0, dataLength);
out.flush();
}
} catch(IOException e) {
markClosed(e);
} finally {
//the buffer is just an in-memory buffer, but it is still polite to
// close early
IOUtils.closeStream(d);
}
}
delete的执行过程
HTable#delete()内容如下:
注意如果是批量删除的话最终会异步执行,然后等待结果。如果只删除一条则同步执行
public void delete(final Delete delete)
throws IOException {
new ServerCallable<Boolean>(connection, tableName, delete.getRow(), operationTimeout) {
public Boolean call() throws IOException {
server.delete(location.getRegionInfo().getRegionName(), delete);
return null; // FindBugs NP_BOOLEAN_RETURN_NULL
}
}.withRetries();
}
public void delete(final List<Delete> deletes)
throws IOException {
Object[] results = new Object[deletes.size()];
try {
connection.processBatch((List) deletes, tableName, pool, results);
} catch (InterruptedException e) {
throw new IOException(e);
} finally {
// mutate list so that it is empty for complete success, or contains only failed records
// results are returned in the same order as the requests in list
// walk the list backwards, so we can remove from list without impacting the indexes of earlier members
for (int i = results.length - 1; i>=0; i--) {
// if result is not null, it succeeded
if (results[i] instanceof Result) {
deletes.remove(i);
}
}
}
}
总体来说跟get差不多,这里就不再详细介绍了
后面的时序图中省略了HBaseClient部分(这个类主要是发送最终的请求,所以可以忽略)
从get的执行过程可以看到,有一个重试逻辑(默认10次),主要是region切分的时候下线等原因找不到出现的重试,对于scan,delete,put等操作都会有重试逻辑的,后面就省略这部分介绍了。
put的执行过程
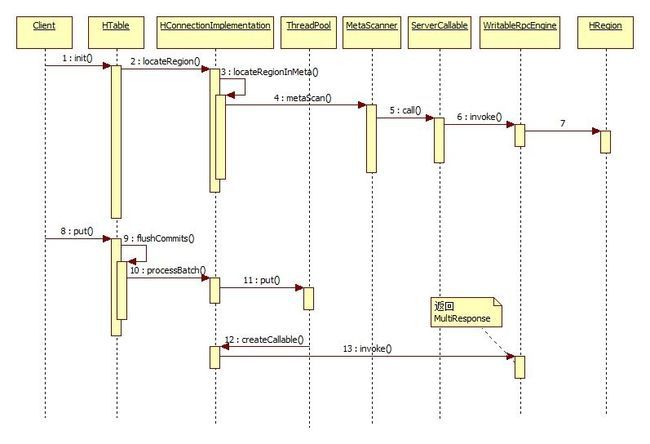
这里实际上是已经假设put执行过程中调用了flushCommits()了,也就是写入后直接提交,如果不提交或者当前的缓存未满则不会有异步提交那些过程
首先初始化HTable的过程跟上面介绍的查询过程是一样的
这里有两个put函数
public void put(final Put put) throws IOException {
doPut(put);
if (autoFlush) {
flushCommits();
}
}
public void put(final List<Put> puts) throws IOException {
for (Put put : puts) {
doPut(put);
}
if (autoFlush) {
flushCommits();
}
}
doPut()首先将数据放到缓存中,当缓存满了之后再插入
private void doPut(Put put) throws IOException{
validatePut(put);
writeBuffer.add(put);
currentWriteBufferSize += put.heapSize();
if (currentWriteBufferSize > writeBufferSize) {
flushCommits();
}
}
最终会调用 HConnectionImplementation#processBatchCallback()它的核心逻辑如下
1.定位具体的Region,使用locateRegion()函数具体过程跟上面介绍的内容一样
这里会有一个重试,默认10次每次间隔1秒
2.将List<Put>或者Put放到线程池中
for (Entry<HRegionLocation, MultiAction<R>> e: actionsByServer.entrySet()) {
futures.put(e.getKey(), pool.submit(createCallable(e.getKey(), e.getValue(), tableName)));
}
3.遍历结果
for (Entry<HRegionLocation, Future<MultiResponse>> responsePerServer : futures.entrySet()) {
HRegionLocation loc = responsePerServer.getKey();
Future<MultiResponse> future = responsePerServer.getValue();
MultiResponse resp = future.get();
}
4.处理异常信息及扫尾工作
线程池中的线程会调用HConnectionImplementation#createCallable()
最终发送一个RPC请求,将List<Put>或者Put中的内容发送给服务端
发送的RPC是一个封装的MultiAction,这个对象里面有包含了多个Action,每个Action就是对一个Put的
封装
最终会返回MultiResponse,这是对象里面包含了多个Pair(一个Pair就是对KeyValue的封装),如果是
Put操作则也会根据插入的数据返回相应的Pair,但是里面的KeyValue是空
scan的执行过程

执行过程如下
//假设客户端调用代码如下
HTable table = new HTable(cfg, "test");
ResultScanner rs = table.getScanner(scan);
for(Result r : rs) {
List<KeyValue> list = r.list();
for(KeyValue kv : list) {
System.out.println(new String(kv.getRow())+"---"+new String(kv.getValue()))
}
}
//table.getScanner()会先初始化scan,核心逻辑为
nextScanner() {
1.获取startKey和endKey
2.scan对象.set(startKey)
3.new ScannerCallable(scan对象,抓取数量)
4.ScannerCallable.withRetries() //发送RPC请求
}
//再由ClientScanner调用ScannerCallable#call,ScannerCallable#call()的主要逻辑
//在scan之前需要先获得一个scan的ID,然后每次scan的时候都需要带上这个id
//最终发送的RPC有两个参数,一个是scan的ID,第二个是抓取的数量
call() {
if(scannerId!=-1L && closed) {
close();
}
else if(scannerID==-1L && !closed) {
scannerId = openScanner();
}
else {
Result[] rss = WritableRpcEngine.next(scannerId,caching);
}
return rss;
}
//当执行到for(Result r : rs)时候会调用到
AbstractClientScanner#hasNext() {
Result next = ClientScanner.next();
return Result;
}
//ClientScanner#next()核心逻辑
//当设置了抓取数量为2时候,执行RPC后服务端会返回两个Result,然后将这两个Result放到cache中
//当cache中没有数据时会再次向服务端发送RPC请求抓取数据
next() {
if(cache.size() == 0) {
ScannerCallable.setCaching(需要抓取的数量);
Result[] values = ScannerCallable.withRetries();
for (Result rs : values) {
cache.add(rs);
}
}
if(cache.size() > 0) {
return cache.poll();
}
}
scan中如果出现了跨region的处理过程
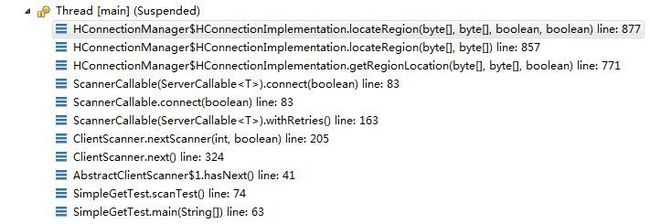
上图是scan跨region时的一个时序图,其中关键的处理部分是ClientScanner#next()函数
countdown就是一次需要抓取的数量,比如一共抓取了5个,如果此时抓取了3个之后region就到头了,于是返回
在遍历的时候countdown就减减然后变成了2
do-while的while中有一个nextScanner(),前面两个都是判断条件,当没有出现跨regin访问时countdown都会变成0的,所以最后的nextScanner()就不会被触发了,而此时countdown是不为0的于是执行nextScanner()了
可以看到在nextScanner()中又会调用ServerCallable#connect()函数,获取一个远端的连接。而这个过程就是前面介绍的test表-->meta表-->root表的过程。
public Result next() {
int countdown = this.caching;
callable.setCaching(this.caching);
do {
// Server returns a null values if scanning is to stop. Else,
// returns an empty array if scanning is to go on and we've just
// exhausted current region.
values = callable.withRetries();
if (values != null && values.length > 0) {
for (Result rs : values) {
cache.add(rs);
for (KeyValue kv : rs.raw()) {
remainingResultSize -= kv.heapSize();
}
countdown--;
this.lastResult = rs;
}
}
// Values == null means server-side filter has determined we must STOP
}while (remainingResultSize > 0 && countdown > 0 && nextScanner(countdown, values == null));
}
flush的过程
注意是 HTable#flushCommits,不是admin的flush

flush的过程实际上跟put,delete(批量删除)等很类似,相当于是做一次批量提交到远端
重点看一下processBatchCallback()函数
void processBatchCallback() {
for (int tries = 0; tries < numRetries && retry; ++tries) {
//1.第一步将所有的操作加入到MultiAction中
Map<HRegionLocation, MultiAction<R>> actionsByServer =
new HashMap<HRegionLocation, MultiAction<R>>();
for (int i = 0; i < workingList.size(); i++) {
Row row = workingList.get(i);
if (row != null) {
HRegionLocation loc = locateRegion(tableName, row.getRow());
byte[] regionName = loc.getRegionInfo().getRegionName();
MultiAction<R> actions = actionsByServer.get(loc);
if (actions == null) {
actions = new MultiAction<R>();
actionsByServer.put(loc, actions);
}
Action<R> action = new Action<R>(row, i);
lastServers[i] = loc;
actions.add(regionName, action);
}
}
//2.提交到线程池中
Map<HRegionLocation, Future<MultiResponse>> futures =
new HashMap<HRegionLocation, Future<MultiResponse>>(actionsByServer.size());
for (Entry<HRegionLocation, MultiAction<R>> e: actionsByServer.entrySet()) {
futures.put(e.getKey(), pool.submit(createCallable(e.getKey(), e.getValue(), tableName)));
}
//3.获取结果
for (Entry<HRegionLocation, Future<MultiResponse>> responsePerServer
: futures.entrySet()) {
HRegionLocation loc = responsePerServer.getKey();
Future<MultiResponse> future = responsePerServer.getValue();
MultiResponse resp = future.get();
}
}
//4.处理异常
}
admin操作-flush
将指定的region或者全表中的所有region都刷新,从而强制将memstore中的数据写到HFile中
最终会调用HBaseClient#call()触发一个RPC请求,发送一个 flushRegion 调用
如果当前的表包含了10个region,则会触发10次 flushRegion调用
之后服务端接收到这个flushRegion请求后,将当前region中的数据刷新到HFile中
public void flush(final byte [] tableNameOrRegionName) {
Pair<HRegionInfo, ServerName> regionServerPair
= getRegion(tableNameOrRegionName, ct);
if (regionServerPair != null) {
flush(regionServerPair.getSecond(), regionServerPair.getFirst());
}
else {
final String tableName = tableNameString(tableNameOrRegionName, ct);
List<Pair<HRegionInfo, ServerName>> pairs =
MetaReader.getTableRegionsAndLocations(ct,tableName);
for (Pair<HRegionInfo, ServerName> pair: pairs) {
if (pair.getFirst().isOffline()) continue;
if (pair.getSecond() == null) continue;
flush(pair.getSecond(), pair.getFirst());
}
}
}
private void flush(final ServerName sn, final HRegionInfo hri) {
HRegionInterface rs = this.connection.getHRegionConnection(
sn.getHostname(), sn.getPort());
rs.flushRegion(hri);
}
参考