Feed4Junit官方地址:
http://databene.org/feed4junit.html
官方文档:
Special CSV and Excel(TM) Sheet Features
Feed4JUnit supports the import of CSV files and Excel(TM) Sheets, formulas in Excel Sheets are resolved. In the following chapters, the term data file represents CSV files as well as Excel files.
Data file per method
When annotating a test method with a @Source that refers to a data file, each column is mapped to a method parameter sequentially, independent of the column name and the parameter name:
| @Test |
The corresponding data file is expected to have a header row and an arbitrary number of rows. Each row represents one data set with which the test method is called. If the file users.ent.csv has the following content:
| name,age Alice,23 Bob,34 |
the test method is called twice: First with the parameters (Alice, 23), then with the parameters (Bob, 34).
CSV format
Feed4JUnit supports CSV as specified in RFC 4180. Thus, cells may be double-quoted, e.g. to include the separator character as plain character. As an example, the line
Alice,"Alice","Bob,Charly"
is parsed into a data set of three string values, which the first two entries contain the string Alice and the third one the string Bob,Charly. Note that each one is provided without quotes.
For differing between empty strings and null values, empty double quotes are mapped to a string, an empty cell is mapped to a null value:
Alice,,""
is mapped to a data set of three values, the first one is the string Alice, the second one null, the third one an empty string.
Excel(TM) format
Excel sheets are imported using the Apache POI library which provides any numerical value as a floating point value. So be prepared that some fractional numbers are not parsed exactly as you expect them to be.
Empty cells are mapped to null values, The default notation for an empty string in Excel is one single-quote character in a cell. Unfortunately this is not displayed in the sheet view, so the user needs to enter each cell in order to tell if its value represents null or an empty string. If the difference between null and empty strings matters for you, Excel sheets would become much more intuitive if each visually empty cell is indeed empty and mapped to a null value and each cell that represents an empty string, displays a marker text. This approach can be used by Feed4JUnit's emptyMarker.
The user can chose a custom marker text to represent empty strings, e.g. <empty>, and use it in an Excel sheet:
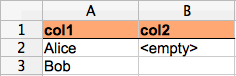
Then the emptyMarker needs to be declared in Feed4JUnit's @Source annotation:
| @Test |
Finally, when running the tests, the values which match the emptyMarker are replaced with empty strings. The example yields the data sets:
1. Alice and an empty string
2. Bob an a null value
Column-based data
For tests with extraordinarily long parameter lists and few test cases to execute, a column-based data format might be more convenient for the user. In this case, the first column is expected to be the header column and each further column represents a parameter set for a test method invocation. The data of the example above would be represented like this:
| name,Alice,Bob age,23,34 |
and the @Source annotation needs a flag rowBased = false:
| @Test @Source(uri = "user-columns.ent.csv", rowBased = false) public void testMethodColumnSource(String name, int age) { ... } |
JavaBean parameters
Data for a JavaBean parameter can be read from a data file. Suppose you have a JavaBean class Country with default constructor and the properties 'isoCode' and 'name':
| public class Country { private String isoCode; private String name; public String getIsoCode() { return isoCode; } public void setIsoCode(String isoCode) { this.isoCode = isoCode; } public String getName() { return name; } public void setName(String name) { this.name = name; } } |
Then you can annotate a method's JavaBean-type-parameter with a @Source annotation that points to the file:
| @Test public void testCsvBean(@Source("countries.ent.csv") Country country) { ... } |
In this case, the column names of the data file matter and are mapped to the bean's properties of same name.
| isoCode,name |
Reading JavaBean graphs from a data file
Bean graphs can also be imported from a single data file. Suppose you have a 'User' JavaBean which references the 'Country' JavaBean:
| public class User { private String name; private int age; private Country country; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public Country getCountry() { return country; } public void setCountry(Country country) { this.country = country; } } |
Feed4JUnit recognizes that the User's 'country' property is a JavaBean and when importing file data for a User
| @Test public void testCsvNestedBean(@Source("users2.ent.csv") User user) { ... } |
it maps the data appropriately based on recursive property naming:
| name,age,country.isoCode,country.name Alice,23,DE,Germany Bob,34,US,USA |
Locating data files
Feed4JUnit uses the following default strategy for looking up file names specified in a @Source annotation's uri:
- absolute (if it is an absolute path like C:\tests\my.csv or /tests/my.csv)
- class path
- relative to the working directory
For alternative lookup strategies, a service provider interface is supported: org.databene.benerator.anno.PathResolver.
By default, Feed4JUnit uses the org.databene.benerator.anno.DefaultPathResolver which employs the behaviour described above.
An alternative strategy is provided by org.databene.benerator.anno.RelativePathResolver: It uses a configurable base path, adds the package name of the test to run (as path components) and finally adds the resource path specified as URI. So, when using a base path C:\tests, an annotation @Source("p1/user.ent.csv") used in test class com.my.UserTests is mapped to the file path C:\tests\com\my\p1\user.ent.csv.
If you need alternative strategies, you can write a custom implementation of the PathResolver interface.
For choosing a specific path resolver, put a file feed4junit.properties into your project (or working) directory and specify a pathResolver:
| pathResolver=new org.databene.benerator.anno.RelativePathResolver('C:\\test') |
The example shows how to configure the RelativePathResolver using the base path C:\test.
The pathResover expression is interpreted using DatabeneScript which supports most Java expression types. A main difference is, that strings literals use single quotes as shown in the example. Also note that string values are interpreted Java-like, so the Windows path separator \ is represented by its Java escape character.Â
package com.easyway.feed4junit;
public class Country {
private String isoCode;
private String name;
public String getIsoCode() {
return isoCode;
}
public void setIsoCode(String isoCode) {
this.isoCode = isoCode;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
package com.easyway.feed4junit;
public class User {
private String name;
private int age;
private Country country;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Country getCountry() {
return country;
}
public void setCountry(Country country) {
this.country = country;
}
}
package com.easyway.feed4junit;
import org.databene.benerator.anno.Source;
import org.databene.feed4junit.Feeder;
import org.junit.Test;
import org.junit.runner.RunWith;
@RunWith(Feeder.class)
public class F4JreadComplexJavaBean {
@Test
public void testCsvNestedBean(@Source("complex-data.csv") User user) {
System.out.println(user.getName()+" "+user.getAge() +" "+user.getCountry().getIsoCode() +" "+user.getCountry().getName());
}
}