memcached(八)一致性哈希高级应用
简介
一致性哈希算法在1997年由麻省理工学院提出(参见扩展阅读[1]),设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得DHT可以在P2P环境中真正得到应用。
英文解释
Consistent hashing is a scheme that provides hash table functionality in a way that the addition or removal of one slot does not significantly change the mapping of keys to slots.
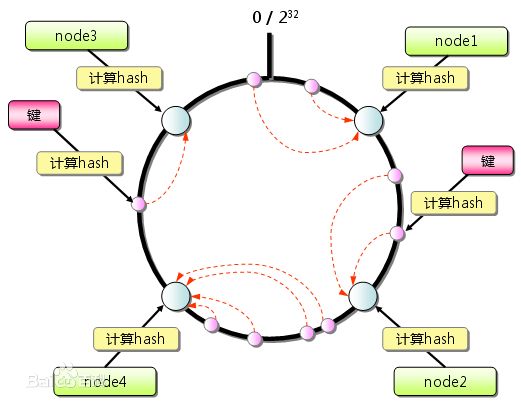
哈希算法
一致性哈希提出了在动态变化的Cache环境中,哈希算法应该满足的4个适应条件:
平衡性(Balance)
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
单调性(Monotonicity)
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲区加入到系统中,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲区中去,而不会被映射到旧的缓冲集合中的其他缓冲区。(这段翻译信息有负面价值的,当缓冲区大小变化时Consistent hashing尽量保护已分配的内容不会被重新映射到新缓冲区。)
简单的哈希算法往往不能满足单调性的要求,如最简单的线性哈希:
x → ax + b mod (P)
在上式中,P表示全部缓冲的大小。不难看出,当缓冲大小发生变化时(从P1到P2),原来所有的哈希结果均会发生变化,从而不满足单调性的要求。
哈希结果的变化意味着当缓冲空间发生变化时,所有的映射关系需要在系统内全部更新。而在P2P系统内,缓冲的变化等价于Peer加入或退出系统,这一情况在P2P系统中会频繁发生,因此会带来极大计算和传输负荷。单调性就是要求哈希算法能够应对这种情况。
分散性(Spread)
在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
负载(Load)
负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
结论
一致性哈希基本解决了在P2P环境中最为关键的问题——如何在动态的网络拓扑中分布存储和路由。每个节点仅需维护少量相邻节点的信息,并且在节点加入/退出系统时,仅有相关的少量节点参与到拓扑的维护中。所有这一切使得一致性哈希成为第一个实用的DHT算法。
但是一致性哈希的路由算法尚有不足之处。在查询过程中,查询消息要经过O(N)步(O(N)表示与N成正比关系,N代表系统内的节点总数)才能到达被查询的节点。不难想象,当系统规模非常大时,节点数量可能超过百万,这样的查询效率显然难以满足使用的需要。换个角度来看,即使用户能够忍受漫长的时延,查询过程中产生的大量消息也会给网络带来不必要的负荷。
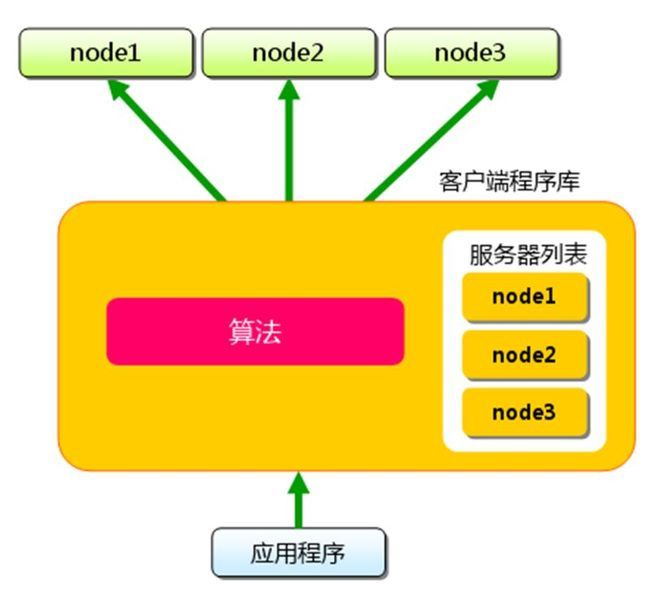
memcache的客户端分布式
memcached的客户端分布式采用了一致性哈希算法,流程如下:
xmemcached的Ketama源码解析
初始化
net.rubyeye.xmemcached.impl.KetamaMemcachedSessionLocator的细节
动态改变被监听服务器
Xmemcached支持动态的增加或者删除监听服务器,方式如下:
客户端配置
结合zookeeper,可以将一致性哈希表放到zookeeper中。当节点发生变化,人工干预比较妨那改变,调用public final void updateSessions(final Collection<Session> list) 接口即可。其中ZooKeeper客户端推荐使用apache-curator,因为:
其中根据个人经验,ZooKeeper监听配置文件,原生客户端只监听一次,触发事件之后,监听器即被移除。这是个陷阱,而curator很好的解决了诸如此类的问题。
一致性哈希算法在1997年由麻省理工学院提出(参见扩展阅读[1]),设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得DHT可以在P2P环境中真正得到应用。
英文解释
Consistent hashing is a scheme that provides hash table functionality in a way that the addition or removal of one slot does not significantly change the mapping of keys to slots.
哈希算法
一致性哈希提出了在动态变化的Cache环境中,哈希算法应该满足的4个适应条件:
平衡性(Balance)
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
单调性(Monotonicity)
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲区加入到系统中,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲区中去,而不会被映射到旧的缓冲集合中的其他缓冲区。(这段翻译信息有负面价值的,当缓冲区大小变化时Consistent hashing尽量保护已分配的内容不会被重新映射到新缓冲区。)
简单的哈希算法往往不能满足单调性的要求,如最简单的线性哈希:
x → ax + b mod (P)
在上式中,P表示全部缓冲的大小。不难看出,当缓冲大小发生变化时(从P1到P2),原来所有的哈希结果均会发生变化,从而不满足单调性的要求。
哈希结果的变化意味着当缓冲空间发生变化时,所有的映射关系需要在系统内全部更新。而在P2P系统内,缓冲的变化等价于Peer加入或退出系统,这一情况在P2P系统中会频繁发生,因此会带来极大计算和传输负荷。单调性就是要求哈希算法能够应对这种情况。
分散性(Spread)
在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
负载(Load)
负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
结论
一致性哈希基本解决了在P2P环境中最为关键的问题——如何在动态的网络拓扑中分布存储和路由。每个节点仅需维护少量相邻节点的信息,并且在节点加入/退出系统时,仅有相关的少量节点参与到拓扑的维护中。所有这一切使得一致性哈希成为第一个实用的DHT算法。
但是一致性哈希的路由算法尚有不足之处。在查询过程中,查询消息要经过O(N)步(O(N)表示与N成正比关系,N代表系统内的节点总数)才能到达被查询的节点。不难想象,当系统规模非常大时,节点数量可能超过百万,这样的查询效率显然难以满足使用的需要。换个角度来看,即使用户能够忍受漫长的时延,查询过程中产生的大量消息也会给网络带来不必要的负荷。
memcache的客户端分布式
memcached的客户端分布式采用了一致性哈希算法,流程如下:
xmemcached的Ketama源码解析
初始化
MemcachedClientBuilder builder = new XMemcachedClientBuilder(AddrUtil.getAddressMap("......"));
builder.setSessionLocator(new KetamaMemcachedSessionLocator());
net.rubyeye.xmemcached.impl.KetamaMemcachedSessionLocator的细节
/** *Copyright [2009-2010] [dennis zhuang([email protected])] *Licensed under the Apache License, Version 2.0 (the "License"); *you may not use this file except in compliance with the License. *You may obtain a copy of the License at * http://www.apache.org/licenses/LICENSE-2.0 *Unless required by applicable law or agreed to in writing, *software distributed under the License is distributed on an "AS IS" BASIS, *WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, *either express or implied. See the License for the specific language governing permissions and limitations under the License */ package net.rubyeye.xmemcached.impl; import java.net.InetSocketAddress; import java.util.ArrayList; import java.util.Collection; import java.util.List; import java.util.Random; import java.util.SortedMap; import java.util.TreeMap; import net.rubyeye.xmemcached.HashAlgorithm; import net.rubyeye.xmemcached.networking.MemcachedSession; import com.google.code.yanf4j.core.Session; /** * ConnectionFactory instance that sets up a ketama compatible connection. * * <p> * This implementation piggy-backs on the functionality of the * <code>DefaultConnectionFactory</code> in terms of connections and queue * handling. Where it differs is that it uses both the <code> * KetamaNodeLocator</code> * and the <code>HashAlgorithm.KETAMA_HASH</code> to provide consistent node * hashing. * * @see http://www.last.fm/user/RJ/journal/2007/04/10/392555/ * * </p> */ /** * Consistent Hash Algorithm implementation,based on TreeMap.tailMap(hash) * method. * * @author dennis * */ public class KetamaMemcachedSessionLocator extends AbstractMemcachedSessionLocator { static final int NUM_REPS = 160; private transient volatile TreeMap<Long, List<Session>> ketamaSessions = new TreeMap<Long, List<Session>>(); private final HashAlgorithm hashAlg; private volatile int maxTries; private final Random random = new Random(); /** * compatible with nginx-upstream-consistent,patched by wolfg1969 */ static final int DEFAULT_PORT = 11211; private final boolean cwNginxUpstreamConsistent; public KetamaMemcachedSessionLocator() { this.hashAlg = HashAlgorithm.KETAMA_HASH; this.cwNginxUpstreamConsistent = false; } public KetamaMemcachedSessionLocator(boolean cwNginxUpstreamConsistent) { this.hashAlg = HashAlgorithm.KETAMA_HASH; this.cwNginxUpstreamConsistent = cwNginxUpstreamConsistent; } public KetamaMemcachedSessionLocator(HashAlgorithm alg) { this.hashAlg = alg; this.cwNginxUpstreamConsistent = false; } public KetamaMemcachedSessionLocator(HashAlgorithm alg, boolean cwNginxUpstreamConsistent) { this.hashAlg = alg; this.cwNginxUpstreamConsistent = cwNginxUpstreamConsistent; } public KetamaMemcachedSessionLocator(List<Session> list, HashAlgorithm alg) { super(); this.hashAlg = alg; this.cwNginxUpstreamConsistent = false; this.buildMap(list, alg); } /** 构建hash table的方法 list 基于IP的memcached列表 alg 使用的算法 */ private final void buildMap(Collection<Session> list, HashAlgorithm alg) { TreeMap<Long, List<Session>> sessionMap = new TreeMap<Long, List<Session>>(); for (Session session : list) { //变量中,保存的是IP和端口拼接的字符串,/10.10.160.153:11211 String sockStr = null; if (this.cwNginxUpstreamConsistent) { InetSocketAddress serverAddress = session .getRemoteSocketAddress(); sockStr = serverAddress.getAddress().getHostAddress(); if (serverAddress.getPort() != DEFAULT_PORT) { sockStr = sockStr + ":" + serverAddress.getPort(); } } else { if (session instanceof MemcachedTCPSession) { // Always use the first time resolved address. sockStr = ((MemcachedTCPSession) session) .getInetSocketAddressWrapper() .getRemoteAddressStr(); } if (sockStr == null) { sockStr = String.valueOf(session.getRemoteSocketAddress()); } } /** * Duplicate 160 X weight references */ int numReps = NUM_REPS; if (session instanceof MemcachedTCPSession) { numReps *= ((MemcachedSession) session).getWeight(); } if (alg == HashAlgorithm.KETAMA_HASH) { //此处表示将1个节点,复制成160个虚拟节点 //numReps / 4,是因为每次md5运算,有128位,即:16字节 //虽然最后转换成了long类型,但是他的取值范围不是long的最大值(8字节),而是int的最大值(4字节)-2^32至2^32 for (int i = 0; i < numReps / 4; i++) { byte[] digest = HashAlgorithm.computeMd5(sockStr + "-" + i); for (int h = 0; h < 4; h++) { long k = (long) (digest[3 + h * 4] & 0xFF) << 24 | (long) (digest[2 + h * 4] & 0xFF) << 16 | (long) (digest[1 + h * 4] & 0xFF) << 8 | digest[h * 4] & 0xFF; this.getSessionList(sessionMap, k).add(session); } } } else { for (int i = 0; i < numReps; i++) { long key = alg.hash(sockStr + "-" + i); this.getSessionList(sessionMap, key).add(session); } } } this.ketamaSessions = sessionMap; this.maxTries = list.size(); } private List<Session> getSessionList( TreeMap<Long, List<Session>> sessionMap, long k) { List<Session> sessionList = sessionMap.get(k); if (sessionList == null) { sessionList = new ArrayList<Session>(); sessionMap.put(k, sessionList); } return sessionList; } /** 根据缓存的key,查找存储节点 */ public final Session getSessionByKey(final String key) { if (this.ketamaSessions == null || this.ketamaSessions.size() == 0) { return null; } long hash = this.hashAlg.hash(key); Session rv = this.getSessionByHash(hash); int tries = 0; //检查Session是否可用,如果不可用,则跳过此节点,返回下一个临近节点 while (!this.failureMode && (rv == null || rv.isClosed()) && tries++ < this.maxTries) { hash = this.nextHash(hash, key, tries); rv = this.getSessionByHash(hash); } return rv; } /** 根据缓存的key计算出的hash值,取出对应的Session */ public final Session getSessionByHash(final long hash) { TreeMap<Long, List<Session>> sessionMap = this.ketamaSessions; if (sessionMap.size() == 0) { return null; } Long resultHash = hash; if (!sessionMap.containsKey(hash)) { // Java 1.6 adds a ceilingKey method, but xmemcached is compatible // with jdk5,So use tailMap method to do this. //取出TreeMap中,索引大于等于hash的map值,结果是排序的 SortedMap<Long, List<Session>> tailMap = sessionMap.tailMap(hash); if (tailMap.isEmpty()) { resultHash = sessionMap.firstKey(); } else { resultHash = tailMap.firstKey(); } } // // if (!sessionMap.containsKey(resultHash)) { // resultHash = sessionMap.ceilingKey(resultHash); // if (resultHash == null && sessionMap.size() > 0) { // resultHash = sessionMap.firstKey(); // } // } List<Session> sessionList = sessionMap.get(resultHash); if (sessionList == null || sessionList.size() == 0) { return null; } int size = sessionList.size(); return sessionList.get(this.random.nextInt(size)); } public final long nextHash(long hashVal, String key, int tries) { long tmpKey = this.hashAlg.hash(tries + key); hashVal += (int) (tmpKey ^ tmpKey >>> 32); hashVal &= 0xffffffffL; /* truncate to 32-bits */ return hashVal; } public final void updateSessions(final Collection<Session> list) { this.buildMap(list, this.hashAlg); } }
动态改变被监听服务器
Xmemcached支持动态的增加或者删除监听服务器,方式如下:
MemcachedClient client=new XMemcachedClient(AddrUtil.getAddresses("server1:11211 server2:11211"));
//Add two new memcached nodes
client.addServer("server3:11211 server4:11211");
//Remove memcached servers
client.removeServer("server1:11211 server2:11211");
客户端配置
结合zookeeper,可以将一致性哈希表放到zookeeper中。当节点发生变化,人工干预比较妨那改变,调用public final void updateSessions(final Collection<Session> list) 接口即可。其中ZooKeeper客户端推荐使用apache-curator,因为:
- 封装ZooKeeper client与ZooKeeper server之间的连接处理;
- 提供了一套Fluent风格的操作API;
- 提供ZooKeeper各种应用场景(recipe, 比如共享锁服务, 集群领导选举机制)的抽象封装。
其中根据个人经验,ZooKeeper监听配置文件,原生客户端只监听一次,触发事件之后,监听器即被移除。这是个陷阱,而curator很好的解决了诸如此类的问题。