讲解提纲
Hadoop框架
Hadoop周边框架
Hadoop框架
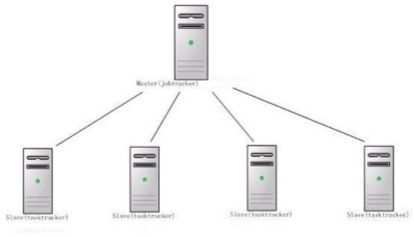
Master
同时是NameNode,在runtime时会生成JobTracker
Slave
同时是DataNode,在runtime时会生成TaskerTracker
Master与Slave之间通过RPC互相通讯,没隔一定时间进行一次心跳,如果某一个salve在定期时间没有发回心跳,则认为没有存活,进行相应处理
Hadoop 特点
提供高性能运算和分布式文件体统
如何提供高性能运算?
生成Map-Reduce程序
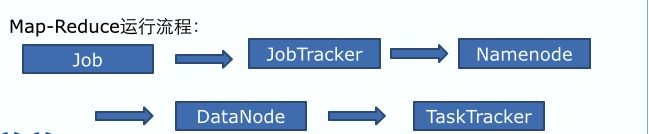
1 客户端提交任务给JobTracker
2 JobTracker与NameNode交谈确定data所在的位置
3 JobTracker确定与data最近的位置的服务器生成TaskTracker
4 JobTracker把任务Task分配给TaskTracker执行计算任务
在TaskTracker执行任务期间会被监视, TaskTracker定时向JobTracker发送心跳,如果没有发送心跳,则会把任务分配给其它TaskTracker,甚至会把宕掉的TaskTracker拉入黑名单。如果执行完毕, JobTracker会更新status,把数据给客户端
分布式文件系统
结构图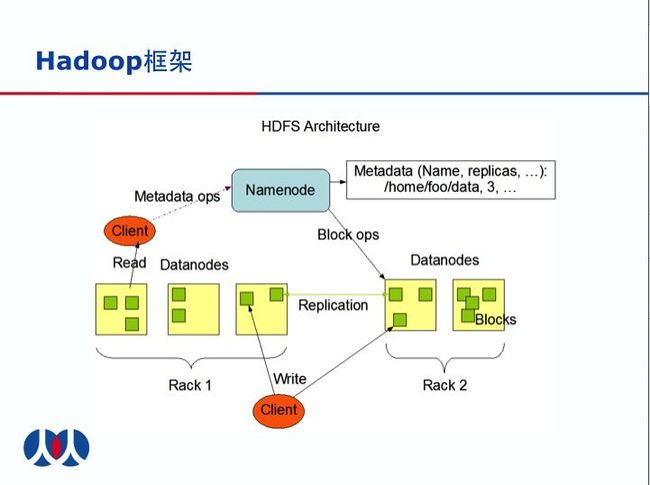
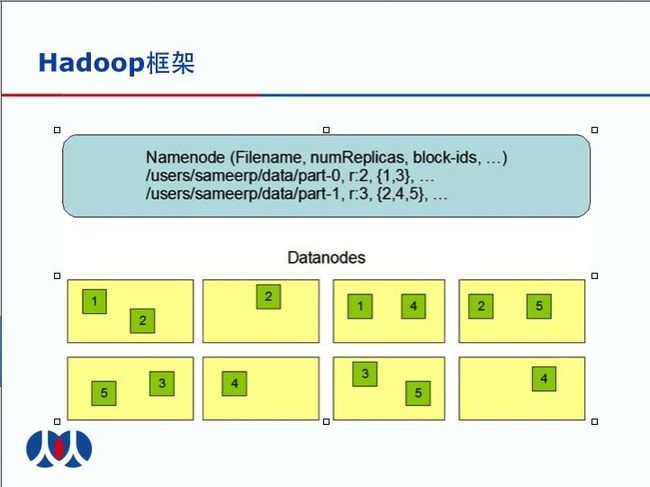
HDFS 是 master/slave 结构的. 一个 HDFS 集群 只有一个NameNode, master 管理着分布式文件系统的命名空间和访问规则。一个NameNode 有很多个DataNodes,目前是一个 Cluster可以有2000个左右的DataNode。
一个文件会给分拆成很多 个block,每个block会被replicated到不同的server上,可以用replicationnumber来配置复制的个数,一般来讲是3个
Hadoop周边框架——Hive
HIVE是什么
hive是一个基于hadoop的数据仓库。使用hadoop-hdfs作为数据存储层;提供类似SQL的语言(HQL),通过hadoop-mapreduce完成数据计算;通过HQL语言提供使用者部分传统RDBMS一样的表格查询特性和分布式存储计算特性。
类似的系统有yahoo的pig,google的sawzall,microsoft的DryadLINQ。


操作界面:CLI,Web,Thrift
driver:hive系统将用户操作转化为mapreduce计算的模块(重点)
hadoop:hdfs+mapreduce
metastore:存储元数据(可以用mysql,默认是内存数据库Derby)
CLI(shell)
类似于mysql启动客户端后的执行命令

语言
一般有DDL和DML两种:hive采用DDL方式和少量DML方式,类似sql;
DDL:data definition language(数据定义语言)
{create/alter/drop}{table/view/partition}
例如:
CREATE TABLE logtest1 (timeField STRING, url STRING) PARTITIONED BY (dateField STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|';
CREATE EXTERNAL TABLE log_test(timeField string, url string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' LOCATION '/log_sunlonghai/test';
和hbase结合的例句:
CREATE TABLE hbase_table_1(key int, value string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val")
TBLPROPERTIES ("hbase.table.name" = "xyz");
DML:data manipulation language(数据操作语言)
Select * from tablename
例如:
select * from pokes;
会把DML语句转换成hadoop的mapreduce程序,进行计算
Hive 加载数据
LOAD DATA LOCAL INPATH '/opt/hive-0.9.0/examples/files/kv1.txt' OVERWRITE INTO TABLE pokes;
把数据从指定文件夹下加载到数据库表,但是不检查文件格式,当进行运算的时候才会检查文件格式