挖掘FP-Tree
关联规则如何并行实现呢?一个很直观的想法是要么分数据要么分计算。本文要说的是分数据,想法来自mahout的fp-tree并行实现。其中分数据的博客已在前篇 mahout关联规则FPGrowthDriver源码分析之如何分数据中说明,如何建树可以在网上查找(这个相对来说比较简单)或者直接看此片论文:《Mining FrequentPatterns without Candidate Generation》,这篇博客要说的是如何挖掘已经建好的FP-tree,也是参考《Mining FrequentPatterns without Candidate Generation》的(最好对照原篇来看,原篇为全英)。
先把建好的树贴出来看:
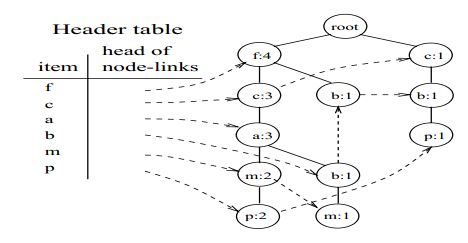
挖掘的过程即为遍历Header table中的每个item,然后重新构造事务集,以及相应的f-list,然后重新建树的过程。下面就p和m项目进行演示:
查找项目p在fp-tree的链接可以找到两条路径:f,c,a,m:2; c,b:1 这里的次数以p的次数为准,比如f:4,c:3,a:3,m:2,因为后面的p:2,所以f,c,a,m:2;
则其事务集为{[f,c,a,m:2],[c,b:1]},其g-list为c:3;所以其建好的树为:

由于上面的树是单支(原文为:only onebranch),所以可以直接输出模式cp:3。(此处默认的阈值为3)
对于项目m,其事务集为 {[f,c,a:2],[f,c,a,b:1]},g-list: [f:3,c:3,a:3],事务集根据g-list进行删减项目得到新的事务集为{[f,c,a:2],[f,c,a:1]},则由新的事务集和g-list构造的fp-tree为:

对上面的树的挖掘和最开始的树是一样的,即分别对项目a、c、f进行挖掘。
1. 项目a:
输出(am:3)模式同时调用"mine(f:3,c:3)|am" ,"mine(f:3,c:3)|am" 输出(cam:3,fam:3)模式,以及调用"mine(f:3)|cam",这个调用输出(fcam:3)模式 ;
2. 项目c:
输出(cm:3)模式同时调用"mine(f:3)|cm","mine(f:3)|cm"输出(fcm:3)
3. 项目f:
直接输出模式(fm:3)
所以最原始的树上面项目p生成的模式为:(cp:3),项目m生成的模式为:(am:3)(cam:3)(fam:3)(fcam:3)(cm:3)(fcm:3)(fm:3)。其他的项目按照上面同样的规则进行生成频繁项目集。
分享,快乐,成长
转载请注明出处:http://blog.csdn.net/fansy1990