先说一说这一篇用到的多线程等待函数:如下
WaitForMultipleObjects(
DWORD nCount,
CONST HANDLE *lpHandles,
BOOL bWaitAll,
DWORD dwMilliseconds
);
nCount 表示我们希望函数检查的内核对象的数量。这个值必须在1~ MAXIMUM_WAIT_OBJECTS(64)之间。
lpHandles 是一个指针,指向一个内核对象句柄的数组。
我们可以通过两种方式来使用WaitForMultipleObjects,一种是让线程进入等待状态直到指定内核对象中的一个被触发位置,另一种是让线程进入等待状态直到指定内核对象中的全部被触发为止。
bWaitAll 如果给这个参数传递TRUE,那么在所有内核对象被触发之前,函数将不会允许调用线程继续执行。
dwMilliseconds的用法与waiforsingleobject中完全相同。如果在等待的时候,超出了指定的时间长度,那么即使内核对象还没有被触发,函数也会返回。 我们通常传递INFINITE给这个参数,但为了避免可能出现的死锁,在编写代码的时候应该小心。
WaitForMultipleObjects函数的返回值告诉调用方函数为什么它得以继续运行。可能的返回值包括WAIT_FAILED(失败)和WAIT_TIMEOUT(超时),他们都不言自明。如果给bWaitAll传的是TRUE而且所有对象都被触发了,那么返回值是WAIT_OBJECT_0。
如果给bWaitAll传的是FALSE,那么只要任何一个对象被触发,函数就会立即返回。这时的返回值是WAIT_OBJECT_0和(WAIT_OBJECT_0+nCount -1)之间的任何一个值。即指明了被触发的是哪一个对象。
实例一:
HANDLE h[2];
h[0] = hThread1;
h[1] = hThread2;
DWORD dw = ::WaitForMultipleObjects(2, h, FALSE, 5000);
switch(dw)
{ case WAIT_FAILED:
// 调用WaitForMultipleObjects函数失败(句柄无效?)
break;
case WAIT_TIMEOUT:
// 在5秒内没有一个内核对象受信
break;
case WAIT_OBJECT_0 + 0:
// 句柄h[0]对应的内核对象受信
break;
case WAIT_OBJECT_0 + 1:
// 句柄h[1]对应的内核对象受信
break;
}
参数bWaitAll为FALSE的时候,WaitForMultipleObjects函数从索引0开始扫描整个句柄数组,第一个受信的内核对象将终止函数的等待,使函数返回。
实例二:
for(int i=0;i<6;i++)
{
for(int j=0;j<10;j++)
{
theport[j].rmt_host=rmt_host;
theport[j].p=port[i*10+j];
theport[j].n=j;
Thread[j]=AfxBeginThread(pScan,(LPVOID)&theport[j]);
hThread[j]=Thread[j]->m_hThread;
Sleep(1);
}
WaitForMultipleObjects(10,hThread,TRUE,120000);
}
注:线程退出后,即线程对象计数值变为0后,线程才会变为受信状态。
在多线程状态下时,如果传递的是值的拷贝,是不会有问题的,如下:
#include <windows.h>
#include <process.h>
#include <iostream>
using namespace std;
const int THREADNUM = 10;
unsigned int __stdcall threadFunc(PVOID pM) {
Sleep(100);
cout << ((int )pM) << endl;
return 0;
}
int main() {
HANDLE handle[THREADNUM];
for(int i=0; i< THREADNUM; i++) {
handle[i] = (HANDLE)_beginthreadex(NULL, 0, threadFunc, (PVOID) i, 0, NULL);
}
WaitForMultipleObjects(THREADNUM, handle, TRUE ,INFINITE);
getchar();
return 0;
}
输出结果为:
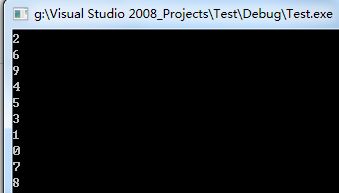
如果传递的是地址,则在计数方面会有不安全的问题出现。
#include <windows.h>
#include <process.h>
#include <iostream>
using namespace std;
const int THREADNUM = 10;
unsigned int __stdcall threadFunc(PVOID pM) {
Sleep(100);
cout << *((int* )pM) << endl;
return 0;
}
int main() {
HANDLE handle[THREADNUM];
for(int i=0; i< THREADNUM; i++) {
handle[i] = (HANDLE)_beginthreadex(NULL, 0, threadFunc, (PVOID) &i, 0, NULL);
}
WaitForMultipleObjects(THREADNUM, handle, TRUE ,INFINITE);
getchar();
return 0;
}
输出结果为:

由于输出 换行不在临界区, 所以线程并发时,会有同一行的输出出现。
二、 如下代码进行线程个数的统计
#include <windows.h>
#include <process.h>
#include <iostream>
using namespace std;
const int THREADNUM = 50;
int number = 0;
unsigned int __stdcall threadFunc(PVOID pM) {
Sleep(100);
number++;
Sleep(50);
return 0;
}
int main() {
int num = 20;
HANDLE handle[THREADNUM];
while(num--) {
number = 0;
for(int i=0; i< THREADNUM; i++) {
handle[i] = (HANDLE)_beginthreadex(NULL, 0, threadFunc, NULL, 0, NULL);
}
WaitForMultipleObjects(THREADNUM, handle, TRUE ,INFINITE);
cout << "计数个数为" << number << endl;
}
getchar();
return 0;
}
输出结果为:

现在结果水落石出,明明有50个线程执行了g_nLoginCount++;操作,但结果输出是不确定的,有可能为50,但也有可能小于50。
要解决这个问题,我们就分析下g_nLoginCount++;操作。在VC6.0编译器对g_nLoginCount++;这一语句打个断点,再按F5进入调试状态,然后按下Debug工具栏的Disassembly按钮,这样就出现了汇编代码窗口。可以发现在C/C++语言中一条简单的自增语句其实是由三条汇编代码组成的,如下图所示。
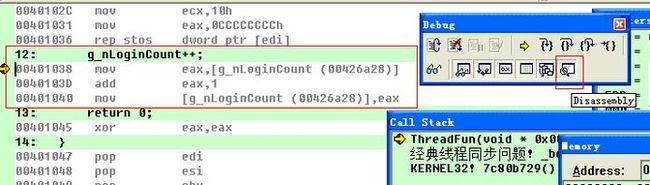
这三条汇编的意思分别为:
第一条汇编将g_nLoginCount的值从内存中读取到寄存器eax中。
第二条汇编将寄存器eax中的值与1相加,计算结果仍存入寄存器eax中。
第三条汇编将寄存器eax中的值写回内存中。
这样由于线程执行的并发性,很可能线程A执行到第二句时,线程B开始执行,线程B将原来的值又写入寄存器eax中,这样线程A所主要计算的值就被线程B修改了。这样执行下来,结果是不可预知的——可能会出现50,可能小于50。
因此在多线程环境中对一个变量进行读写时,我们需要有一种方法能够保证对一个值的递增操作是原子操作——即不可打断性,一个线程在执行原子操作时,其它线程必须等待它完成之后才能开始执行该原子操作。这种涉及到硬件的操作会不会很复杂了,幸运的是,Windows系统为我们提供了一些以Interlocked开头的函数来完成这一任务(下文将这些函数称为Interlocked系列函数)。
下面列出一些常用的Interlocked系列函数:
1.增减操作
LONG__cdeclInterlockedIncrement(LONG volatile* Addend);
LONG__cdeclInterlockedDecrement(LONG volatile* Addend);
返回变量执行增减操作之后的值。
LONG__cdec InterlockedExchangeAdd(LONG volatile* Addend, LONGValue);
返回运算后的值,注意!加个负数就是减。
2.赋值操作
LONG__cdeclInterlockedExchange(LONG volatile* Target, LONGValue);
Value就是新值,函数会返回原先的值。
在本例中只要使用InterlockedIncrement()函数就可以了。将线程函数代码改成:
#include <windows.h>
#include <process.h>
#include <iostream>
using namespace std;
const int THREADNUM = 50;
volatile long number = 0;
unsigned int __stdcall threadFunc(PVOID pM) {
Sleep(100);
InterlockedIncrement(&number);
Sleep(50);
return 0;
}
int main() {
int num = 20;
HANDLE handle[THREADNUM];
while(num--) {
number = 0;
for(int i=0; i< THREADNUM; i++) {
handle[i] = (HANDLE)_beginthreadex(NULL, 0, threadFunc, NULL, 0, NULL);
}
WaitForMultipleObjects(THREADNUM, handle, TRUE ,INFINITE);
cout << "计数个数为" << number << endl;
}
getchar();
return 0;
}
输出结果为:

因此,在多线程环境下,我们对变量的自增自减这些简单的语句也要慎重思考,防止多个线程导致的数据访问出错。
但是当线程数达到70~100时,会有不稳定的情况出现,
当为70时,运行截图如下:
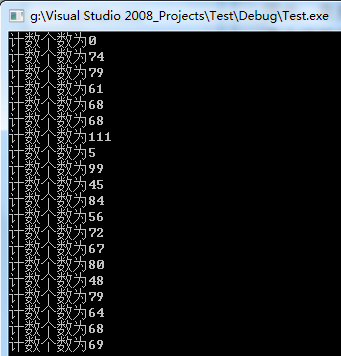
具体原因在 下一篇文章中解释。
参见http://xiabin1235910-qq-com.iteye.com/admin/blogs/1968781