http://www.infoq.com/articles/kiji
Today, recommendations are everywhere online. Major e-commerce websites like Amazon provide product recommendations in many different forms across their web properties. Financial planning sites like Mint.com provide recommendations for things like credit cards that a user might want to sign up for or banks that can offer better interest rates. Google augments search results based on its knowledge of the users’ past searches to find the most relevant results.
These brands use recommendations to provide contextual, relevant user experience in order to increase conversion rates and user satisfaction. Traditionally, these sorts of recommendations have been computed by batch processes that generate new recommendations on a nightly, weekly or even monthly basis.
However, for certain types of recommendations, it’s necessary to react in a much shorter timeframe than batch processing allows, such as offering a consumer a geo-location-based recommendation. Consider a movie recommendation system -- If a user historically watches action movies, but is currently searching for a comedy, batch recommendations will likely result in recommendations for more action movies instead of the most relevant comedy. In this article, you will learn how to use the Kiji framework, an open source framework for building Big Data Applications, to build a system that provides real-time recommendations.
Kiji, Entity-Centric Data, and the 360º View
To build a real-time recommendation system, we first need a system that can be used to store a 360º view of our customers. Moreover, we need to be able to retrieve data about a particular customer quickly in order to produce recommendations as they interact with our website or mobile app. Kiji is an open-source, modular framework for building real-time applications that collect, store and analyze this sort of data.
More generally, the data necessary for a 360º view can be termed entity-centric data. An entity could be any number of things such as a customer, user, account, or something more abstract like a point-of-sale system or a mobile device.
The goal of an entity-centric storage system is to be able to store everything about a particular entity in a single row. This is challenging with traditional, relational databases because the information may be both stateful data (like name, email address, etc.) and event streams (like clicks). A traditional system requires storing this data in multiple tables, which get joined together at processing time, which makes it harder to do real-time processing. To deal with this challenge, Kiji leverages Apache HBase, which stores data in four dimensions -- row, column family, column qualifier, and timestamp. By leveraging the timestamp dimension, and the ability of HBase to store multiple versions of a cell, Kiji is able to store event-stream data alongside the more stateful, slowly-changing data.

HBase is a key-value store built on top of HDFS and used by Apache Hadoop, which provides the scalability that is necessary for a Big Data solution. A large challenge with developing applications on HBase is that it requires that all the data going in and out of the system be byte arrays. To deal with this, the final core component of Kiji is Apache Avro, which is used by Kiji to store easily-processed data types like standard strings and integers, as well as more complex user-defined data types. Kiji handles any necessary serialization and deserialization for the application when reading or writing data.
Developing Models for Use in Real Time
Kiji provides two APIs for developing models, in Java or Scala, both of which have a batch and a real-time component. The purpose of this split is to break down a model into distinct phases of model execution. The batch phase is a training phase, which is typically a learning process, in which the model is trained over a dataset for the entire population. The output of this phase might be things like parameters for a linear classifier or locations of clusters for a clustering algorithm or a similarity matrix for relating items to one another in a collaborative filtering system. The real-time phase is known as the scoring phase, and takes the trained model and combines it with an entity’s data to produce derived information. Critically, this derived data is considered first-class, in that it can be stored back in the entity’s row for use in serving recommendations or for use as input in later computations.
The Java APIs are called KijiMR, and the Scala APIs form the core of a tool called KijiExpress. KijiExpress leverages the Scalding library to provide APIs for building complex MapReduce workflows, while avoiding a significant amount of boilerplate code typically associated with Java, as well as the job scheduling and coordination that is necessary for stringing together MapReduce jobs.
Individuals Versus Populations
The reason for the differentiation between batch training and real-time scoring is that Kiji makes the observation that population trends change slowly, while individual trends change quickly.
Consider a dataset for a user population that contains ten million purchases. One more purchase is not likely to dramatically affect trends for the population and their likes or dislikes. However, if a particular user has only ever made ten purchases, the eleventh purchase will have a huge affect on what a system can determine that the user is interested in. Given this assertion, an application will only need to retrain its model once enough data has been gathered to affect the population trends. However, we can improve recommendation relevancy for an individual user by reacting to their behavior in real time.
Scoring Against a Model in Real Time
In order to score in real time, the KijiScoring module provides a lazy computation system that allows an application to generate refreshed recommendations only for users that are actively interacting with the application. Through lazy computation, Kiji applications can avoid generating recommendations for users that don’t frequently or may never return for a second visit. This also has the added benefit that Kiji can take into account contextual information like the location of their mobile device at the time of the recommendation.
The primary component in KijiScoring is called a Freshener. Fresheners are really a combination of a couple of other Kiji components: ScoringFunctions and FreshnessPolicies. As mentioned earlier, a model will consist of both a training and a scoring phase. The ScoringFunction is the piece of code that describes how a trained model and a single entity’s data are combined to produce a score or recommendations. A FreshnessPolicy defines when data becomes stale or out-of-date. For example, a common FreshnessPolicy will say that data is out-of-date when it is older than an hour or so. A more complex policy might mark data as out-of-date once an entity has experienced some number of events, like clicks or product views. Finally, the ScoringFunction and FreshnessPolicy are attached to a particular column in a Kiji table which will trigger a refresh of the data, if necessary.
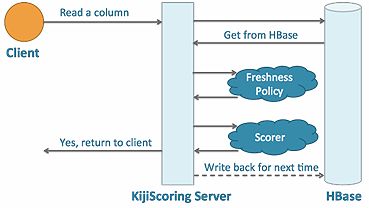
Applications that do real-time scoring will include a tier of servers called KijiScoring servers, which fill the role of an execution layer for refreshing stale data. When a user interacts with the application, the request will be passed to the KijiScoring server tier, which communicates directly with the HBase cluster. The KijiScoring server will request the data, and once retrieved, determine whether or not the data is up-to-date, according to the FreshnessPolicy. If the data is up-to-date, it can just be returned to the client. However, if the data comes back stale, the KijiScoring server will run the specified ScoringFunction for the user that made the request. The important piece to understand is that the data or recommendations that are being refreshed are only being refreshed for the user that is making the request, rather than a batch operation, which would refresh the data for all users. This is how Kiji avoids doing more work than is necessary. Once the data is refreshed, it’s returned to the user, and written back to HBase for use later on.
A typical Kiji application will include some number of KijiScoring servers, which are stateless Java processes that can be scaled out, and that are able to run a ScoringFunction using a single entity’s data as input. A Kiji application will funnel client requests through the KijiScoring server, which determines whether or not data is fresh. If necessary, it will run a ScoringFunction to refresh any recommendations before they are passed back to the client, and write the recomputed data back to HBase for later use.
Deploying Models to a Production System
A major goal in a real-time recommendation system is to be able to iterate on the underlying predictive models easily, and avoid application downtime to push new or improved models into production. To do that, Kiji provides the Kiji Model Repository, which combines metadata about how the models execute with the code that is used to train and score the models. The KijiScoring server needs to know what column accesses should trigger freshening, the FreshnessPolicy to be applied, and the ScoringFunction that will be executed against user data, as well as the locations of any trained models or external data necessary for scoring against the model. This metadata is stored in a Kiji system table, which is just another HBase table at the lowest level. Additionally, the Model Repository stores code artifacts for registered models in a managed Maven repository. The KijiScoring server periodically polls the Model Repository for newly-registered or -unregistered models, and loads or unloads code as necessary.
Putting It All Together
A very common way to provide recommendations is through the use of collaborative filtering. Collaborative filtering algorithms typically involve building a large similarity matrix to store information relating to a product to other products in the product catalog. Each row in the matrix represents a product pi, and each column represents another product pj. The value at (pi, pj) is the similarity between the two products.
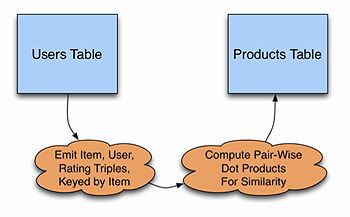
In Kiji, the similarity matrix is computed via a batch training process, and then can be stored in a file or a Kiji table. Each row of the similarity matrix would be stored in a single row in the product table in Kiji in its own column. In practice, this column has the potential to be very large, since it would be a list of all the products in the catalog and similarities. Typically, the batch job will also do the work of picking only the most similar items to put into the table.
This similarity matrix is accessed at scoring time through the KeyValueStore API, which gives processes access to external data. For matrices that are too large to store in memory, storing the matrix in a distributed table enables the application to only request the data that is necessary for the computation, and dramatically reduce the memory requirements.
Since we’ve done a lot of the heavy lifting ahead of the scoring phase, scoring becomes a fairly simple operation. If we wanted to display recommendations based on an item that was viewed, a non-personalized scoring function would just look up the related products from the product table and display those.
It’s a relatively simple task to take this process a little further and personalize the results. In a personalized system, the scoring function would take a user’s recent ratings and use the KeyValueStore API to find products similar to the products that the user had rated. By combining the ratings and the product similarities stored in the products table, the application can predict the ratings that the user would give related items and offer recommendations of the products with the highest predicted ratings. By limiting both the number of ratings used and the number of similar products per rated product, the system can easily handle this operation as the user is interacting with the application.
Conclusion
In this article, we’ve seen, at a high level, how Kiji can be used to develop a recommendation system that refreshes recommendations in real time. By leveraging HBase to do low latency processing, using Avro to store complex data types, and processing data using MapReduce and Scalding, applications can provide relevant recommendations to users in a real-time context. For those who are interested in seeing an example of this system, there is code for a very similar application located on the WibiData Github.