CAVLC和CABAC简介
CABAC/CAVLCin H.264
什么是熵编码?
熵编码压缩是一种无损压缩,其实现原理是使用新的编码来表示输入的数据,从而达到压缩的效果。常用的熵编码有游程编码,哈夫曼编码和CAVLC编码等。
CAVLC
CAVLC(Context Adaptive VariableLength Coding)是在H.264/MPEG-4AVC中使用的熵编码方式。在H.264中,CAVLC以zig-zag顺序用于对变换后的残差块进行编码。CAVLC是CABAC的替代品,虽然其压缩效率不如CABAC,但CAVLC实现简单,并且在所有的H.264profile中都支持。
CAVLC的编码过程如下:
-
计算非零系数(TotalCoeffs)和拖尾系数(TrailingOnes)的数目。
拖尾系数指值为 +1/-1的系数,最大数目为 3。如果超过 3个,那么只有最后三个被视为拖尾系数。拖尾系数的数目被赋值到变量 TrailingOnes。
非零系数包括所有的拖尾系数,其数目被赋值到变量 TotalCoeffs)。 -
计算nC(numberCurrent,当前块值)。
nC值由左边块的非零系数 nA和上面块非零系数 nB来确定,计算公式为: nC=round((nA+nB)/2);若 nA存在 nB不存在,则 nC=nA;若 nA不存在而 nB存在,则 nC=nB;若 nA和 nB都不存在,则 nC=0。
nC值用于选择 VLC编码表,如下图所示。这里体现了上下文相关 (contextadaptive)的特性,例如当 nC值较小即周围块的非零系数较少时,就会选择比较短的码,从而实现了数据压缩。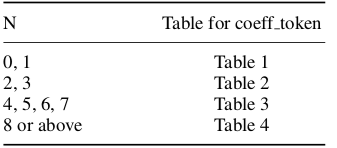
-
查表获得coff_token的编码。
根据之前编码和计算过程所得的变量 TotalCoeffs 、 TrailingOnes 和 nC 值可以查 H.264 标准附录 CAVLC 码表,即可得出 coeff_token 编码序列。
-
编码每个拖尾系数的符号,按zig-zag的逆序进行编码。
每个符号用 1个 bit位来表示, 0表示“ +”, 1表示“—”。
当拖尾系数超过三个时只有最后三个被认定为拖尾系数,引词编码顺序为从后向前编码。 -
编码除拖尾系数之外非零系数的level(Levels)。
每个非零系数的 level包括 sign和 magnitude,扫描顺序是逆 zig-zag序。
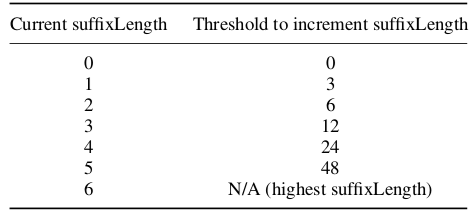
level的编码由前缀 (level_prefix)和后缀 (level_suffix)组成。前缀的长度在 0到 6之间,后缀的长度则可通过下面的步骤来确定:
将后缀初始化为 0。(若非零系数的总数超过 10且拖尾系数不到 3,则初始化为 1)。
编码频率最高(即按扫描序最后)的除拖尾系数之外的非零系数。
若这个系数的 magnitude 超过某个门槛值 (threshold) ,则增加后缀的长度。下表是门槛值的列表:
-
编码最后一个非零系数之前0的个数(totalZeos)。
TotalZeros 指的是在最后一个非零系数前零的数目,此非零系数指的是按照正向扫描的最后一个非零系数
根据 TotalCoeffs 值, H.264 标准共提供了 25 个变长表格供查找,其中编码亮度数据时有 15 个表格供查找,编码色度 DC2 × 2 块( 4 : 2:0 格式)有 3 个表格、编码色度 DC2 × 4 块( 4 : 2:2 格式)有 7 个表格。 -
编码每个系数前面0的数目(run_before)。
扫描顺序为 zig-zag 的逆序。
若 ∑ [run_before]== total_zeros ,则不需再计算run_before
扫描序中的最后一个元素不需要计算 run_before
每个 run_before 的 VLC 编码取决于 run_before 自身及未编码的 0 的个数 ZerosLeft 。例如若 ZerosLeft== 2 ,那么 run_before 只可能是 0,1 或 2 ,因此使用两个 bit 即可表示。
CAVLC之手把手教你编码
转自:http://blog.csdn.net/sunshine1314/article/details/1685948
这篇博客使用实例对上述过程做了详细的说明,尤其是有关Levels的计算方面做了重要的补充。下面是全文的转载:
首先声明本文并不是我写的,文章来自本人同学(Sunrise),都是一起做的H264,比较了解,文章内容都是自己整理的,比较可信,因此整理到一起,我也偷个懒哈
再次声明:文中用的标准是BS的正式标准,如果大家发现序号不对,参考着改过来就是了!
编码过程:
假设有一个4*4数据块
{
0,3,-1,0,
0,-1,1,0,
1,0,0,0,
0,0,0,0
}
数据重排列:0,3,0,1,-1,-1,0,1,0……
1)初始值设定:
非零系数的数目(TotalCoeffs)=5;
拖尾系数的数目(TrailingOnes)=3;
最后一个非零系数前零的数目(Total_zeros)=3;
变量NC=1;
(说明:NC值的确定:色度的直流系数NC=-1;其他系数类型NC值是根据当前块左边4*4块的非零系数数目(NA)当前块上面4*4块的非零系数数目(NB)求得的,见毕厚杰书P120表6.10)
suffixLength=0;
i=TotalCoeffs=5;
2)编码coeff_token:
查标准(BSISO/IEC14496-10:2003)Table9-5,可得:
If(TotalCoeffs==5&&TrailingOnes==3&&0<=NC<2)
coeff_token=0000100;
Code=0000100;
3)编码所有TrailingOnes的符号:
逆序编码,三个拖尾系数的符号依次是+(0),-(1),-(1);
即:
TrailingOnesign[i--]=0;
TrailingOnesign[i--]=1;
TrailingOnesign[i--]=1;
Code=0000100011;
4)编码除了拖尾系数以外非零系数幅值Levels:
过程如下:
(1)将有符号的Level[i]转换成无符号的levelCode;
如果Level[i]是正的,levelCode=(Level[i]<<1)–2;
如果Level[i]是负的,levelCode=-(Level[i]<<1)–1;
(2)计算level_prefix:level_prefix=levelCode/(1<<suffixLength);
查表9-6可得所对应的bitstring;
(3)计算level_suffix:level_suffix=levelCode%(1<<suffixLength);
(4)根据suffixLength的值来确定后缀的长度;
(5)suffixLengthupdata:
If(suffixLength==0)
suffixLength++;
elseif(levelCode>(3<<suffixLength-1)&&suffixLength<6)
suffixLength++;
回到例子中,依然按照逆序,Level[i--]=1;(此时i=1)
levelCode=0;level_prefix=0;
查表9-6,可得level_prefix=0时对应的bitstring=1;
因为suffixLength初始化为0,故该Level没有后缀;
因为suffixLength=0,故suffixLength++;
Code=00001000111;
编码下一个Level:Level[0]=3;
levelCode=4;level_prefix=2;查表得bitstring=001;
level_suffix=0;suffixLength=1;故码流为0010;
Code=000010001110010;
i=0,编码Level结束。
5)编码最后一个非零系数前零的数目(TotalZeros):
查表9-7,当TotalCoeffs=5,total_zero=3时,bitstring=111;
Code=000010001110010111;
6)对每个非零系数前零的个数(RunBefore)进行编码:
i=TotalCoeffs=5;ZerosLeft=Total_zeros=3;查表9-10:
依然按照逆序编码
ZerosLeft=3,run_before=1run_before[4]=10;
ZerosLeft=2,run_before=0run_before[3]=1;
ZerosLeft=2,run_before=0run_before[2]=1;
ZerosLeft=2,run_before=1run_before[1]=01;
ZerosLeft=1,run_before=1run_before[0]不需要码流来表示
Code=000010001110010111101101;
编码完毕。
CABAC
简介
CABAC(ContextAdaptive Binary Arithmatic Coding)也是H.264/MPEG-4AVC中使用的熵编码算法。CABAC在不同的上下文环境中使用不同的概率模型来编码。其编码过程大致是这样:首先,将欲编码的符号用二进制bit表示;然后对于每个bit,编码器选择一个合适的概率模型,并通过相邻元素的信息来优化这个概率模型;最后,使用算术编码压缩数据。
CABAC编码详情
CABAC编码之所以能取得很高的压缩比,是因为:a)根据每一个语法元素的上下文来选取预测模型;b)使用本地的统计数据来估计概率;c)使用算术编码而不是变长编码。编码一个符号需要经过下面几步:
-
二值化。CABAC使用的算术编码是基于二进制的算术编码,因此非二进制形式的编码首先要转化为二进制的形式表示。
下面的2、3、4步
-
选择上下文模型。“上下文模型”是指对二值化后的符号中的bit位进行编码时使用的概率模型。概率模型与最近编码的符号相关,会有多个概率模型可供选择。
-
算术编码。算术编码器根据第2步选择的概率模型对每个bit进行编码。需要注意的是每个bit的子范围只有两个数:0和1。
-
更新预测模型。根据实际编码的值来更新所选择的预测模型。例如,如果所编码的二进制bit为1,则预测模型中的1计数要增加。
编码过程
下面将以mxdx为例解释编码过程,mxdx是motionvector difference in the x-direction的简写,通过宏块的子块之间运算获得。
-
二值化。对于|mvdx|<9的数,使用下表进行编码,超过9的数使用Exp-Golomb编码。在这里,我们称编码后的第一个bit为bin1,第二个bit为bin2,以此推之,可以得到bin3,bin4等。

-
为每个bin选择一个上下文模型。bin1可以在三个模型之间进行选择,选择的依据是相邻的两个mxdx的绝对值之和,ek:
ek = mxdxA+ mxdxB(A和B分别是当前块的上方块和左边块)
根据ek值从下表中为bin1选择上下文模型:
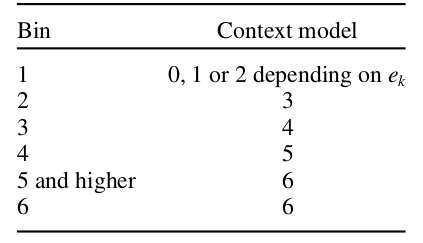
除bin1之外的其它bit的上下文模型的选择根据下表进行:
-
编码每个bin。所选的预测模型中有0和1的概率,从而为算术编码器提供了概率范围,算术编码器使用这个概率范围对此bin进行算术编码。
-
更新上下文模型。例如,若bin1使用上下文模型2,而bin1的值是1,那么上下文模型2中1的计数就要增加,1的概率和0的概率需要重新计算。当上下文模型中的总数超过门槛值后,0和1的计数就要除以某个值,从而使得新加入的0和1在模型中产生更大的影响。