一、Java中文乱码原因
java在中文环境中乱码无处不在,而且出现的时间和位置也包涵广泛,具体的解决方法也是千奇百怪。但是如果能理清其中的脉络,理解字符处 理的过程,对于解决问题很有指导意义,不至于解决了问题也不知道为什么。 其实,原因不外乎出在String输入时和输出时。
首先,Java中的任何String都是以UNICODE格式存在的。
很多人因为在GBK环境中使用String,会误以为String是GBK格式,实际上Java的String类中并没有存储CharSet信息的字段, 所有String中的字符只会以UNICODE的2字节形式存在。
String在构造时会逐一把字符按指定编码(默认值为系统编码GBK),转换为UNICODE字符,存入一个Char(无符号16位)数组中。
并不是说,生成一个GBK编码的字符串,而是按GBK逐一辨认字节数组bytes中的字符转化为UNICODE。
假设,bytes本是按GB编码的,构造方法在发现一个最高位为0的byte就作为ascii字符处理,最高位为1就和后面的一个byte合成中文字符, 再转换编码。
可以看出,在这个过程中,编码选择错误就会导致程序按错误方法辨认bytes,乱码就出现了。
在这里产生的乱码,很多时候还可以通过.getByte()方法修复,还没有后面的严重。 如:
"中".getBytes("iso-8859-1");
因为iso-8859-1中没有中文,所以"中"的值被替换成63,显示'?',无法判断以前是什么值。
所以如下String将被破坏掉:
new String("中文".getBytes("iso-8859-1"),"iso-8859-1");
如果目标编码方式支持中文,就不会损坏String:
new String("中文".getBytes("utf-8"),"utf-8");
Java在显示字符时,还需要进行一次转换,把UNICODE字符转换成用于显示的字符编码形式。很多时候,这个过程是自动的,会按系统的默认编码(一般是GBK)转换String。 如果和页面编码不一样,就会出现乱码,虽然在Java的程序中只有一种编码,输出却可以有不同的编码。
有时候,我们需要用 iso-8859-1格式分解String的中文,以便在不支持中文的系统中存储:
new String("中文".getBytes("GBK"),"iso-8859-1");
先通过GBK等支持中文的编码方式分解为byte数组,再做为iso-8859-1字符组成字符串,就避免了被替换为Char(63)。
示例程序 :
public static void main(String[] args) {
String str = "中国";
printBytes("中国的UNICODE编码:",str.getBytes(Charset.forName("unicode")));
printBytes("中国的GBK编码:", str.getBytes(Charset.forName("GBK")));
printBytes("中国的UTF-8编码:", str.getBytes(Charset.forName("UTF-8")));
}
public static void printBytes(String title, byte[] data) {
System.out.println(title);
for (byte b : data) {
System.out.print("0x" + toHexString(b) + " ");
}
System.out.println();
}
public static String toHexString(byte value) {
String tmp = Integer.toHexString(value & 0xFF);
if (tmp.length() == 1) {
tmp = "0" + tmp;
}
return tmp.toUpperCase();
}
上例的输出结果为:
中国的UNICODE编码:0xFE 0xFF 0x4E 0x2D 0x56 0xFD
中国的GBK编码: 0xD6 0xD0 0xB9 0xFA
中国的UTF-8编码:0xE4 0xB8 0xAD 0xE5 0x9B 0xBD
二、JSP中文乱码问题有如下几个方面:页面乱码、参数乱码、表单乱码、源文件乱码。下面来逐一解决其中的乱码问题。
(一)JSP页面中文乱码
在JSP页面中,中文显示乱码有两种情况:一种是HTML中的中文乱码,另一种是在JSP中动态输出的中文乱码。
先看一个JSP程序:
<%@ page language="java" import="java.util.*" %>
<html>
<head>
<title>中文显示示例</title>
</head>
<body>
这是一个中文显示示例:
<%
String str = "中文";
out.print(str);
%>
</body>
</html>
上面这个JSP程序看起来好像是在页面显示几句中文而且标题也是中文。运行后在浏览器中显示如图所示

原因在于没有在JSP中指定页面显示的编码,消除乱码的解决方案很简单上面代码中page命令修改成如下所示即可:
<%@ page language="java" import="java.util.*" contentType="text/html; charset=GB2312" %>
<html>
<head>
<title>中文显示示例</title>
</head>
<body>
这是一个中文显示示例:
<%
String str = "中文";
out.print(str);
%>
</body>
</html>
再次运行乱码消失,原理就是向页面指定编码为GB2312,那么页面就会按照此编码来显示,于是乱码消失。
(二)URL传递参数中文乱码
一般情况下在使用get方法提交表单的时候传递的参数如果是中文的话很可能会出现乱码。下面是一个示例程序:
<%@ page language="java" import="java.util.*" contentType="text/html;charset=gb2312"%>
<html>
<head>
<title>URL传递参数中文处理示例</title>
</head>
<%
String param = request.getParameter("param");
%>
<body>
<a href="URLCharset.jsp?param='中文'">请点击这个链接</a><br>
你提交的参数为:<%=param%>
</body>
</html>
上面这个JSP程序的功能就是通过一个URL链接向自身传递一个参数,这个参数是中文字符串,这个程序的运行效果如下图
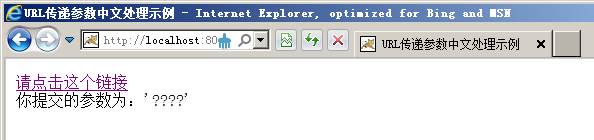
对于URL传递中文参数乱码这个问题,其处理方法比较特殊,仅仅转换这个中文字符串或者设置JSP页面显示编码都是不能解决问题的,需要修改Tomcat服务器的配置文件才能解决问题。在这里修改Tomcat的conf目录下的server.xml配置文件,具体改后的代码如下:
<Connector port="8080" protocol="HTTP/1.1" URIEncoding="gb2312"
connectionTimeout="20000"
redirectPort="8443" />
在原来代码中添加URI编码设置URIEncoding=“gb2312”即可,重启Tomcat服务器可以得到正确的页面。其原理也和上面的情况类似,就是向程序指明编码类型,然后显示就正常了。
(三)表单提交中文乱码
对于表单的数据可以使用request.getParameter(“”)的方法获取,但是当表单中出现中文数据的时候就会出现乱码。示例代码如下:
<%@ page language="java" import="java.util.*" contentType="text/html;charset=gb2312"%>
<html>
<head>
<title>Form中文处理示例</title>
</head>
<body>
<font size="2">
下面是表单内容:
<form action="AcceptFormCharset.jsp" method="post">
用户名:<input type="text" name="userName" size="10"/>
密 码:<input type="password" name="password" size="10"/>
<input type="submit" value="提交">
</form>
</font>
</body>
</html>
在上面的表单当中想AcceptFormCharset这个页面提价两项数据,下面是AcceptFormCharset.jsp的内容:
<%@ page language="java" import="java.util.*"
contentType="text/html;charset=gb2312"%>
<html>
<head>
<title>Form中文乱码</title>
</head>
<body>
<font size="2"> 下面是表单提交以后用request取到的表单数据:<br>
<%
String userName = request.getParameter("userName");
String password = request.getParameter("password");
out.println("表单输入userName的值:" + userName + "<br>");
out.println("表单输入password的值:" + password + "<br>");
%>
</font>
</body>
</html>
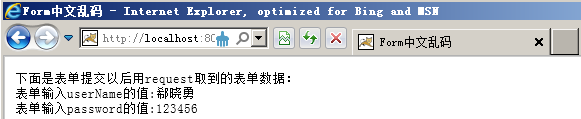
在上面的程序中,如果表单输入没有中文,则可以正常的显示当输入的数据中有中文的时候,得到的结果如图所示。

产生种结果的原因是Tomcat中对于post方法提交的表单采用的默认编码为ISO-8859-1,而这种编码格式不支持中文字符。对于这个问题可以采用转换编码格式的方法来解决,现在对AcceptFromCharset这个页面改动如下:
<%@ page language="java" import="java.util.*"
contentType="text/html;charset=gb2312"%>
<html>
<head>
<title>Form中文乱码</title>
</head>
<body>
<font size="2"> 下面是表单提交以后用request取到的表单数据:<br>
<%
String userName = request.getParameter("userName");
String password = request.getParameter("password");
out.println("表单输入userName的值:" + new String(userName.getBytes("ISO-8859-1"), "gb2312")+ "<br>");
out.println("表单输入password的值:" + new String(password.getBytes("ISO-8859-1"), "gb2312")+ "<br>");
%>
</font>
</body>
</html>
经过这样的转换编码以后,所有的中文输入都可以用request对象正常取出。在上面这个程序中,第四行和第五行是转换编码格式的关键,先从ISO-8859-1格式的字符串中取出字节内容,然后在用GB2312的编码格式重新构造一个新的字符串。这样就可以支持中文变淡输入的正常取值和显示。改进以后程序运行结果如下
经过上面的更改编码格式的处理,表单的中文输入乱码问题已经得到解决。但是如果上面的表单中的输入项不止是两个,那么每个输入项都需要进行编码转换,那样就很麻烦了。这是我们就用到了大名鼎鼎的过滤器filter了。
(四)Eclipse中JSP文件中文乱码
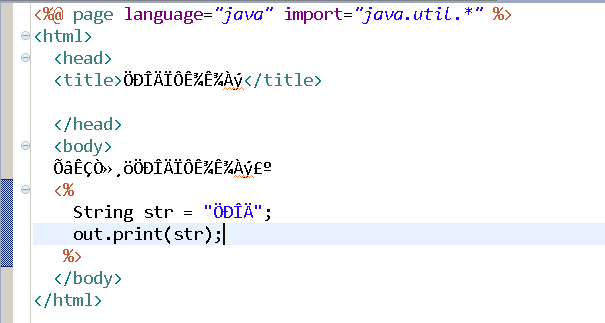
在Eclipse或者MyEclipse中由于默认的JSP编码格式为ISO-8859-1,所以当打开由其他编辑器编辑的JSP文件时会出现乱码,如图所示
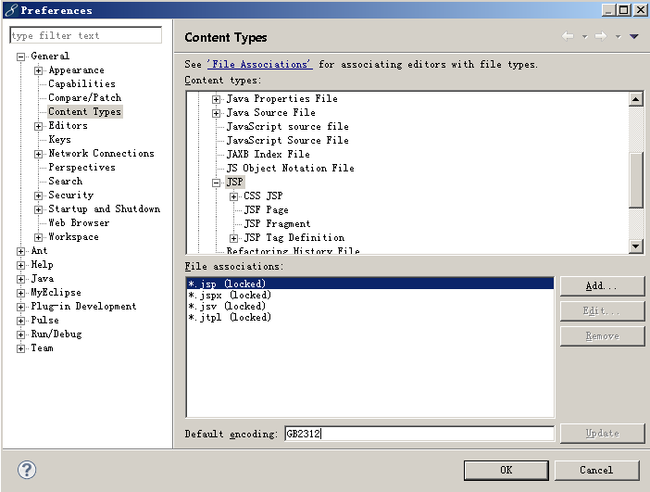
对于这个问题我们只需要更改一下Eclipse或者是MyEclipse中对JSP的默认编码就可以了,修改的地方(我的MyEclipse版本为11)如图所示
在Eclipse或者MyEclipse当中JSP文件默认的编码为ISO-8859-1,所以在JSP代码中间如果出现中文就不能保存,例如如下代码:
<%@ page language="java" import="java.util.*" %>
<html>
<head>
<title>中文显示示例</title>
</head>
<body>
这是一个中文显示示例:
<%
String str = "中文";
out.print(str);
%>
</body>
</html>
修改后在保存的时候会提示如下:
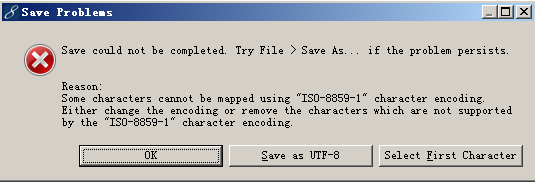
现这个提示的原因在于JSP源文件中有ISO=8859-1编码无法识别的中文字符,对于这个问题,解决办法就是在JSP页面中声明页面编码格式即可。声明后代码如下:
<%@ page language="java" import="java.util.*" pageEncoding="GB2312" %>
<html>
<head>
<title>中文显示示例</title>
</head>
<body>
这是一个中文显示示例:
<%
String str = "中文";
out.print(str);
%>
</body>
</html>
其中第一行中pageEncoding=“gb2312”指明了JSP页面编码采用GB2312,这样就可以正常保存JSP的源文件了。