我也造了个轮子:BeanMapping(属性拷贝)
背景
最近公司在大力推进服务化平台,我在中间主要做一个orm框架,解决model和数据源之间的映射问题。这里不选择已有的hibrenate,主要考虑自己公司的一些特殊场景:比如多数据源(数据库,搜索引擎,memcached,nosql等),同时可以 做一些特殊优化,比如多数据源加载时采用并行加载(我之间做的一个工具包 (业务层)异步并行加载技术分析和设计)
也不多罗嗦,我主要负责从多个数据源搜集回来的数据,构造成对应的model对象。可以看一下具体的分析过程。
分析
每个数据源采集回来的数据可能比较凌乱,有map对象,POJO对象,至于这个映射过程。因为是在老系统上实施,以前都没有service的概念,在数据库的设计会很比较乱,都是来一个需求加几个字段的那一类型。 所以具体data -> model对象的映射过程,就需要额外考虑一些特殊功能。
需求整理:
- 处理的data是个map对象
- 处理的data是个pojo bean
- 映射过程中,处理的data属性名和目标对象model的属性会大不相同
- 映射过程中,data中的数据大多都是文本型,而对应的model会是根据业务场景定义的强类型,需要有类型转化
- 对应的data可能是一个平面型的map/bean对象,需要转化有层次结构,带立体的模型。比如model里包含一些子model等
- 需要处理特殊情况,比如data中有个属性是个json格式数据,需要在解析后再转化到某几个model属性上
设计
根据上面的需求分析,因为要解决不同属性名自己的映射关系,单纯的依赖bean属性的扫描无法满足。所以需要引入配置文件,定义mapping的映射关系。
整体设计示意图:
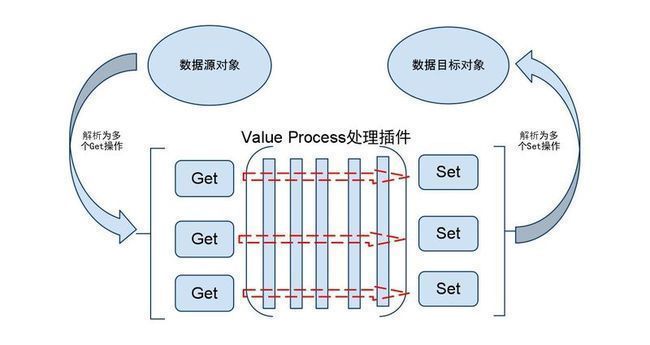
说明:
- 将属性mapping的动作抽象成Get / Set两个操作。 Get操作针对数据源对象,Set操作针对数据目标对象
- 在Get/Set中间,定义了一个ValueProcess处理插件的概念,允许扩展相关的功能插件 (自认为相比于BeanUtils/BeanCopier的非常好的亮点,扩展性良好)
1. 比如默认值
2. 类型转化器
3. json数据处理
4. 日志记录
对应的类关系图:
Get/Set操作类
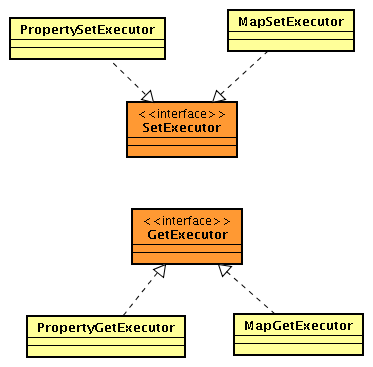
ValueProcess设计类:
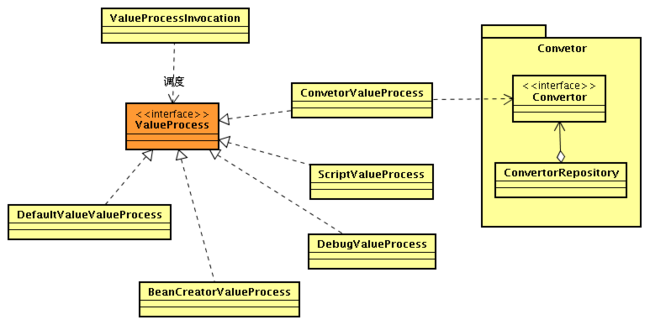
客户端使用类设计:
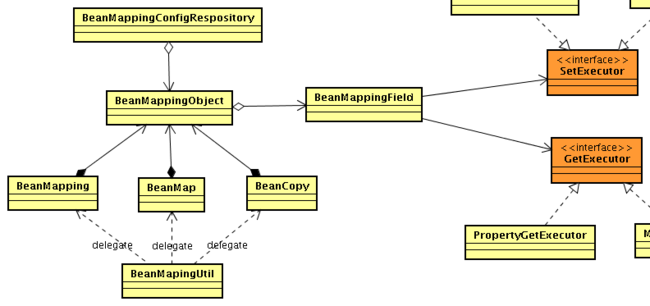
- BeanMapping : 本轮子的核心功能,通过基于配置方式的mapping映射,支持convetor,defaultValue,script的所有功能。要求使用之前必须提前配置bean-mapping映射。
- BeanCopy 和 BeanMap : 都是一些扩展功能,基于本轮子的核心架构不变的基础上,开发了BeanUtils.copyProperties() , BeanUtils.describe, BeanUtils.populate()的功能。 使用该api,可以不需要配置映射文件,会进行自动扫描,就是基于同名属性的处理前提。
- BeanMappingUtil : 提供了BeanMapping , BeanCopy , BeanMap的所有方法,提供静态的util方法处理。每次都会构造对应的BeanMapping等对象,注意:每次进行构造BeanCopy,BeanMap,解析的属性结果会有cache。所以使用该util不会有很明显的性能下降,无非就是多一些临时对象。
最后定义的配置文件示例: mapping.xml
<bean-mappings xmlns="http://mapping4java.googlecode.com/schema/mapping" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://mapping4java.googlecode.com/schema/mapping http://mapping4java.googlecode.com/svn/trunk/src/main/resources/META-INF/mapping.xsd">
<!-- (bean-bean) mapping 测试 -->
<bean-mapping batch="true" srcClass="com.agapple.mapping.object.SrcMappingObject" targetClass="com.agapple.mapping.object.TargetMappingObject" reversable="true">
<field-mapping srcName="intValue" targetName="intValue" />
<field-mapping targetName="integerValue" script="src.intValue + src.integerValue" /> <!-- 测试script -->
<field-mapping srcName="start" targetName="start" />
<field-mapping srcName="name" targetName="targetName" /> <!-- 注意不同名 -->
<field-mapping srcName="mapping" targetName="mapping" mapping="true" />
</bean-mapping>
<bean-mapping batch="true" srcClass="com.agapple.mapping.object.NestedSrcMappingObject" targetClass="com.agapple.mapping.object.NestedTargetMappingObject" reversable="true">
<field-mapping srcName="name" targetName="name" defaultValue="ljh" /> <!-- 测试default value -->
<field-mapping srcName="bigDecimalValue" targetName="value" targetClass="string" defaultValue="10" /> <!-- 测试不同名+不同类型+default value -->
</bean-mapping>
</bean-mappings>
说明:
- bean-mappings : 可以指定xsd,方便编写配置文件。通过IDE可以给于提示
- bean-mapping : 定义需要进行mapping映射的对象信息,需要指定class全路径
reversable主要表明此mapping动作是可逆的,默认为true。 batch主要是一优化特性,后面再细表。 - field-mapping : 主要定义需要进行映射的属性之间的映射关闭 srcName : 源对象的属性名 srcClass : 源对象的class类型 targetName : 目标对象的属性名 targetClass : 目标对象的class类型 mapping : 表明是否需要进行递归映射,比如这里的,在处理NestedSrcMappingObject和NestedTargetMappingObject时,会递归进行映射处理 defaultValue : 很好理解,就是针对源属性为null时,默认值处理 convetor : 自定义类型转化器 (默认支持基本类型,BigDecimal,BigInteger,Array,List之间的转化处理) script : 高级特性,支持自定义的映射规则,比如这里进行一个+运算。
targetName="integerValue" script="src.intValue + src.integerValue"
几点说明:
- srcClass/targetClass: 默认可不关注,系统会自动进行识别,在defaultValue和convetor转化处理。 还有一点:如果对象中出现同名的属性时,可以指定targetClass进行唯一定位
- defaultValue : 相比于BeanCopier和BeanUtils,一个特有的特性。 大家熟悉ibatis的配置就知道会有一个nullvalue配置,主要是方便客户端处理,避免进行一些无谓的==null/==0这样的处理
- convetor : 相比于BeanUtils, 这里允许声明属性之间的转化类,比如你注册了一个alias别名的convetor,就可以在这里声明进行使用,会优先使用你定义的(如果不指定,则会进行自动根据类型进行匹配)。
自动处理会有个局限性,就是convetor会是全局性。比如你定义了一个String到Date的处理,以后整个jvm中所有的场景都会按照你定义的进行转化,到时候你怎么死自己都不知道 - script: 系统的高级特性,做为系统的一些扩展点,可以支持一些比较复杂的处理,比如以后的json/xml等处理,只需注册你的functions。比如这里定义: script="src.intValue + src.integerValue"。
BeanMapping列子: BeanMappingTest.java
public BeanMapping srcMapping = BeanMapping.create(SrcMappingObject.class, TargetMappingObject.class);
public BeanMapping targetMapping = BeanMapping.create(TargetMappingObject.class , SrcMappingObject.class);
@Test
public void testBeanToBean_ok() {
SrcMappingObject srcRef = new SrcMappingObject();
srcRef.setIntegerValue(1);
srcRef.setIntValue(1);
srcRef.setName("ljh");
srcRef.setStart(true);
TargetMappingObject targetRef = new TargetMappingObject();// 测试一下mapping到一个Object对象
srcMapping.mapping(srcRef, targetRef);
SrcMappingObject newSrcRef = new SrcMappingObject();// 反过来再mapping一次
targetMapping.mapping(targetRef, newSrcRef);
}
BeanCopy例子: (发觉和BeanCopier使用比较像) BeanCopyTest.java
public BeanCopy srcCopyer = BeanCopy.create(SrcMappingObject.class, TargetMappingObject.class);
public BeanCopy targetCopyer = BeanCopy.create(TargetMappingObject.class , SrcMappingObject.class);
@Test
public void testCopy_ok() {
SrcMappingObject srcRef = new SrcMappingObject();
srcRef.setIntegerValue(1);
srcRef.setIntValue(1);
srcRef.setName("ljh");
srcRef.setStart(true);
TargetMappingObject targetRef = new TargetMappingObject();// 测试一下mapping到一个Object对象
srcCopyer.copy(srcRef, targetRef);
SrcMappingObject newSrcRef = new SrcMappingObject();// 反过来再mapping一次
targetCopyer.copy(targetRef, newSrcRef);
}
BeanMap例子: (支持bean<->map的转化处理) BeanMapTest.java
public BeanMap beanMap = BeanMap.create(SrcMappingObject.class);
@Test
public void testDescribe_Populate_ok() {
SrcMappingObject srcRef = new SrcMappingObject();
srcRef.setIntegerValue(1);
srcRef.setIntValue(1);
srcRef.setName("ljh");
srcRef.setStart(true);
NestedSrcMappingObject nestedSrcRef = new NestedSrcMappingObject();
nestedSrcRef.setBigDecimalValue(BigDecimal.ONE);
srcRef.setMapping(nestedSrcRef);
Map map = beanMap.describe(srcRef);
SrcMappingObject newSrcRef = new SrcMappingObject();// 反过来再mapping一次
beanMap.populate(newSrcRef, map); // 从map属性设置到bean
}
性能测试数据
不过前面功能说的如何天花乱坠,整个工具的性能相比也是大家比较会关注的一个点。 我这里大致做了下测试:构造一个CopyBean,基本涵盖了普通类型,对象处理等,进行批量处理
CopyBean :
public class CopyBean {
private int intValue;
private boolean boolValue;
private float floatValue;
private double doubleValue;
private long longValue;
private char charValue;
private byte byteValue;
private short shortValue;
private Integer integerValue;
private Boolean boolObjValue;
private Float floatObjValue;
private Double doubleObjValue;
private Long longObjValue;
private Short shortObjValue;
private Byte byteObjValue;
private BigInteger bigIntegerValue;
private BigDecimal bigDecimalValue;
private String stringValue;
}
BeanCopy性能测试
对比的内容:
- BeanCopy.copy
- BeanCopy.simpleCopy (不做类型转化)
- Method.invoke
- FastMethod.invoke
- BulkBean
- BeanCopier
- HardCode (硬编码,直接手工挨个复制属性)
- PropertyUtils (不做类型转化)
- BeanUtils
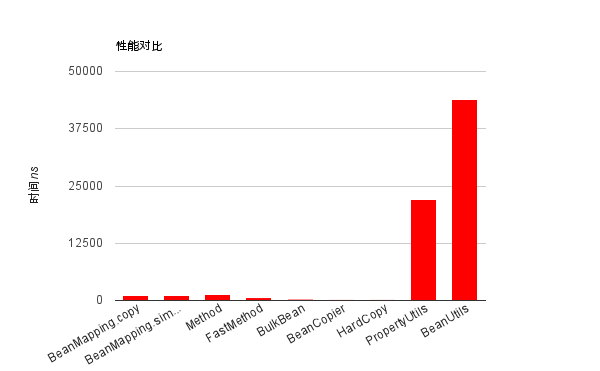
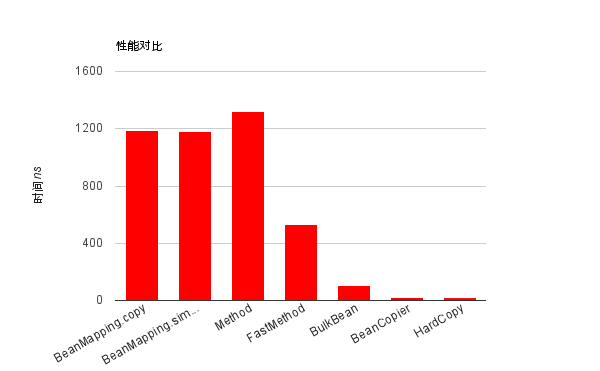
| 开启batch优化(200w次):单位ns | 纯解释执行(排除JIT优化)(10w次):单位ns | |
| BeanMapping.copy | 1189 | 72780 |
| BeanMapping.simpleCopy | 1178 | 69381 |
| Method | 1322 | 25882 |
| FastMethod | 533 | 15961 |
| BulkBean | 108 | 4420 |
| BeanCopier | 18 | 1566 |
| HardCopy | 17 | 1376 |
| PropertyUtils | 22143 | 1037770 |
| BeanUtils | 43980 | 1766392 |
- 首先注意一下,单位是ns。 1s = 1000ms = 1 * 10^9 ns
- BeanCopier和手工编码写的copy性能基本接近
- BeanMapping的copy和simpleCopy的区别,copy可以支持类型转化,simpleCopy不会处理类型转化。
- BeanMapping的性能是BeanUtils的近40倍左右,不过和BeanCopier还是有些差距,大概在50倍左右。 (换另一个概念,就是执行100w次,BeanCopier可以比BeanMapping节省1秒,可以比BeanUtils节省40多秒,比较直观吧)
最后
整个过程,完成功能代码大概只花了一周的时间,但是代码的重构/抽取,性能优化花了我近2周的时间。性能从最初的比BeanUtils慢,逐步的提升到了快几十倍,还是比较有成就感的。
还有一点,就是自己比较满意ValueProcess概念的设计,相比于BeanCopier或者BeanUtils扩展性好多了,比如自身系统的功能:日志记录,默认值,类型转化,script脚本(EL表达式)。都是通过扩展接口实现,也比较方便切换成不同的实现.。
有兴趣的同学,可以看下googlecode上的代码,有问题欢迎联系!
googlecode地址 : http://code.google.com/p/mapping4java
相关功能测试代码:
| BeanCopyTest.java | 3.1 KB |
| BeanMapTest.java | 2.1 KB |
| BeanMappingTest.java | 7.8 KB |
| ConfigTest.java | 1.7 KB |
| ConvertorTest.java | 8.5 KB |
| ScriptExecutorTest.java | 2.2 KB |
| ScriptTest.java | 2.7 KB |
性能测试代码:
| CopyPerformance.java | 12.9 KB |
| MapPerformance.java | 3.0 KB |
需求搜集
结合了dozer的一些特性,也顺便整理了一下自己的后续action的一些功能点,做了适当取舍。