UrlRewriter 缓存问题
在开发一个网站功能时,由于session 缓存不能及时清除。开始了一系列的探索。
现找到几篇不错的文章。
首先是 F5和 CTRL+F5的区别背景
我司的网站是框架结构的,一个页面里有多个iframe.正因为这个原因,每次当我自信满满的把修改过的JS文件提交到SVN上后,没过多久,某个 后台程序员就会来找我说:怎么JS还报错呢,我已经CTRL+F5了啊,你提交对了吗.我只好到他座位上拿起鼠标进行操作:右键->本帧-> 在新标签中打开新帧->CTRL+F5->切换到原标签->F5.这一番操作之后,终于对了.同样的事情已经发生过很多次了.这也证明 了不少程序员同志还是不够了解浏览器的缓存机制.
基础知识
问题的根本原因就是,在火狐里,CTRL+F5清除不了框架页面的缓存.包括框架页面本身和其所有的嵌入元素(.js,.css,.jpg等).所以本文的真正标题是"Firefox中如何才能跳过缓存刷新框架内的页面".首先我要讲一下相关的基础知识.
一.读取缓存
搞WEB开发的经常会说:有缓存,CTRL+F5一下.或者:有缓存,CTRL+SHIFT+DEL清一下.那么你知道浏览器有几种方式来读取缓存文件吗.从是否发送了HTTP请求来区分,我觉的可以分两种:
1.浏览器从服务器返回的过期时间判断得出,该文件还没有过期,所以直接从缓存文件夹读取缓存文件,显示网页,并没有走任何网络连接.
2.浏览器发送HTTP请求,请求头中包含了If-Modified-Since 和 If-None-Match字段.让服务器来判断是否应该读取缓存文件.如果服务器返回304响应,无响应实体,表示服务器认为这个文件没有变化.可以使 用缓存中的对应文件,这时浏览器才会读取缓存.(如果不了解HTTP,可以买本<<HTTP权威指南>>看看.或者直接RFC2616)
我把第一种读取缓存的方式称之为"无请求读取缓存",第二种方式称之为"无修改读取缓存".
二.刷新方式
这里的刷新方式是指能通过哪些方式让一个网页重新加载,我从表现上大概分了三种:
1.最常用的,点击浏览器的刷新按钮,或者按下F5
2.CTRL+F5,功能是跳过缓存刷新
3.浏览器地址栏上回车,IE里把这种请求方式归为"导航"操作
在读取缓存方面,这三种刷新方式的表现都不一样.第三种方式的表现通常是只刷新主页面文件,其他内嵌文件全部"无请求读取缓存".大部分开发者都不会这么刷新页面,所以本次试验不对比这种刷新方式.
三.F5和CTRL+F5的区别
本文的试验部分只针对F5和CTRL+F5两种刷新方式做对比.这里讲一下为什么F5不能跳过缓存,而后者可以.答案就是发送的请求头不一样.而且不同的浏览器发送的请求头也有一些区别.
1.F5触发的HTTP请求的请求头中通常包含了If-Modified-Since 或 If-None-Match字段,或者两者兼有.如果服务器认为被请求的文件没有发生变化,则返回304响应,也就没有跳过缓存.
2.CTRL+F5触发的HTTP请求的请求头中没有上面的那两个头,却有Pragma: no-cache 或 Cache-Control: no-cache 字段,或者两者兼有.服务器看到no-cache这样的值就会把最新的文件响应过去.也就跳过了缓存.
试验对比
试验题目为:使用F5和CTRL+F5在包含iframe的页面上进行刷新操作,五大浏览器各自的表现不同.本次试验使用Fiddler监测网络请求,而且不考虑缓存相关的HTTP响应头的影响.
主页面index.html源码为
|
1
2
3
4
5
6
7
8
9
10
11
|
<!DOCTYPE HTML>
<
html
>
<
head
>
<
meta
charset
=
"utf-8"
/>
</
head
>
<
body
>
<
iframe
src
=
"frame.html"
></
iframe
>
<
img
src
=
"index.jpg"
/>
<
script
src
=
"index.js"
></
script
>
</
body
>
</
html
>
|
框架页面frame.html源码为
|
1
2
3
4
5
6
7
8
9
10
|
<!DOCTYPE HTML>
<
html
>
<
head
>
<
meta
charset
=
"utf-8"
/>
</
head
>
<
body
>
<
img
src
=
"frame.jpg"
/>
<
script
src
=
"frame.js"
></
script
>
</
body
>
</
html
>
|
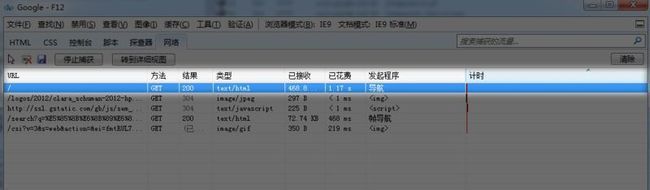
一.IE 9
序号1-6的请求为F5的操作,序号7-12的请求为CTRL+F5的操作.可见,在IE下,使用CTRL+F5能让主页面和框架页面的所有资源文件都跳过缓存.
二.Firefox 18

序号1-6的请求为F5的操作,序号7-9的请求为CTRL+F5的操作.可见,在Firefox下,使用CTRL+F5只能让主页面及其资源文件跳过缓存,而框架页面及其资源文件完全"无请求读取缓存".
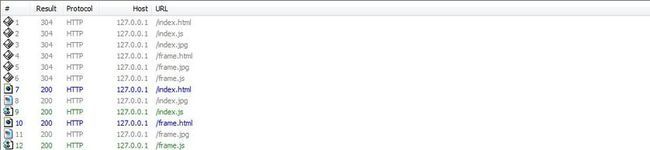
三.chrome 22
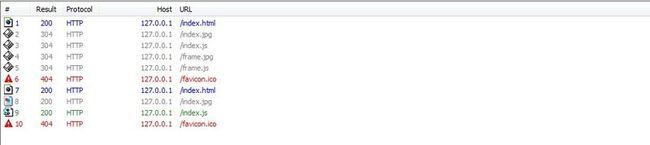
序号1-5的请求为F5的操作,序号7-9的请求为CTRL+F5的操作.可见,在Chrome下,和Firefox类似,使用CTRL+F5只能 让主页面及其资源文件跳过缓存,而框架页面及其资源文件完全"无请求读取缓存".诡异的是,如果在当前页面按过一次CTRL+F5,则每次在该页面按下 F5的时候,主页面的HTTP请求中都会加入一个Pragma: no-cache请求头,也就是说,浏览器会记忆.序号1的请求就是这种情况.更诡异的是,F5操作下,frame.html始终是"无请求读取缓存", 这和其他浏览器表现不一样.更麻烦的是,chrome不能用右键把框架页面提出来.
四.Opera 12.50
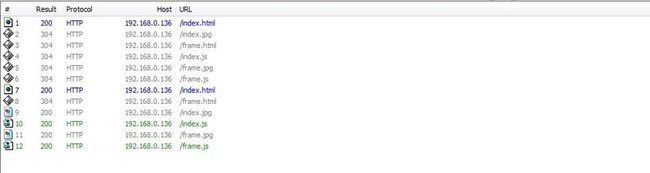
序号1-6的请求为F5的操作,序号7-12的请求为CTRL+F5的操作.可见,在Opera下,表现更加不一样.即使只按F5,主页面的请求 (序号1)也有Pragma: no-cache请求头,CTRL+F5下,除了框架页面本身(序号8),所有的资源文件都跳过了缓存.这一点比较接近IE
五.Safari

序号1-5的请求为F5的操作,Safari不支持CTRL+F5.和Opera类似.F5会让主页面的请求(序号1)中包含Pragma: no-cache请求头.既然不支持跳过缓存,那么不管是不是框架页面,在Safari中只能点菜单清除缓存了.
解决办法
根据以上对比可以看出,只有IE浏览器的表现是我们想要的.这里给出Firefox下的解决办法.
1.安装扩展http://files.cnblogs.com/ziyunfei/ReloadPassCache.xpi
2.安装UC脚本http://files.cnblogs.com/ziyunfei/ReloadPassCache.uc.js
UC脚本是专业的火狐玩家使用的,这里顺便讲一下我是如何实现这个功能的.有兴趣玩火狐脚本的可以看一下.实在看不懂可以跳过.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
//在浏览器主窗口绑定keydown事件
location ==
"chrome://browser/content/browser.xul"
&& addEventListener(
"keydown"
,
function
(event) {
//如果按下了CTRL+F5
if
(event.which === 116 && event.ctrlKey) {
//阻止冒泡和默认操作,主要是阻止默认的刷新动作.否则会刷两次
event.preventDefault();
event.stopPropagation();
(
function
(content) {
//为当前标签绑上DOMContentLoaded事件,在主页面DOM加载完成后,刷新各个框架
gBrowser.mCurrentBrowser.addEventListener(
"DOMContentLoaded"
,
function
self() {
//解绑DOMContentLoaded事件
this
.removeEventListener(
"DOMContentLoaded"
, self,
false
);
//遍历刷新所有框架
Array.prototype.slice.call(content.frames).forEach(
function
(win) {
//跳过缓存刷新
win.location.reload(
true
);
})
},
false
);
//开始刷新主页面
content.location.reload(
true
);
})(content)
}
//捕获模式,第一时间触发事件处理函数.
},
true
)
|
安装该扩展后,按下CTRL+F5能像IE一样,让所有的框架页面全都跳过缓存刷新.至于多层框架(框架中的框架),这个扩展不适用,我觉的各位程序员不会那么倒霉.